使用ML.NET实现白葡萄酒品质预测
导读:ML.NET系列文章
本文将基于ML.NET v0.2预览版,介绍机器学习中的分类和回归两个重要概念,并实现白葡萄酒品质预测。
本系列前面的文章也提到了一些,经典的机器学习最主要的特点就是模拟,具体来说就是定义出一个y=f(x)函数,x就是我们定义的特征值(它可能是一个/组标量,也可能是一个/组向量),y就是目标值,这个函数的目标是要无限满足所有(x, y)都出现在函数y=f(x)在坐标轴上经过的地方,这有时候也叫函数逼近。试想,只要这个函数是模拟出了对某类问题的输入和输出值(x, y)的运算过程,那再来一个新的输入值x,是不是就可以求解出输出值y是什么了!基于这个道理,机器学习才有了预知未来的能力。那么,对未来的预知最常见的两种情况:一个是为了分类,一个是为了回归。“分类”的概念容易理解,它要解决的目标值是标签类的数据,比如属于什么物种,是否是垃圾邮件,什么类型的电影之类的问题,而“回归”的概念需要一点想像力,它要解决的目标值是纯粹的实数的数据,比如下一场考试得多少分,今年世界杯冠军是进几个球获胜,那个小伙能吸引到周边妹子的魅力值有多高等等。是不是一下子觉得很神奇,兴致就来了?!
再容我多说几句,分类预测与回归预测,同样是建模,解决的问题“可以是”不一样的(注意这个——可以是),简单地来看,分类要预测一个离散的标签,多个标签互相之间没有关系,目的是要选其中最恰当的一个;而回归是预测一个连续变化的数,且必须是在一定范围内有延续关系的数,预测的结果值是变化过程中的其中一个。分类和回归其实也能说有一些相同的地方,分类算法也是有预测到一个连续的值,但是这些连续值对应的是一个类别在概率上不同的面而已;而回归算法照样可以预测离散值,但是以整数形式预测离散值的,本质上是把类别下的每一个子类都按字典形式找一个数值对应上罢了。于是,得出一个奇妙的结论,分类和回归问题能够以合适的手段进行转换。这个结论的作用,就是说当以分类或回归之一进行机器学习找不到合适的算法训练出模型时,不妨尝试转换到另一个方向去寻求突破。

好了,胡诌了一些晕乎乎的理论后,本文继续使用ML.NET带来一个回归模型的案例,根据白葡萄酒的各项酿制成分参数来预测其品质好坏。这次的数据集取自著名的竞赛网站——Kaggle.com的其中一个考题UCI Wine Quality Dataset,数据内容类似如下:
fixed.acidity,volatile.acidity,citric.acid,residual.sugar,chlorides,free.sulfur.dioxide,total.sulfur.dioxide,density,pH,sulphates,alcohol,quality,id
6.5,0.28,0.35,15.4,0.042,55,195,0.9978,3.23,0.5,9.6,6,3900
7.3,0.19,0.49,15.55,0.058,50,134,0.9998,3.42,0.36,9.1,7,3901
6.4,0.16,0.32,8.75,0.038,38,118,0.99449,3.19,0.41,10.7,5,3902
7.4,0.19,0.3,12.8,0.053,48.5,229,0.9986,3.14,0.49,9.1,7,3903
...
各个字段说明是这样:
成分
1 - fixed acidity 非挥发性酸
2 - volatile acidity 挥发性酸度
3 - citric acid 柠檬酸
4 - residual sugar 剩余糖分
5 - chlorides 氯化物
6 - free sulfur dioxide 游离二氧化
7 - total sulfur dioxide 总二氧化硫
8 - density 密度
9 - pH 酸碱度
10 - sulphates 硫酸盐
11 - alcohol 酒精 输出标签 (品酒师的感受值):
12 - 品质(分值0-10) 其它:
13 - id (样本序号)
首先创建训练和预测用的数据结构:
public class WineData
{
[Column(ordinal: "")]
public float FixedAcidity;
[Column(ordinal: "")]
public float VolatileAcidity;
[Column(ordinal: "")]
public float CitricACID;
[Column(ordinal: "")]
public float ResidualSugar;
[Column(ordinal: "")]
public float Chlorides;
[Column(ordinal: "")]
public float FreeSulfurDioxide;
[Column(ordinal: "")]
public float TotalSulfurDioxide;
[Column(ordinal: "")]
public float Density;
[Column(ordinal: "")]
public float PH;
[Column(ordinal: "")]
public float Sulphates;
[Column(ordinal: "")]
public float Alcohol;
[Column(ordinal: "", name: "Label")]
public float Quality;
[Column(ordinal: "")]
public float Id;
} public class WinePrediction
{
[ColumnName("Score")]
public float PredictionQuality;
}
训练部分,这次使用了一个对象叫ColumnDropper,可以用来在训练开始前舍弃掉不需要的字段,比如id,对结果没有任何影响,因此可以去掉。
static PredictionModel<WineData, WinePrediction> Train()
{
var pipeline = new LearningPipeline();
pipeline.Add(new Microsoft.ML.Data.TextLoader(DataPath).CreateFrom<WineData>(useHeader: true, separator: ',', trimWhitespace: false));
pipeline.Add(new ColumnDropper() { Column = new[] { "Id" } });
pipeline.Add(new ColumnConcatenator("Features", "FixedAcidity", "VolatileAcidity", "CitricACID", "ResidualSugar", "Chlorides", "FreeSulfurDioxide", "TotalSulfurDioxide", "Density", "PH", "Sulphates", "Alcohol"));
pipeline.Add(new FastTreeRegressor());
var model = pipeline.Train<WineData, WinePrediction>();
return model;
}
评估部分,要注意三个值 ,Rmsj是均方根值,用来展示有效度的,LossFn是损失值,顾名思义损失的程度嘛,当然越低越好了,RSquared是误差值,用来反映拟合度好坏的,如果接近0甚至负数,说明训练出来的模型已瞎,还不如人眼了。
static void Evaluate(PredictionModel<WineData, WinePrediction> model)
{
var testData = new Microsoft.ML.Data.TextLoader(TestDataPath).CreateFrom<WineData>(useHeader: true, separator: ',', trimWhitespace: false);
var evaluator = new Microsoft.ML.Models.RegressionEvaluator();
var metrics = evaluator.Evaluate(model, testData);
Console.WriteLine("Rms=" + metrics.Rms);
Console.WriteLine("LossFn=" + metrics.LossFn);
Console.WriteLine("RSquared = " + metrics.RSquared);
}
预测部分,如上一篇那样,通过新版本的TextLoader进行加载,并且处理成集合。
static void Predict(PredictionModel<WineData, WinePrediction> model)
{
using (var environment = new TlcEnvironment())
{
var textLoader = new Microsoft.ML.Data.TextLoader(TestDataPath).CreateFrom<WineData>(useHeader: true, separator: ',', trimWhitespace: false);
var experiment = environment.CreateExperiment();
var output = textLoader.ApplyStep(null, experiment) as ILearningPipelineDataStep; experiment.Compile();
textLoader.SetInput(environment, experiment);
experiment.Run();
var data = experiment.GetOutput(output.Data);
var wineDatas = new List<WineData>();
using (var cursor = data.GetRowCursor((a => true)))
{
var getters = new ValueGetter<float>[]{
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>(),
cursor.GetGetter<float>()
}; while (cursor.MoveNext())
{
float value0 = ;
float value1 = ;
float value2 = ;
float value3 = ;
float value4 = ;
float value5 = ;
float value6 = ;
float value7 = ;
float value8 = ;
float value9 = ;
float value10 = ;
float value11 = ;
float value12 = ;
getters[](ref value0);
getters[](ref value1);
getters[](ref value2);
getters[](ref value3);
getters[](ref value4);
getters[](ref value5);
getters[](ref value6);
getters[](ref value7);
getters[](ref value8);
getters[](ref value9);
getters[](ref value10);
getters[](ref value11);
getters[](ref value12); var wdata = new WineData()
{
FixedAcidity = value0,
VolatileAcidity = value1,
CitricACID = value2,
ResidualSugar = value3,
Chlorides = value4,
FreeSulfurDioxide = value5,
TotalSulfurDioxide = value6,
Density = value7,
PH = value8,
Sulphates = value9,
Alcohol = value10,
Quality = value11,
Id = value12,
};
wineDatas.Add(wdata);
}
}
var predictions = model.Predict(wineDatas); var wineDataAndPredictions = wineDatas.Zip(predictions, (wineData, prediction) => (wineData, prediction));
Console.WriteLine($"Wine Id: {wineDataAndPredictions.Last().wineData.Id}, Quality: {wineDataAndPredictions.Last().wineData.Quality} | Prediction: { wineDataAndPredictions.Last().prediction.PredictionQuality}");
Console.WriteLine();
}
}
最后调用Main函数部分。
static void Main(string[] args)
{
var model = Train();
Evaluate(model);
Predict(model);
}
好了,运行起来结果如下:
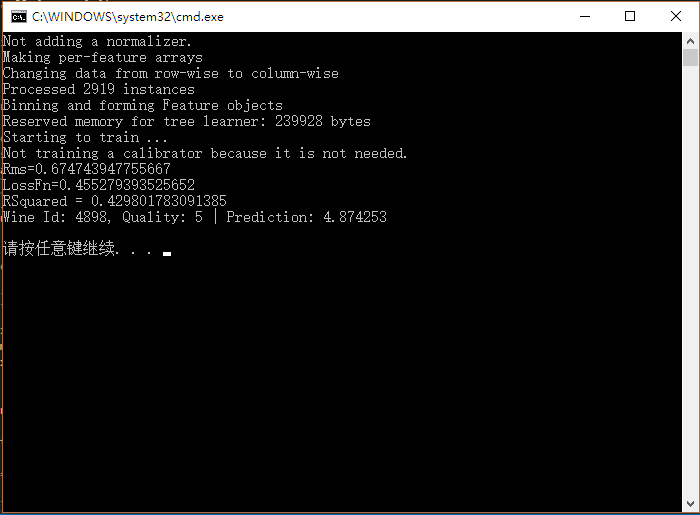
怎么样,没喝过酒咱也能当一把品酒师,专业程度照样不会差!
本案例代码和数据:下载
更多案例值得期待!
不少新入门的伙伴来问,有没有给力的学习课程,想早一点跨入机器学习的门槛,我在《机器学习课程不完全收录(持续更新)》收集了一些,都是容易学起来的课程,理论与实践都有,不论怎么说比我讲的要高出不知多少个档次了,可以按自己的喜好选择。
使用ML.NET实现白葡萄酒品质预测的更多相关文章
- 使用ML.NET实现NBA得分预测
使用ML.NET实现NBA得分预测 导读:ML.NET系列文章 ML.NET已经发布了v0.2版本,新增了聚类训练器,执行性能进一步增强.本文将介绍一种特殊的回归--泊松回归,并以NBA比赛得分预测的 ...
- ML.NET
ML.NET http://www.cnblogs.com/BeanHsiang/category/1218714.html 随笔分类 - 使用ML.NET实现NBA得分预测 摘要: 本文将介绍一种特 ...
- 机器学习框架ML.NET学习笔记【9】自动学习
一.概述 本篇我们首先通过回归算法实现一个葡萄酒品质预测的程序,然后通过AutoML的方法再重新实现,通过对比两种实现方式来学习AutoML的应用. 首先数据集来自于竞赛网站kaggle.com的UC ...
- ML.NET指南
ML.NET是一个免费的.开源和跨平台的机器学习框架,使您能够构建定制的机器学习解决方案,并将它们集成到您的. net应用程序.本指南提供了许多关于与ML.NET合作资源. 关于ML.NET的更多信息 ...
- R语言 多元线性回归分析
#线性模型中有关函数#基本函数 a<-lm(模型公式,数据源) #anova(a)计算方差分析表#coef(a)提取模型系数#devinace(a)计算残差平方和#formula(a)提取模型公 ...
- 项目实战-使用PySpark处理文本多分类问题
原文链接:https://cloud.tencent.com/developer/article/1096712 在大神创作的基础上,学习了一些新知识,并加以注释. TARGET:将旧金山犯罪记录(S ...
- ApacheCN C# 译文集 20211124 更新
C# 代码整洁指南 零.前言 一.C# 代码标准和原则 二.代码审查--过程和重要性 三.类.对象和数据结构 四.编写整洁的函数 五.异常处理 六.单元测试 七.端到端系统测试 八.线程和并发 九.设 ...
- 使用ML.NET预测纽约出租车费
有了上一篇<.NET Core玩转机器学习>打基础,这一次我们以纽约出租车费的预测做为新的场景案例,来体验一下回归模型. 场景概述 我们的目标是预测纽约的出租车费,乍一看似乎仅仅取决于行程 ...
- ML.NET 示例:回归之价格预测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
随机推荐
- window mysql安装
1.选择下载版本 接着上几篇文章再来看下windows下安装mysql. 我这里是windows7 64位, 安装过程中还是遇到一些坑,这里记录下. 一.下载安装包 打开mysql官网下载页面:htt ...
- jedis keys和scan操作
关于redis的keys命令的性能问题 KEYS pattern 查找所有符合给定模式 pattern 的 key . KEYS * 匹配数据库中所有 key . KEYS h?llo 匹配 hell ...
- 问题之Spring MVC配置后,可以打开jsp页面,但打不开html页面
一.配置Spring MVC 1.导入jar spring框架:http://repo.spring.io/release/org/springframework/spring/ spring-fra ...
- java -ui自动化初体验
本文来讲一下ui自动化的环境搭建,以及最初级的打开网页操作 说起ui自动化,想想大概是前年的时候我开始接触和学习的吧,怎么说呢无论是pc还是app,ios还是android,确实很神奇而且很华丽,但是 ...
- 自己编译Android(小米5)内核并刷入(一键自动编译打包)
之前自己编译过Android系统,刷入手机.编译很简单,但坑比较大,主要是GFW埋的坑.. 编译android系统太大了,今天记下自己编译及刷入android内核的方法. 主要是看到第三方内核可以超频 ...
- jquery for循环
第一种: for(var i=0,len=$len.length; i<len; i++){//alert($len.eq(i).html());$zongshu=$zongshu+$len.e ...
- 守护模式,互斥锁,IPC通讯,生产者消费者模型
'''1,什么是生产者消费者模型 生产者:比喻的是程序中负责产生数据的任务 消费者:比喻的是程序中负责处理数据的任务 生产者->共享的介质(队列)<-消费者 2,为何用 实现了生产者与消费 ...
- 使用getline输入一行字符串
给定10个国家名,按字母顺序输出,国家名中可以包含空格,国家名用换行隔开 #include<algorithm> #include<iostream> #include< ...
- 20175324王陈峤宇 《Java程序设计》第六周学习总结
教材学习内容总结 第七章 一.内部类与外部类的关系 1.内部类可以使用外嵌类的成员变量和方法.2.类体中不可以声明类变量和类方法,外部类可以用内部类声明对象.3.内部类仅供外嵌类使用.4.类声明可以使 ...
- win10企业版永久激活方法
步骤: 1.右键点击桌面左下角"windows"图标,点击打开“命令提示符” 2.复制命令:slmgr.vbs /upk,按回车确定,弹出窗口显示“成功地卸载了产品密钥” 3.复制 ...