JAVA使用Gecco爬虫 抓取网页内容(附Demo)
JAVA 爬虫工具有挺多的,但是Gecco是一个挺轻量方便的工具。
先上项目结构图。
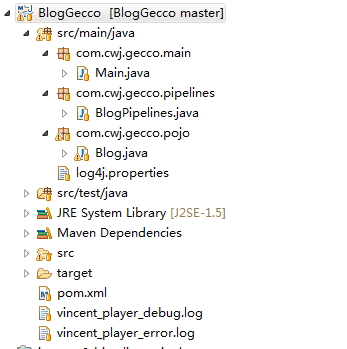
这是一个 JAVASE的 MAVEN 项目,要添加包依赖,其他就四个文件。log4j.properties 加上三个java类。
1、先配置log4j.properties
log4j.rootLogger=INFO,Console,File
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.Target=System.out
log4j.appender.Console.layout = org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=[%c] - %m%n log4j.appender.File = org.apache.log4j.RollingFileAppender
log4j.appender.File.File = logs/ssm.log
log4j.appender.File.MaxFileSize = 10MB
log4j.appender.File.Threshold = ALL
log4j.appender.File.layout = org.apache.log4j.PatternLayout
log4j.appender.File.layout.ConversionPattern =[%p] [%d{yyyy-MM-dd HH\:mm\:ss}][%c]%m%n
2、接下来着手写Blog.java,里面都有注释 不解释
package com.cwj.gecco.pojo; import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.SpiderBean; /**
* @author cwj
* 2017年8月6日
* Blog实体类,运行主函数从这里开始解析
* matchUrl:要抓包的目标地址
* pipelines:跳转到下个pipelines
*/
@Gecco(matchUrl="http://www.cnblogs.com/boychen/p/7226831.html",pipelines="blogPipelines")
public class Blog implements SpiderBean{
/**
* 向指定URL发送GET方法的请求
*/
@Request
private HttpRequest request; /**
* 抓去这个路径下所有的内容
*/
@HtmlField(cssPath = "body div#cnblogs_post_body")
private String content; public HttpRequest getRequest() {
return request;
} public void setRequest(HttpRequest request) {
this.request = request;
} public String getContent() {
return content;
} public void setContent(String content) {
this.content = content;
} }
3、BlogPipelines.java
package com.cwj.gecco.pipelines; import com.cwj.gecco.pojo.Blog;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline; /**
* @author cwj
* 2017年8月6日
* 运行完Blog.java 根据@PipelineName 来这里
*/
@PipelineName(value="blogPipelines")
public class BlogPipelines implements Pipeline<Blog>{ /**
* 将抓取到的内容进行处理 这里是打印在控制台
*/
public void process(Blog blog) {
System.out.println(blog.getContent());
} }
4、最后便是在main中调用
package com.cwj.gecco.main;
import com.geccocrawler.gecco.GeccoEngine;
public class Main {
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.cwj.gecco")
//开始抓取的页面地址
.start("http://www.cnblogs.com/boychen/p/7226831.html")
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(5)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
5、抓取到内容,日志文件被我删除 有警告
附上源码地址 https://github.com/BeautifulMeet/Gecco
JAVA使用Gecco爬虫 抓取网页内容(附Demo)的更多相关文章
- Java豆瓣电影爬虫——抓取电影详情和电影短评数据
一直想做个这样的爬虫:定制自己的种子,爬取想要的数据,做点力所能及的小分析.正好,这段时间宝宝出生,一边陪宝宝和宝妈,一边把自己做的这个豆瓣电影爬虫的数据采集部分跑起来.现在做一个概要的介绍和演示. ...
- PHP爬虫抓取网页内容 (simple_html_dom.php)
使用simple_html_dom.php,下载|文档 因为抓取的只是一个网页,所以比较简单,整个网站的下次再研究,可能用Python来做爬虫会好些. <meta http-equiv=&quo ...
- paip.抓取网页内容--java php python
paip.抓取网页内容--java php python.txt 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog ...
- Java 实现 HttpClients+jsoup,Jsoup,htmlunit,Headless Chrome 爬虫抓取数据
最近整理一下手头上搞过的一些爬虫,有HttpClients+jsoup,Jsoup,htmlunit,HeadlessChrome 一,HttpClients+jsoup,这是第一代比较low,很快就 ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
- 爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 使用Jsoup函数包抓取网页内容
之前写过一篇用Java抓取网页内容的文章,当时是用url.openStream()函数创建一个流,然后用BufferedReader把这个inputstream读取进来.抓取的结果是一整个字符串.如果 ...
- c#抓取网页内容乱码的解决方案
写过爬虫的同学都知道,这是个很常见的问题了,一般处理思路是: 使用HttpWebRequest发送请求,HttpWebResponse来接收,判断HttpWebResponse中”Content-Ty ...
随机推荐
- python Cannot uninstall 'numpy'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
在Python中移除(升级)numpy的时候出现: Cannot uninstall 'numpy'. It is a distutils installed project and thus we ...
- [译]window.onerror事件
本文翻译youtube上的up主kudvenkat的javascript tutorial播放单 源地址在此: https://www.youtube.com/watch?v=PMsVM7rjupU& ...
- hdu 2153 仙人球的残影
题目 这道题可以有两种写法: 第一种:找规律,如下: #include <stdio.h> int main() { int n,i,j,res; while (scanf("% ...
- ListView的另一种可读性更强的ViewHolder模式写法
常见的写法是这样的: @Override public View getView(int position, View convertView, ViewGroup parent) { ViewHol ...
- Feed back TFS 2017 RC upgrade status to product team in product group 2017.03.01
作为微软的MVP,有一个我最喜欢的好处,就是可以与产品组(产品研发部门)有零距离接触,可以最先拿到即将发版的产品,并且和产品组沟通,对产品中出现的问题实时反馈. 看到TFS产品组吸收了自己的建议和反馈 ...
- ubuntu Mono+Jexus 部署到 ASP.NET MVC 5
之前搞了很多次都是卡在了razor那个异常哪里,今天心血来潮就在试一试,一试竟然成功了,激动的我赶紧记录下历程.废话不说,走起... ubuntu 16.04 安装mono(最新版 5.14.0) 官 ...
- C#委托总结-入门篇
1,概念:委托类型表示对具有特定参数列表和返回类型的方法的引用. 通过委托,可以将方法视为可分配给变量并可作为参数传递的实体. 委托是引用类型,可以把它看作是用来存方法的一种类型.比如说类型strin ...
- 基于C#语言MVC框架NPOI控件导出Excel表数据
控件bin文件下载地址:https://download.csdn.net/download/u012949335/10610726@{ ViewBag.Title = "dcxx" ...
- easyui-layout系列之布局(1)
1.Layout布局 通过 $.fn.layout.defaults 重写默认的 defaults. 布局(layout)是有五个区域(北区 north.南区 south.东区 east.西区 wes ...
- Weekly Contest 129
1020. Partition Array Into Three Parts With Equal Sum Given an array A of integers, return true if a ...