吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 自定义绘制ks曲线的函数
def plot_ks(y_test, y_score, positive_flag):
# 对y_test,y_score重新设置索引
y_test.index = np.arange(len(y_test))
#y_score.index = np.arange(len(y_score))
# 构建目标数据集
target_data = pd.DataFrame({'y_test':y_test, 'y_score':y_score})
# 按y_score降序排列
target_data.sort_values(by = 'y_score', ascending = False, inplace = True)
# 自定义分位点
cuts = np.arange(0.1,1,0.1)
# 计算各分位点对应的Score值
index = len(target_data.y_score)*cuts
scores = target_data.y_score.iloc[index.astype('int')]
# 根据不同的Score值,计算Sensitivity和Specificity
Sensitivity = []
Specificity = []
for score in scores:
# 正例覆盖样本数量与实际正例样本量
positive_recall = target_data.loc[(target_data.y_test == positive_flag) & (target_data.y_score>score),:].shape[0]
positive = sum(target_data.y_test == positive_flag)
# 负例覆盖样本数量与实际负例样本量
negative_recall = target_data.loc[(target_data.y_test != positive_flag) & (target_data.y_score<=score),:].shape[0]
negative = sum(target_data.y_test != positive_flag)
Sensitivity.append(positive_recall/positive)
Specificity.append(negative_recall/negative)
# 构建绘图数据
plot_data = pd.DataFrame({'cuts':cuts,'y1':1-np.array(Specificity),'y2':np.array(Sensitivity),
'ks':np.array(Sensitivity)-(1-np.array(Specificity))})
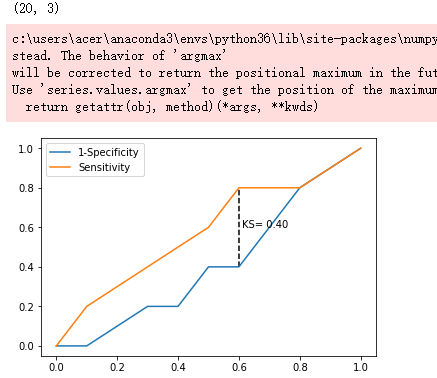
# 寻找Sensitivity和1-Specificity之差的最大值索引
max_ks_index = np.argmax(plot_data.ks)
plt.plot([0]+cuts.tolist()+[1], [0]+plot_data.y1.tolist()+[1], label = '1-Specificity')
plt.plot([0]+cuts.tolist()+[1], [0]+plot_data.y2.tolist()+[1], label = 'Sensitivity')
# 添加参考线
plt.vlines(plot_data.cuts[max_ks_index], ymin = plot_data.y1[max_ks_index],
ymax = plot_data.y2[max_ks_index], linestyles = '--')
# 添加文本信息
plt.text(x = plot_data.cuts[max_ks_index]+0.01,
y = plot_data.y1[max_ks_index]+plot_data.ks[max_ks_index]/2,
s = 'KS= %.2f' %plot_data.ks[max_ks_index])
# 显示图例
plt.legend()
# 显示图形
plt.show()
# 导入虚拟数据
virtual_data = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\09\\virtual_data.xlsx')
print(virtual_data.shape)
# 应用自定义函数绘制k-s曲线
plot_ks(y_test = virtual_data.Class, y_score = virtual_data.Score,positive_flag = 'P')
# 导入第三方模块
import pandas as pd
import numpy as np
from sklearn import linear_model,model_selection
# 读取数据
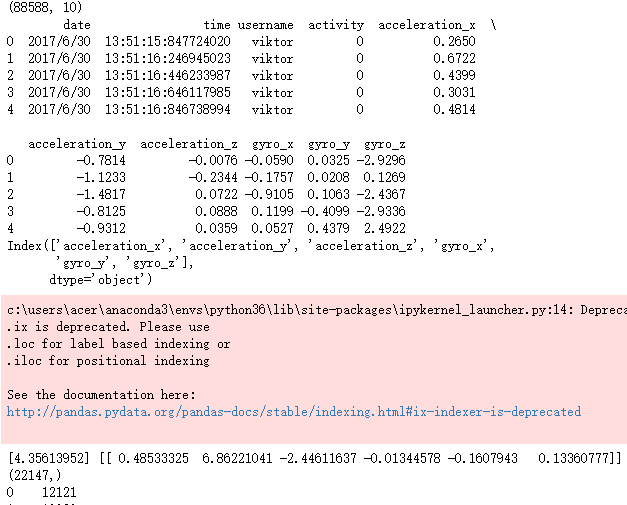
sports = pd.read_csv(r'F:\\python_Data_analysis_and_mining\\09\\Run or Walk.csv')
print(sports.shape)
print(sports.head())
# 提取出所有自变量名称
predictors = sports.columns[4:]
print(predictors)
# 构建自变量矩阵
X = sports.ix[:,predictors]
# 提取y变量值
y = sports.activity
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 1234)
# 利用训练集建模
sklearn_logistic = linear_model.LogisticRegression()
sklearn_logistic.fit(X_train, y_train)
# 返回模型的各个参数
print(sklearn_logistic.intercept_, sklearn_logistic.coef_)
# 模型预测
sklearn_predict = sklearn_logistic.predict(X_test)
print(sklearn_predict.shape)
# 预测结果统计
a = pd.Series(sklearn_predict).value_counts()
print(a)
# 导入第三方模块
from sklearn import metrics
# 混淆矩阵
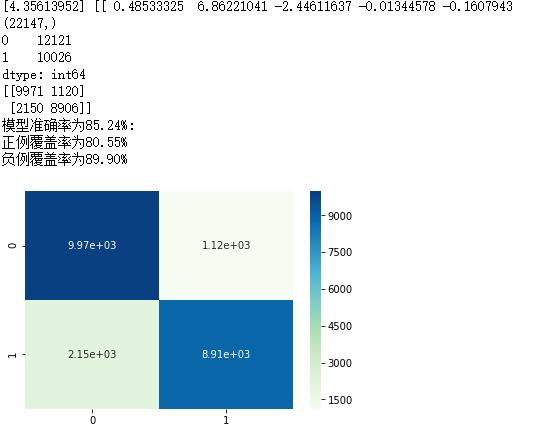
cm = metrics.confusion_matrix(y_test, sklearn_predict, labels = [0,1])
print(cm)
Accuracy = metrics.scorer.accuracy_score(y_test, sklearn_predict)
Sensitivity = metrics.scorer.recall_score(y_test, sklearn_predict)
Specificity = metrics.scorer.recall_score(y_test, sklearn_predict, pos_label=0)
print('模型准确率为%.2f%%:' %(Accuracy*100))
print('正例覆盖率为%.2f%%' %(Sensitivity*100))
print('负例覆盖率为%.2f%%' %(Specificity*100))
# 混淆矩阵的可视化
# 导入第三方模块
import seaborn as sns
import matplotlib.pyplot as plt
# 绘制热力图
sns.heatmap(cm, annot = True, fmt = '.2e',cmap = 'GnBu')
# 图形显示
plt.show()
# y得分为模型预测正例的概率
y_score = sklearn_logistic.predict_proba(X_test)[:,1]
# 计算不同阈值下,fpr和tpr的组合值,其中fpr表示1-Specificity,tpr表示Sensitivity
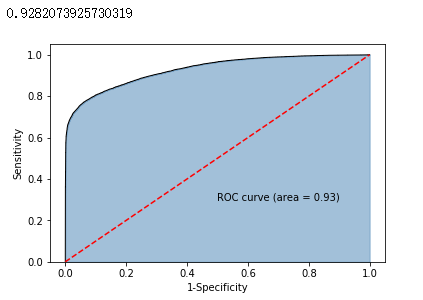
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
print(roc_auc)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
# 调用自定义函数,绘制K-S曲线
plot_ks(y_test = y_test, y_score = y_score, positive_flag = 1)

# -----------------------第一步 建模 ----------------------- #
# 导入第三方模块
import statsmodels.api as sm
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 1234)
# 为训练集和测试集的X矩阵添加常数列1
X_train2 = sm.add_constant(X_train)
X_test2 = sm.add_constant(X_test)
# 拟合Logistic模型
sm_logistic = sm.formula.Logit(y_train, X_train2).fit()
# 返回模型的参数
print(sm_logistic.params)

# -----------------------第二步 预测构建混淆矩阵 ----------------------- #
# 模型在测试集上的预测
sm_y_probability = sm_logistic.predict(X_test2)
# 根据概率值,将观测进行分类,以0.5作为阈值
sm_pred_y = np.where(sm_y_probability >= 0.5, 1, 0)
# 混淆矩阵
cm = metrics.confusion_matrix(y_test, sm_pred_y, labels = [0,1])
print(cm)

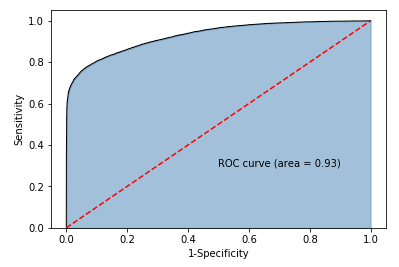
# -----------------------第三步 绘制ROC曲线 ----------------------- #
# 计算真正率和假正率
fpr,tpr,threshold = metrics.roc_curve(y_test, sm_y_probability)
# 计算auc的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
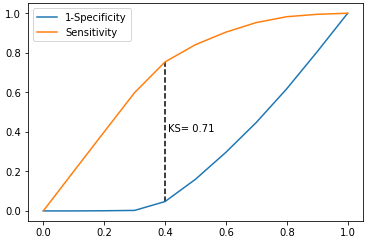
# -----------------------第四步 绘制K-S曲线 ----------------------- #
# 调用自定义函数,绘制K-S曲线
sm_y_probability.index = np.arange(len(sm_y_probability))
plot_ks(y_test = y_test, y_score = sm_y_probability, positive_flag = 1)
吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型的更多相关文章
- 吴裕雄 数据挖掘与分析案例实战(13)——GBDT模型的应用
# 导入第三方包import pandas as pdimport matplotlib.pyplot as plt # 读入数据default = pd.read_excel(r'F:\\pytho ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- 吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用
# 导入第三方包import pandas as pd # 导入数据Knowledge = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\1 ...
- 吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfr ...
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
- 吴裕雄 数据挖掘与分析案例实战(5)——python数据可视化
# 饼图的绘制# 导入第三方模块import matplotlibimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['S ...
- 吴裕雄 数据挖掘与分析案例实战(4)——python数据处理工具:Pandas
# 导入模块import pandas as pdimport numpy as np # 构造序列gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])print(g ...
- 吴裕雄 数据挖掘与分析案例实战(3)——python数值计算工具:Numpy
# 导入模块,并重命名为npimport numpy as np# 单个列表创建一维数组arr1 = np.array([3,10,8,7,34,11,28,72])print('一维数组:\n',a ...
随机推荐
- hadoop伪分布式环境搭建之linux系统安装教程
本篇文章是接上一篇<超详细hadoop虚拟机安装教程(附图文步骤)>,上一篇有人问怎么没写hadoop安装.在文章开头就已经说明了,hadoop安装会在后面写到,因为整个系列的文章涉及到每 ...
- ASP.NET 实现验证码以及刷新验证码
实现代码 /// <summary> /// 生成验证码图片,保存session名称VerificationCode /// </summary> public static ...
- Unity3D 3D模型在GUI之上显示
原来旧的办法是,在主相机上加一个Panel,把3D模型显示在Panel上面,感觉这个方法不怎么好,现在进行改进: 现在用了两个相机,一个相机显示3D模型,另外一个是主相机.还需要GUITexture来 ...
- xgboost的遗传算法调参
遗传算法适应度的选择: 机器学习的适应度可以是任何性能指标 —准确度,精确度,召回率,F1分数等等.根据适应度值,我们选择表现最佳的父母(“适者生存”),作为幸存的种群. 交配: 存活下来的群体中的父 ...
- Java 导入证书
在这个目录下: ${JAVA_HOME}\jre\lib\security 执行 keytool -importcert -trustcacerts -file yourcerfile.pem -al ...
- Linux--多网卡的7种Bond模式和交换机配置
网卡bond是通过把多张网卡绑定为一个逻辑网卡,实现本地网卡的冗余,带宽扩容和负载均衡.在应用部署中是一种常用的技术,我们公司基本所有的项目相关服务器都做了bond,这里总结整理,以便待查. bond ...
- Vue基础知识之组件及组件之间的数据传递(五)
vue中的组件是自定的标签,可以扩展的原生html元素,封装可复用的代码 note: 1.在标签命中不要使用大写,标签名字必须用短横线隔开 2.模板中只能有一个根元素,不能使用并列标签. 定义组件 全 ...
- Docker-compose 在up之后,各个子服务容器的hosts文件中不能找到父服务的域名
使用命令查看docker当前建立的网络: docker network ls 发现docker-compose up确实建立了网络xx_default 使用命令查看该网络详细信息: docker in ...
- 简单工厂法( Factory Method)
工厂方法 (Factory Method) Define an interface for creating an object ,but let subclasses decide which cl ...
- 从最大似然函数 到 EM算法详解
极大似然算法 本来打算把别人讲的好的博文放在上面的,但是感觉那个适合看着玩,我看过之后感觉懂了,然后实际应用就不会了.... MLP其实就是用来求模型参数的,核心就是“模型已知,求取参数”,模型的意思 ...