吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import cluster
from sklearn.metrics import adjusted_rand_score
from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5) #K-MEANS聚类模型
def test_Kmeans(*data):
X,labels_true=data
clst=cluster.KMeans()
clst.fit(X)
predicted_labels=clst.predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels))
print("Sum center distance %s"%clst.inertia_) # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# 调用 test_Kmeans 函数
test_Kmeans(X,labels_true)
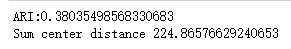
def test_Kmeans_nclusters(*data):
'''
测试 KMeans 的聚类结果随 n_clusters 参数的影响
'''
X,labels_true=data
nums=range(1,50)
ARIs=[]
Distances=[]
for num in nums:
clst=cluster.KMeans(n_clusters=num)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
Distances.append(clst.inertia_)
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,2,1)
ax.plot(nums,ARIs,marker="+")
ax.set_xlabel("n_clusters")
ax.set_ylabel("ARI")
ax=fig.add_subplot(1,2,2)
ax.plot(nums,Distances,marker='o')
ax.set_xlabel("n_clusters")
ax.set_ylabel("inertia_")
fig.suptitle("KMeans")
plt.show() test_Kmeans_nclusters(X,labels_true) # 调用 test_Kmeans_nclusters 函数

def test_Kmeans_n_init(*data):
'''
测试 KMeans 的聚类结果随 n_init 和 init 参数的影响
'''
X,labels_true=data
nums=range(1,50)
## 绘图
fig=plt.figure() ARIs_k=[]
Distances_k=[]
ARIs_r=[]
Distances_r=[]
for num in nums:
clst=cluster.KMeans(n_init=num,init='k-means++')
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs_k.append(adjusted_rand_score(labels_true,predicted_labels))
Distances_k.append(clst.inertia_) clst=cluster.KMeans(n_init=num,init='random')
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs_r.append(adjusted_rand_score(labels_true,predicted_labels))
Distances_r.append(clst.inertia_) ax=fig.add_subplot(1,2,1)
ax.plot(nums,ARIs_k,marker="+",label="k-means++")
ax.plot(nums,ARIs_r,marker="+",label="random")
ax.set_xlabel("n_init")
ax.set_ylabel("ARI")
ax.set_ylim(0,1)
ax.legend(loc='best')
ax=fig.add_subplot(1,2,2)
ax.plot(nums,Distances_k,marker='o',label="k-means++")
ax.plot(nums,Distances_r,marker='o',label="random")
ax.set_xlabel("n_init")
ax.set_ylabel("inertia_")
ax.legend(loc='best') fig.suptitle("KMeans")
plt.show() test_Kmeans_n_init(X,labels_true) # 调用 test_Kmeans_n_init 函数

吴裕雄 python 机器学习——K均值聚类KMeans模型的更多相关文章
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——数据预处理流水线Pipeline模型
from sklearn.svm import LinearSVC from sklearn.pipeline import Pipeline from sklearn import neighbor ...
随机推荐
- 哈代平衡 &连锁不平衡
哈代-温伯格平衡定律(Hardy-Weinberg equilibrium),即HW平衡,是指对于一个大且随机交配的种群,基因频率和基因型频率在没有迁移.突变和选择的条件下会保持不变. 它是建立在一个 ...
- java grpc实例分析
一.Protocol Buffer 我们还是先给出一个在实际开发中经常会遇到的系统场景.比如:我们的客户端程序是使用Java开发的,可能运行自不同的平台,如:Linux.Windows或者是Andro ...
- Underscore.js实用插件
Underscore 是一个 JavaScript 工具库,它提供了一整套函数式编程的实用功能,但是没有扩展任何 JavaScript 内置对象. 他解决了这个问题:“如果我面对一个空白的 HTML ...
- iOS应用开发之CoreData[转]
我目前的理解,CoreData相当于一个综合的数据库管理库,它支持sqlite,二进制存储文件两种形式的数据存储.而CoreData提供了存储管理,包括查询.插入. 删除.更新.回滚.会话管理.锁管理 ...
- 编写高质量代码改善C#程序的157个建议——建议111:避免双向耦合
建议111:避免双向耦合 双向耦合是指两个类型之间相互引用.下面的代码是一种典型的双向耦合: class A { private B b; public void MethodA() { b.Meth ...
- 如何Android中加入扫描名片功能
要想实现android手机通过扫描名片,得到名片信息,可以使用脉可寻提供的第三方SDK,即Maketion ScanCard SDK,脉可寻云名片识别服务.他们的官方网站为http://www.mak ...
- 【Head First Java 读书笔记】(七)继承
继承与多态 了解继承 继承的关系意味着子类继承了父类的实例变量和方法.父类比较抽象,子类比较具体. 继承层次的设计 找出具有共同属性和行为的对象(用继承来防止子类中出现重复的程序代码) 设计代表共同状 ...
- java学习(七)java中抽象类及 接口
抽象类的特点: A:抽象类和抽象方法必须用abstract关键字修饰. B:抽象类中不一定有抽象方法,但是抽象方法的类必须定义为抽象类 c: 抽象类不能被实例化,因为它不是具体的. 抽象类有构造方法, ...
- java策略模式(及与工厂模式的区别)
按一般教程中出现的例子理解: 简单工厂模式:客户端传一个条件进工厂类,工厂类根据条件创建相应的产品类对象,并return给客户端,供客户端使用.即客户端使用的是工厂类生产的产品对象. 策略模式:客户端 ...
- js 操作cookie cookie路径问题
这里主要不是讲这个方法,js写cookie这种代码网上一抓一把,在使用的时候遇到一点问题,就是写的cookie 是有路径问题的,在user目录下可以使用跳转到另外一个目录下cookie,经过比较coo ...