Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好。
另一种方法 流形学习 manifold learning
是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 。
类似 一张纸 (二维) 卷起 弄皱 (三维)。二维流形 嵌入到一个三维空间, 就不再是线性的了。
流形方法技巧:
- 多维标度法 multidimensional scaling MSD
- 局部线性嵌入法 locally linear embedding LLE
- 保距映射法 isometric mapping Isomap
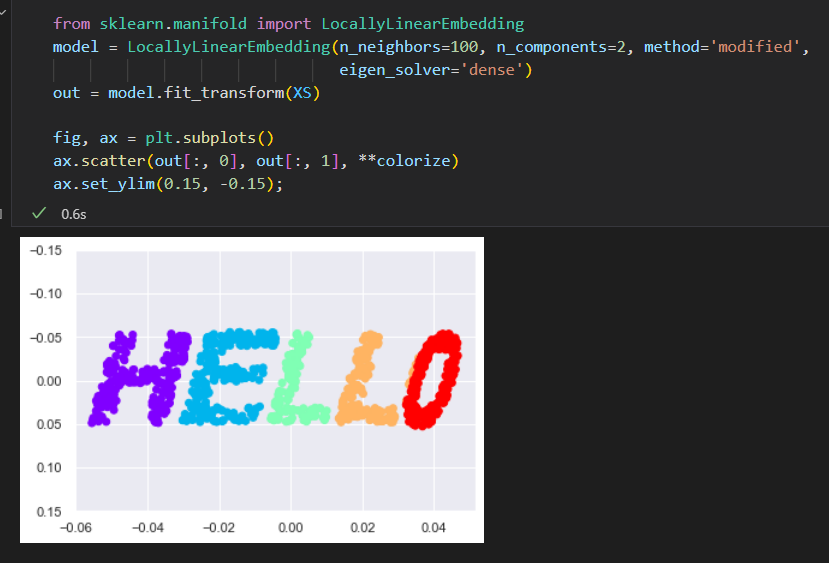
流形学习:HELLO
生成一些二维数据来定义一个流形。
创建一组数据,构成单词hello的形状
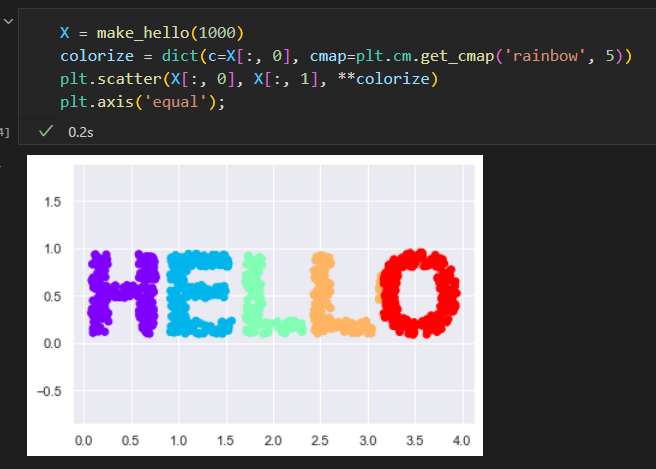
输出图像包含了很多二维的点。
多维标度法
x和 y 的值并不是数据间关系 的必要基础特征, 真正的基础特征是每个点与数据 集中其他 点 的距离。
表示这种关系的常用方法是 关系 距离 矩阵: 对于N个点。构建一个NxN的矩阵, 元素(i,j)是 点 i和点j之间的距离。
使用pairwise_distances函数计算原始数据的关系矩阵
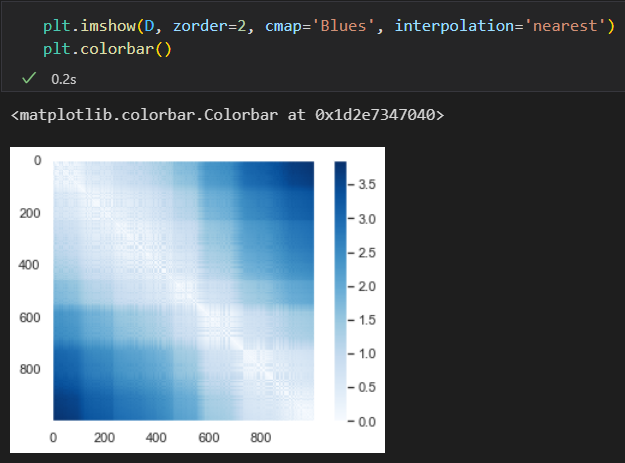
这个距离矩阵给出了一个数据集内部关系的表现形式,这种形式与数据集的旋转和投影无关系,但距离矩阵的可视化效果显得不够直观。
虽然从(x,y)坐标计算这个距离矩阵很简单,但是从距离矩阵转回到(x,y)却很困难。
这就是多维标度发可以解决的问题:他可以将一个数据集的距离矩阵还原成一个D维坐标来表示数据集。
看多维度表法是如何还原距离矩阵的,仅仅依靠描述数据点间关系的NXN距离矩阵,就可以还原出一种可行的二维坐标。
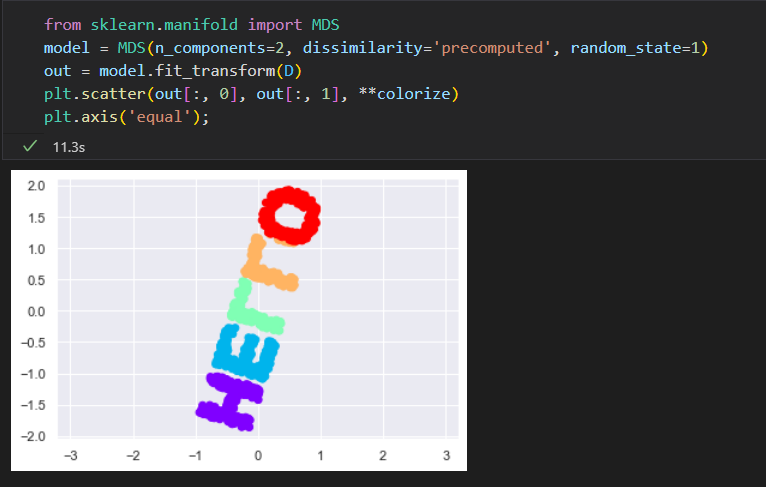
将MDS用于流形学习
既然距离矩阵可以冲数据的任意维度进行计算。 那么这种方法绝对非常实用,
既然可以在一个二维平面中简单的旋转数据,那么也可以用一下函数将其投影到三维孔家。
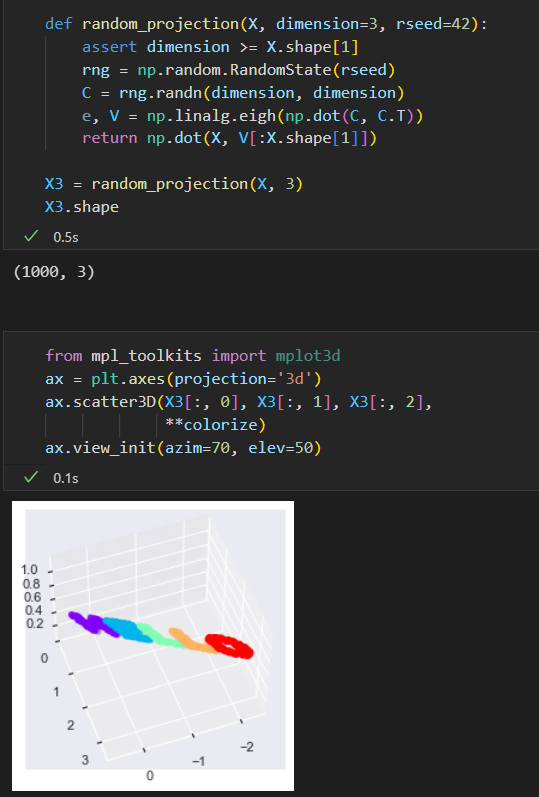
可以通过MDS评估器输入这个三维数据,计算距离急症,然后得出距离矩阵的最优二维嵌入结果。结果还原了原始数据的形状
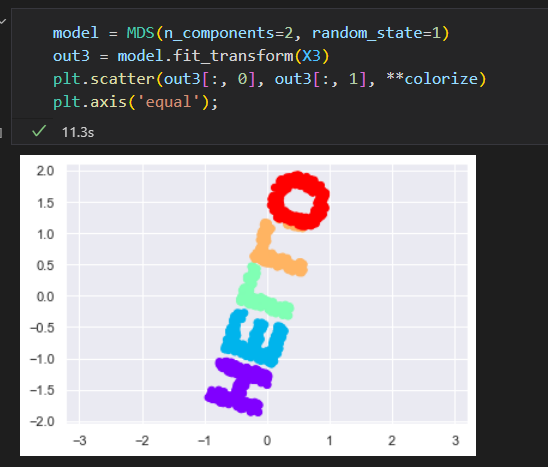
以上就是使用流形学习评估器希望 达成的目标: 给的一个高维嵌入数据,寻找数据的一个低维表示。并保留数据间的特定关系。
在MDS示例中。保留的数据是每对数据点之间的距离。
非线性嵌入:当MDS失败是
当嵌入为非线性是,集超越简单的操作集合时,MDS算法就会失效。
将输入数据在三维空间中扭曲成 S形状的示例
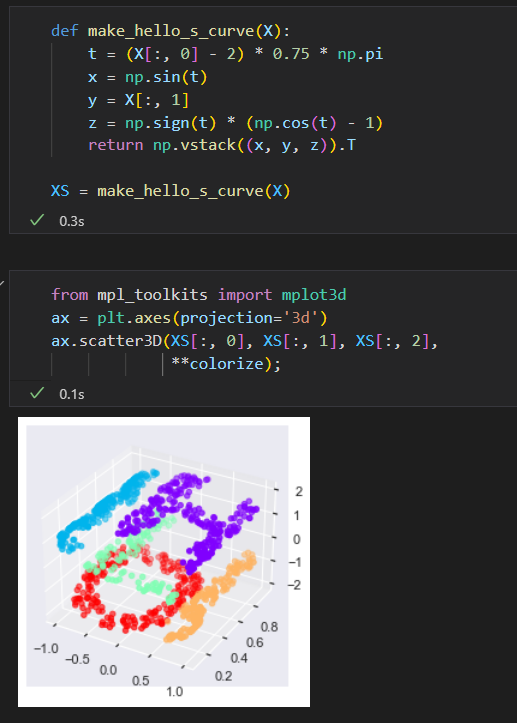
尝试用MDS算法来处理这个数据,就无法展示数据非线性嵌入的特征。进而导致我们丢失了这个嵌入式流形的内部基本关系特性。
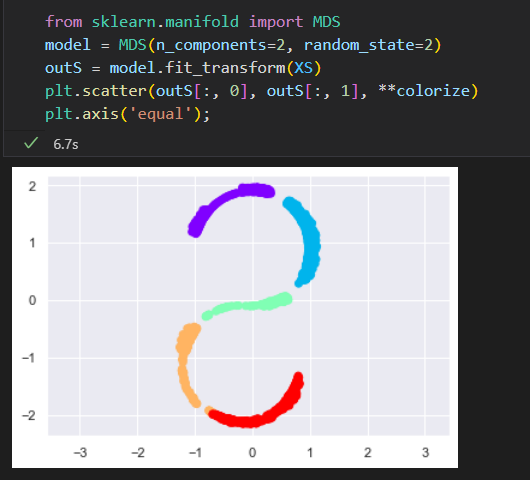
非线性流形: 局部线性嵌入
MDS算法构建嵌入式,总是期望保留相聚很远的数据点之间的距离。如果修改算法,只保留比较接近的点之间的距离。嵌入的结果可能会与我们的期望更接近。
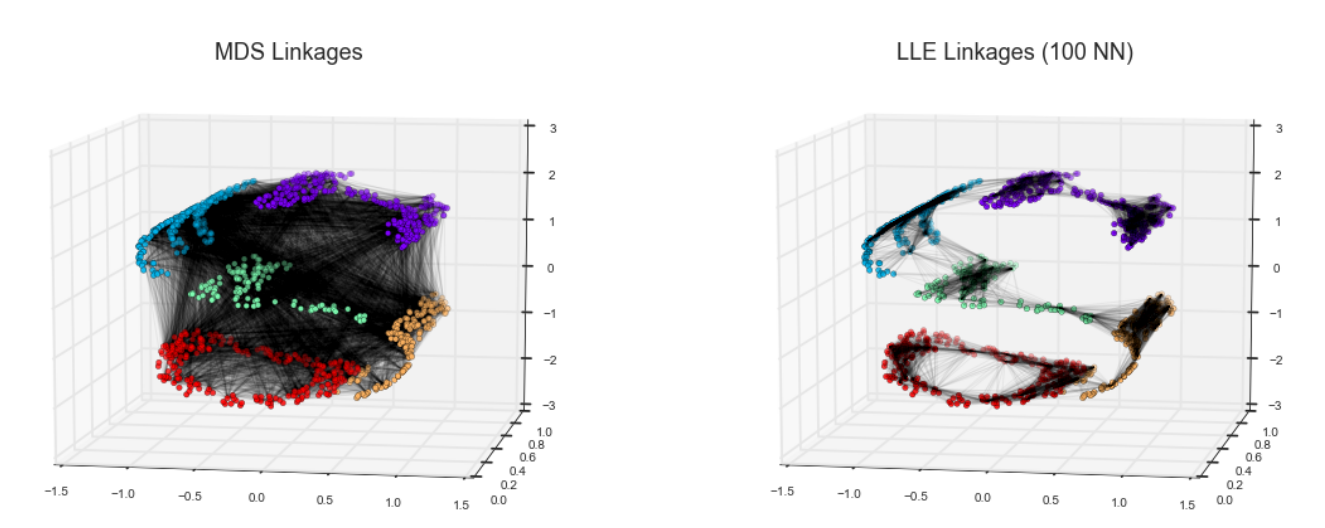
其中每一条细小的线都表示在嵌入式会保留的距离。不保留所有的距离。仅保留邻节点 间的距离。 每个点最近的100个邻节点。
Python数据科学手册-机器学习: 流形学习的更多相关文章
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
随机推荐
- MYSQL索引的建立、删除以及简单使用
一.前期数据准备 1.建表 CREATE TABLE `user` ( `uid` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAUL ...
- Linux,Centos系统下配置java Jdk(附下载地址)
一.下载jdk 官网下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html 需要登录Oracle ...
- SDK导入问题 __imp_与__imp__
目前刚刚实习一周,接触的第一个项目是CMake编译的QT项目,需要引入公司的SDK,编译能过去但是程序就是找不到SDK的接口, 排查了半天发现问题在于:公司的SDK是32位的,自己项目的build k ...
- Android Studio的初次认识
Android的初试 一.认识Android Studio 在我们新建项目的时候,会遇到这样的一个窗口,首先我们认识一下这些都是什么,这样我们才能够更好的进行下一步的学习! 这里的 Phone and ...
- httrack使用cookie克隆站点
关于cookies使用在这里官方已有说明,意思是将cookies.txt文件放在项目的根目下即可,格式也给了说明.问题是cookie值太多,手动不好整理,所以就需要用到神器editthiscookie ...
- springboot java -jar指定启动的jar外部配置文件
Limited Setting Effect 中文描述 Java 8 -Xbootclasspath:<path> Sets the search path for bootstrap c ...
- MQ系列2:消息中间件的技术选型
1 背景 在高并发.高消息吞吐的互联网场景中,我们经常会使用消息队列(Message Queue)作为基础设施,在服务端架构中担当消息中转.消息削峰.事务异步处理 等职能. 对于那些不需要实时响应的的 ...
- python 链表、堆、栈
简介 很多开发在开发中并没有过多的关注数据结构,当然我也是,因此,我写这篇文章就是想要带大家了解一下这些分别是什么东西. 链表 概念:数据随机存储,并且通过指针表示数据之间的逻辑关系的存储结构. 链表 ...
- 【水】关于 __attribute__
目录 1. weak 2. aligned 3. __packed__ 4. always_inline 1. weak 实现如果 Func1 被定义了,我就调用 Func1, 否则就调用 MyFun ...
- PHP小知识收集
PEAR 是"PHP Extension and Application Repository"的缩写,即PHP扩展和应用仓库. PECL 是"PHP Extension ...