Python 爬虫从入门到进阶之路(十四)
之前的文章我们已经可以根据 re 模块,Xpath 模块和 BeautifulSoup4 模块来爬取网站上我们想要的数据并且存储在本地,但是我们并没有对存储数据的格式有要求,本章我们就来看数据的存储格式 JSON 及 Python 中的 json 模块。
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON和XML的比较可谓不相上下。
Python 中自带了JSON模块,直接import json就可以使用了。
官方文档:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/#
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
对象:对象在js中表示为
{ }括起来的内容,数据结构为{ key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。数组:数组在js中是中括号
[ ]括起来的内容,数据结构为["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
Python中 json 模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
1. json.loads()
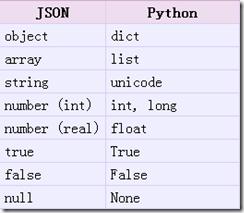
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
import json strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "大猫"}' print(json.loads(strList)) # [1, 2, 3, 4]
print(json.loads(strDict)) # {'city': '北京', 'name': '张三'}
2. json.dumps()
实现 python 类型转化为 json 字符串,返回一个str对象 把一个 Python 对象编码转换成 Json 字符串
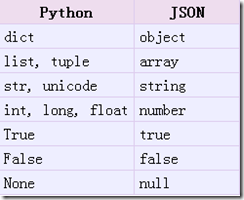
从 python 原始类型向 json 类型的转化对照如下:
import json listStr = [1, 2, 3, 4]
tupleStr = (1, 2, 3, 4)
dictStr = {"city": "北京", "name": "张三"} print(json.dumps(listStr)) # '[1, 2, 3, 4]'
print(json.dumps(tupleStr)) # '[1, 2, 3, 4]'
print(json.dumps(dictStr)) # '{"city": "\u5317\u4eac", "name": "\u5f20\u4e09"}'
3. json.dump()
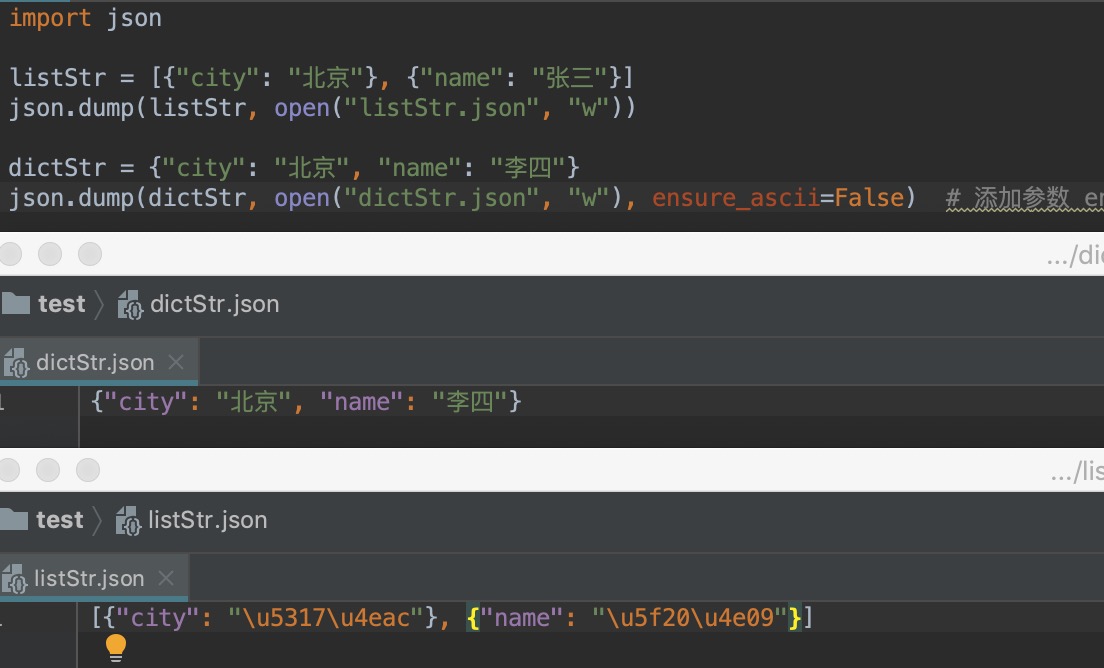
将Python内置类型序列化为json对象后写入文件
import json
listStr = [{"city": "北京"}, {"name": "张三"}]
json.dump(listStr, open("listStr.json", "w"))
dictStr = {"city": "北京", "name": "李四"}
json.dump(dictStr, open("dictStr.json", "w"), ensure_ascii=False) # 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
输出结果:
4. json.load()
读取文件中json形式的字符串元素 转化成python类型
import json
strList = json.load(open("listStr.json"))
print(strList) # [{'city': '北京'}, {'name': '张三'}]
strDict = json.load(open("dictStr.json"))
print(strDict) # {'city': '北京', 'name': '李四'}
JsonPath
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击
Download URL链接下载jsonpath,解压之后执行python setup.py install
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
| XPath | JSONPath | 描述 |
|---|---|---|
/ |
$ |
根节点 |
. |
@ |
现行节点 |
/ |
.or[] |
取子节点 |
.. |
n/a | 取父节点,Jsonpath未支持 |
// |
.. |
就是不管位置,选择所有符合条件的条件 |
* |
* |
匹配所有元素节点 |
@ |
n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] |
[] |
迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] |
支持迭代器中做多选。 |
[] |
?() |
支持过滤操作. |
| n/a | () |
支持表达式计算 |
() |
n/a | 分组,JsonPath不支持 |
示例:
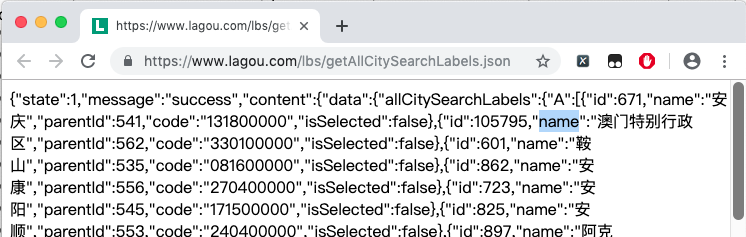
我们以拉勾网城市JSON文件 https://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市。
import urllib.request
import json
import jsonpath
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context url = 'https://www.lagou.com/lbs/getAllCitySearchLabels.json'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
# 发送请求
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# 把json格式字符串转换成python对象
jsonobj = json.loads(html)
# 从根节点开始,匹配name节点
citylist = jsonpath.jsonpath(jsonobj, '$..name') fp = open('city.json', 'w')
content = json.dumps(citylist, ensure_ascii=False)
fp.write(content)
fp.close()
程序启动后会在本地生成一个 city.json 的文件,结果如下:

Python 爬虫从入门到进阶之路(十四)的更多相关文章
- Python 爬虫从入门到进阶之路(四)
之前的文章我们做了一个简单的例子爬取了百度首页的 html,我们用到的是 urlopen 来打开请求,它是一个特殊的opener(也就是模块帮我们构建好的).但是基本的 urlopen() 方法不支持 ...
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
随机推荐
- 淘宝平台进行数据的实时传输: TimeTunnel介绍
在班级工作中遇到似业务场景中的实时流传输数据的访问,所以,淘宝实时数据仓库这个人做了一些研究和了解. 本文介绍的业务场景和淘宝的设计TimeTunnel工具,从淘宝数据仓库团队沟通过程中的图像文字si ...
- .net core service && angular项目 iis发布
项目结构 .net core 后端服务站点 angular 前端页面站点 项目模板来自于abp或者52abp .net core 后端服务站点发布到IIS 发布报错 .Net Core使用IIS部署出 ...
- WPF 寻找控件模板中的元素
<Window x:Class="Wpf180706.Window10" xmlns="http://schemas.microsoft.com/wi ...
- 客户端技术的一点思考(数据存储用SQLite, XMPP通讯用Gloox, Web交互用LibCurl, 数据打包用Protocol Buffer, socket通讯用boost asio)
今天看到CSDN上这么一篇< 彻底放弃没落的MFC,对新人的忠告!>, 作为一个一直在Windows上搞客户端开发的C++程序员,几年前也有过类似的隐忧(参见 落伍的感觉), 现在却有一些 ...
- PHP提取字符串中的图片地址
PHP提取字符串中的图片地址 $str='<p><img border="0" src="upfiles/2009/07/1246430143_1.jp ...
- UWP的TextBox和PasswordBox使用输入范围更改触摸键盘InputScope
原文:UWP的TextBox和PasswordBox使用输入范围更改触摸键盘InputScope 当你的应用运行在具有触摸屏的设备上时,触摸键盘可用于文本输入.当用户点击可编辑的输入字段(如 Text ...
- 如何在项目中添加Log4net_web.config
<log4net> <appender name="ConsoleAppender" type="log4net.Appender.ConsoleApp ...
- 海康SDK编程指南
转至心澄欲遣 目前使用的海康SDK包括IPC_SDK(硬件设备),Plat_SDK(平台),其中两套SDK都需单独调用海康播放库PlayCtrl.dll来解码视频流,返回视频信息和角度信息.本文仅对视 ...
- 微服务示例-Spring Cloud
1~开发准备 JDK:1.8 Spring Boot:1.5.9.RELEASE Spring Coud:Edgware.RELEASE IDE:IntelliJ IDEA 2017 Maven:3. ...
- WPF使用AForge实现Webcam预览(二)
本文主要介绍如何让摄像头预览界面的宽高比始终在16:9. 首先我们需要修改一下上一篇随笔实现的UI界面,让Grid变成一个3*3的九宫格,预览界面位于正中间.Xaml示例代码如下: <Windo ...