强化学习实战 | 表格型Q-Learning玩井字棋(一)
在 强化学习实战 | 自定义Gym环境之井子棋 中,我们构建了一个井字棋环境,并进行了测试。接下来我们可以使用各种强化学习方法训练agent出棋,其中比较简单的是Q学习,Q即Q(S, a),是状态动作价值,表示在状态s下执行动作a的未来收益的总和。Q学习的算法如下:

可以看到,当agent在状态S,执行了动作a之后,得到了环境给予的奖励R,并进入状态S'。同时,选择最大的Q(S', a),更新Q(S, a)。所谓表格型Q学习,就是构建一个Q(S, a)的表格,维护所有的状态动作价值。 一个很好的示例来自 Q学习玩Flappy Bird,随着游戏的不断进行,Q表格中记录的状态越来越多,状态动作价值也越来越准确,于是小鸟也飞得越来越好。
我们也要构建这样的Q表格,并希望通过Q_table[state][action] 的检索方式访问其储存的状态动作价值,我们可以用字典实现:
| '[1, 0, -1, 0, 0, 0, 1, -1, 0]' | {'(0,1)':0, '(1,0)':0, '(1,1)':0, '(1,2)':0, '(2,2)':0} |
| '[0, 1, 0, -1, 0, 0, -1, 0, 1]' | ...... |
在本文中我们要做到如下的目标:
- 改写 强化学习实战 | 自定义Gym环境之井子棋 中的测试代码,要更有逻辑,更能凸显强化学习中 agent 和环境的概念。
- agent 随机选择空格进行动作,每次动作前,更新Q表格:若表格中不存在当前状态,则将当前状态及其动作价值添加至Q表格中。
- 玩50000次游戏,查看Q表格中的状态数
步骤1:创建文件
在任意目录新建文件 Table QLearning play TicTacToe.py
步骤2:创建类 Agent()
Agent() 类 需要有(1)随机落子的动作生成函数(2)Q表格(3)更新Q表格的函数,且新增表格中全部状态动作价值设为0。代码如下:
class Agent():
def __init__(self):
self.Q_table = {} def getEmptyPos(self, env_): # 返回空位的坐标
action_space = []
for i, row in enumerate(env_.state):
for j, one in enumerate(row):
if one == 0: action_space.append((i,j))
return action_space def randomAction(self, env_, mark): # 随机选择空格动作
actions = self.getEmptyPos(env_)
action_pos = random.choice(actions)
action = {'mark':mark, 'pos':action_pos}
return action def updateQtable(self, env_): # 更新Q表格
state = env_.state
if str(state) not in self.Q_table: # 新增状态
self.Q_table[str(state)] = {}
actions = self.getEmptyPos(env_)
for action in actions:
self.Q_table[str(state)][str(action)] = 0 # 新增的状态动作价值为0
步骤3:创建类 Game()
Game() 类需要有(1)是/否显示游戏过程、更改行动时间间隔的属性(2)开局随机先后手(3)切换行动方的函数(4)游戏结束时,可以新建游戏。代码如下:
class Game():
def __init__(self, env):
self.INTERVAL = 0 # 行动间隔
self.RENDER = False # 是否显示游戏过程
self.first = 'blue' if random.random() > 0.5 else 'red' # 随机先后手
self.currentMove = self.first # 当前行动方
self.env = env
self.agent = Agent() def switchMove(self): # 切换行动玩家
move = self.currentMove
if move == 'blue': self.currentMove = 'red'
elif move == 'red': self.currentMove = 'blue' def newGame(self): # 新建游戏
self.first = 'blue' if random.random() > 0.5 else 'red'
self.currentMove = self.first
self.env.reset() def run(self): # 玩一局游戏
self.env.reset() # 在第一次step前要先重置环境 不然会报错
while True:
if self.currentMove == 'blue': self.agent.updateQtable(self.env) # 只记录蓝方视角下的局面
action = self.agent.randomAction(self.env, self.currentMove)
state, reward, done, info = self.env.step(action)
if self.RENDER: self.env.render()
self.switchMove()
time.sleep(self.INTERVAL)
if done:
self.newGame()
if self.RENDER: self.env.render()
time.sleep(self.INTERVAL)
break
步骤4:测试
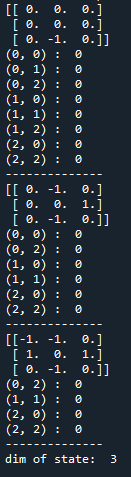
(1)玩一局游戏,显示Q表格,及Q表格中储存的状态数:
env = gym.make('TicTacToeEnv-v0')
game = Game(env)
for i in range(1):
game.run()
for state in game.agent.Q_table:
print(state)
for action in game.agent.Q_table[state]:
print(action, ': ', game.agent.Q_table[state][action])
print('--------------')
print('dim of state: ', len(game.agent.Q_table))
输出:
(2) 玩50000局游戏,查看Q表格中储存的状态数:
env = gym.make('TicTacToeEnv-v0')
game = Game(env)
for i in range(50000):
game.run()
print('dim of state: ', len(game.agent.Q_table))
输出:

整体代码如下:


import gym
import random
import time # 查看所有已注册的环境
# from gym import envs
# print(envs.registry.all()) class Game():
def __init__(self, env):
self.INTERVAL = 0 # 行动间隔
self.RENDER = False # 是否显示游戏过程
self.first = 'blue' if random.random() > 0.5 else 'red' # 随机先后手
self.currentMove = self.first
self.env = env
self.agent = Agent() def switchMove(self): # 切换行动玩家
move = self.currentMove
if move == 'blue': self.currentMove = 'red'
elif move == 'red': self.currentMove = 'blue' def newGame(self): # 新建游戏
self.first = 'blue' if random.random() > 0.5 else 'red'
self.currentMove = self.first
self.env.reset() def run(self): # 玩一局游戏
self.env.reset() # 在第一次step前要先重置环境 不然会报错
while True:
if self.currentMove == 'blue': self.agent.updateQtable(self.env) # 只记录蓝方视角下的局面
action = self.agent.randomAction(self.env, self.currentMove)
state, reward, done, info = self.env.step(action)
if self.RENDER: self.env.render()
self.switchMove()
time.sleep(self.INTERVAL)
if done:
self.newGame()
if self.RENDER: self.env.render()
time.sleep(self.INTERVAL)
break class Agent():
def __init__(self):
self.Q_table = {} def getEmptyPos(self, env_): # 返回空位的坐标
action_space = []
for i, row in enumerate(env_.state):
for j, one in enumerate(row):
if one == 0: action_space.append((i,j))
return action_space def randomAction(self, env_, mark): # 随机选择空格动作
actions = self.getEmptyPos(env_)
action_pos = random.choice(actions)
action = {'mark':mark, 'pos':action_pos}
return action def updateQtable(self, env_):
state = env_.state
if str(state) not in self.Q_table:
self.Q_table[str(state)] = {}
actions = self.getEmptyPos(env_)
for action in actions:
self.Q_table[str(state)][str(action)] = 0 env = gym.make('TicTacToeEnv-v0')
game = Game(env)
for i in range(1):
game.run() for state in game.agent.Q_table:
print(state)
for action in game.agent.Q_table[state]:
print(action, ': ', game.agent.Q_table[state][action])
print('--------------') print('dim of state: ', len(game.agent.Q_table))
强化学习实战 | 表格型Q-Learning玩井字棋(一)的更多相关文章
- 强化学习实战 | 表格型Q-Learning玩井字棋(二)
在 强化学习实战 | 表格型Q-Learning玩井字棋(一)中,我们构建了以Game() 和 Agent() 类为基础的框架,本篇我们要让agent不断对弈,维护Q表格,提升棋力.那么我们先来盘算一 ...
- 强化学习实战 | 表格型Q-Learning玩井子棋(三)优化,优化
在 强化学习实战 | 表格型Q-Learning玩井字棋(二)开始训练!中,我们让agent"简陋地"训练了起来,经过了耗费时间的10万局游戏过后,却效果平平,尤其是初始状态的数值 ...
- 强化学习实战 | 表格型Q-Learning玩井字棋(四)游戏时间
在 强化学习实战 | 表格型Q-Learning玩井字棋(三)优化,优化 中,我们经过优化和训练,得到了一个还不错的Q表格,这一节我们将用pygame实现一个有人机对战,机机对战和作弊功能的井字棋游戏 ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习实战 | 自定义Gym环境之井字棋
在文章 强化学习实战 | 自定义Gym环境 中 ,我们了解了一个简单的环境应该如何定义,并使用 print 简单地呈现了环境.在本文中,我们将学习自定义一个稍微复杂一点的环境--井字棋.回想一下井字棋 ...
- 强化学习实战 | 自定义Gym环境之扫雷
开始之前 先考虑几个问题: Q1:如何展开无雷区? Q2:如何计算格子的提示数? Q3:如何表示扫雷游戏的状态? A1:可以使用递归函数,或是堆栈. A2:一般的做法是,需要打开某格子时,再去统计周围 ...
- TicTacToe井字棋 by reinforcement learning
对于初学强化学习的同学,数学公式也看不太懂, 一定希望有一些简单明了的代码实现加强对入门强化学习的直觉认识,这是一篇初级入门代码, 希望能对你们开始学习强化学习起到基本的作用. 井字棋具体玩法参考百度 ...
- [游戏学习22] MFC 井字棋 双人对战
>_<:太多啦,感觉用英语说的太慢啦,没想到一年做的东西竟然这么多.....接下来要加速啦! >_<:注意这里必须用MFC和前面的Win32不一样啦! >_<:这也 ...
- 强化学习实战 | 自定义Gym环境
新手的第一个强化学习示例一般都从Open Gym开始.在这些示例中,我们不断地向环境施加动作,并得到观测和奖励,这也是Gym Env的基本用法: state, reward, done, info = ...
随机推荐
- 你知道怎么从jar包里获取一个文件的内容吗
目录 背景 报错的代码 原先的写法 编写测试类 找原因 最终代码 背景 项目里需要获取一个excle文件,然后对其里的内容进行修改,这个文件在jar包里,怎么尝试都读取不成功,但是觉得肯定可以做到,因 ...
- bash执行顺序:alias --> function --> builtin --> program
linux bash的执行顺序如下所示: 先 alias --> function --> builtin --> program 后 验证过程: 1,在bash shell中有内置 ...
- 转载:10G以太网光口与Aurora接口回环实验
10G以太网光口与高速串行接口的使用越来越普遍,本文拟通过一个简单的回环实验,来说明在常见的接口调试中需要注意的事项.各种Xilinx FPGA接口学习的秘诀:Example Design.欢迎探讨. ...
- POJ 2446 Chessboard(二分图最大匹配)
题意: M*N的棋盘,规定其中有K个格子不能放任何东西.(即不能被覆盖) 每一张牌的形状都是1*2,问这个棋盘能否被牌完全覆盖(K个格子除外) 思路: M.N很小,把每一个可以覆盖的格子都离散成一个个 ...
- request/response解决中文乱码!!!
Request中文乱码问题以及解决方案 补充三个知识点: Get是URL解码方式.默认解码格式是Tomcat编码格式.所以URL解码是UTF-8,覆盖掉了request容器解码格式 Post是实体内容 ...
- 如何利用SimpleNVR建立全天候远程视频监控系统
随着社会经济的发展,5G.AI.云计算.大数据.物联网等新兴技术迭代更新的驱动下,传统的安防监控早已无法满足我们的需求.那么我们如何建立全天候远程视频监控系统来替代传统监控呢?如何进一步优化城市管理. ...
- 『与善仁』Appium基础 — 8、Appium自动化测试框架介绍
目录 1.主流的移动端自动化测试框架 (1)Robotium (2)Macaca (3)Appium 2.自动化测试工具的选择 3.Appium简介 提示:我们前面说的Android环境搭建和adb命 ...
- 大爽Python入门教程 1-3 简单的循环与判断
大爽Python入门公开课教案 点击查看教程总目录 这里只初步认识下循环和判断,以便于我们去实现一些简单的计算. 循环和判断的详细知识和细节,我们将在后面的章节(大概是第三章)展开阐述. 1 初步了解 ...
- 环境(8)Linux用户组权限
一:Linux时间日期-时间同步策略 1.日期与时间 ①时间命令 data:查看当前系统时间 cal :查看日历 cal 2020 修改时间: date -s 11:11:11 ...
- vue3 学习笔记 (四)——vue3 setup() 高级用法
本篇文章干货较多,建议收藏! 从 vue2 升级到 vue3,vue3 是可以兼容 vue2 的,所以 vue3 可以采用 vue2 的选项式API.由于选项式API一个变量存在于多处,如果出现问题时 ...