【爬虫】一次爬取某瓣top电影前250的学习记录
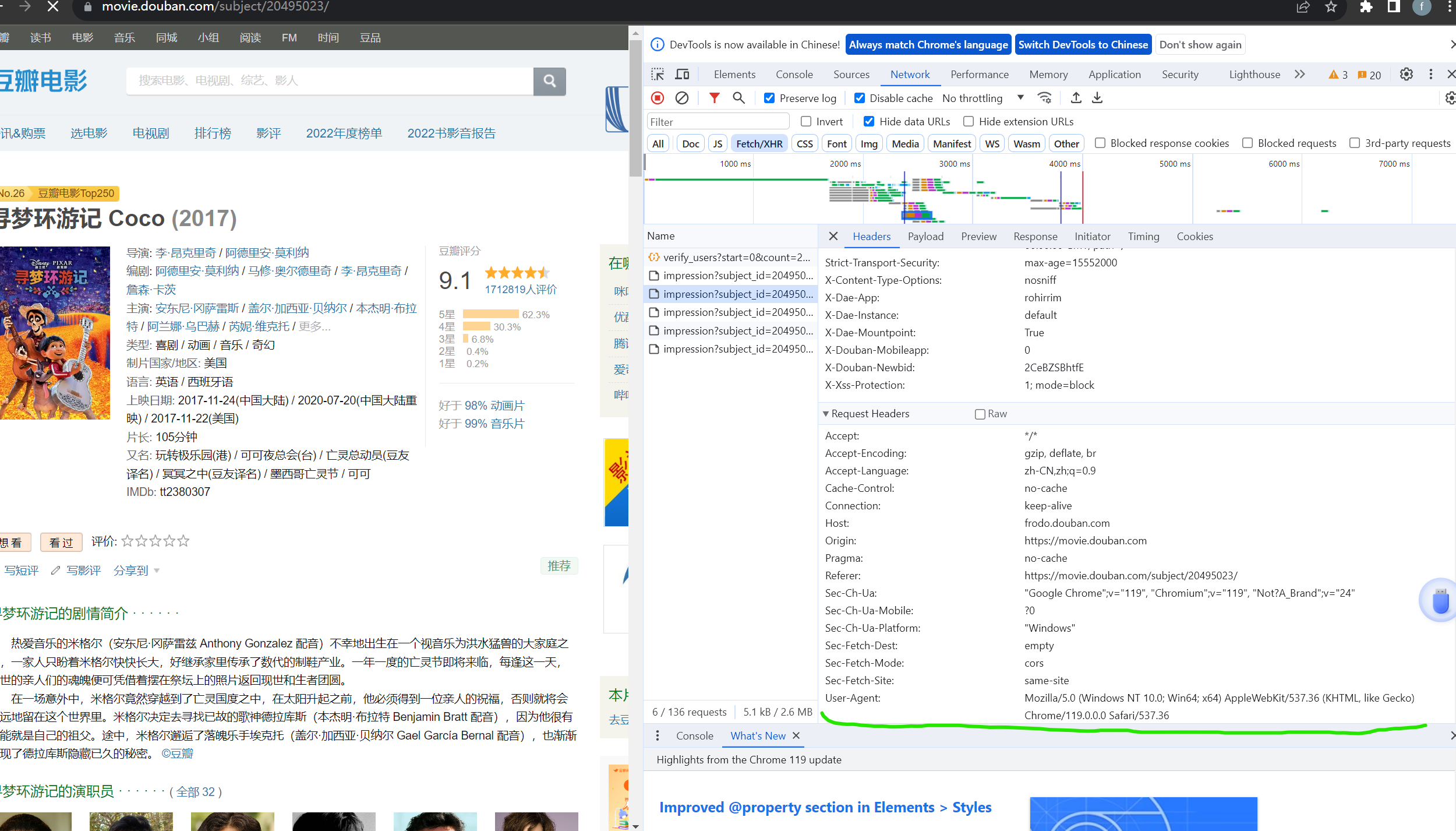
该请求头随意修改就行,合理就行

【爬虫】一次爬取某瓣top电影前250的学习记录的更多相关文章
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- python爬虫08 | 你的第二个爬虫,要过年了,爬取豆瓣最受欢迎的250部电影慢慢看
马上就要过年啦 过年在家干啥咧 准备好被七大姑八大姨轮番「轰炸」了没? 你的内心 os 是这样的 但实际上你是这样的 应付完之后 闲暇时刻不妨看看电影 接下来咱们就来爬取豆瓣上评分最高的 250部电影 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
随机推荐
- 趣图|代码重构前vs重构后
前言 很多程序员对自己写的代码平时很随心所欲,但当有一天让他维护他人的代码,他就会抓狂,很容易激发他体内重构的瘾.(大多数程序员审阅完别人代码后,先会忍不住吐槽一番,然后会忍不住想重构一把,) 在我看 ...
- Trackbar调色板
我们将会建立一个简单的应用,显示我们指定的颜色.将会建立一个窗口,显示三个trackbar指定RGB三个颜色通道值.可以滑动trackbar来改变相应的颜色.默认情况下,初始颜色为黑色. cv2.ge ...
- 关于在Java中计算某个数的N次方注意事项
在实际过程中,我们会遇到计算某个数的N次方的情景,在书面上我们是可以记作 a^n ,然而在Java中我们却不能这样使用,因为在Java中,这样的写法是位运算,即 假设 A = 60, B = 13,他 ...
- 重返照片的原始世界:我为.NET打造的RAW照片解析利器
重返照片的原始世界:我为.NET打造的RAW照片解析利器 如果你是我的老读者,你可能还记得,在2019年,我冒险进入了一片神秘的领域--用C#解析RAW格式的照片: 20191208 - 用.NET解 ...
- java位运算及移位运算你还记得吗
本文中所提到的运算都是基于整数来说的,因为只有整数(包括正数和负数)在操作系统中是以二进制的补码形式运算的,关于原码.反码.补码.位运算.移位运算的背景这里不再介绍,网上资料很多,感兴趣的可自行搜索. ...
- asp.net core之异常处理
在开发过程中,处理错误是一个重要的方面.ASP.NET Core提供了多种方式来处理错误,以确保应用程序的稳定性和可靠性. TryCatch TryCatch是最常见也是最基础的一种异常处理方式,只需 ...
- protoc-gen-doc 自定义模板规则详解
protoc-gen-doc 自定义模板规则详解 配套演示工程 此项目中所用 proto 文件位于 ./proto 目录下,来源于 官方proto示例 此项目中所列所有模板case文件位于 ./tmp ...
- redux的三个概念与三大核心
1.什么是redux?一个组件里可能会有很多的状态,比如控制某个内容显示的flag,从后端获取的展示数据,那么这些状态可以在自己的单个页面进行管理,也可以选择别的管理方式,redux就是是一种状态管理 ...
- .Net Web API 006 Controller上传大文件
1.上传大文件的方式 上传大文件就需要一段一段的上传,主要是先在客户端获取文件的大小,例如想一次传256kb,那就按照256kb分割.分割后又两种上传方式. (1)逐个数据段读取,然后调用API上传, ...
- JavaScript迭代协议
JavaScript迭代协议解读 迭代协议分为可迭代协议和迭代器协议. 协议指约定俗成的一系列规则. 可迭代协议 可迭代协议规定了怎么样算是一个可迭代对象:可迭代对象或其原型链上必须有一个键为[Sym ...