Python豆瓣书籍信息爬虫
练习下BeautifulSoup,requests库,用python3.3 写了一个简易的豆瓣小爬虫,将爬取的信息在控制台输出并且写入文件中。
上源码:
# coding = utf-8
'''my words
基于python3 需要的库 requests BeautifulSoup
这个爬虫很基本,没有采用任何的爬虫框架,用requests,BeautifulSoup,re等库。
这个爬虫的基本功能是爬取豆瓣各个类型的书籍的信息:作者,出版社,豆瓣评分,评分人数,出版时间等信息。
不能保证爬取到的信息都是正确的,可能有误。
也可以把爬取到的书籍信息存放在数据库中,这里只是输出到控制台。
爬取到的信息存储在文本txt中。
''' import requests
from bs4 import BeautifulSoup
import re #爬取豆瓣所有的标签分类页面,并且提供每一个标签页面的URL
def provide_url():
# 以http的get方式请求豆瓣页面(豆瓣的分类标签页面)
responds = requests.get("https://book.douban.com/tag/?icn=index-nav")
# html为获得响应的页面内容
html = responds.text
# 解析页面
soup = BeautifulSoup(html, "lxml")
# 选取页面中的需要的a标签,从而提取出其中的所有链接
book_table = soup.select("#content > div > .article > div > div > .tagCol > tbody > tr > td > a")
# 新建一个列表来存放爬取到的所有链接
book_url_list = []
for book in book_table:
book_url_list.append('https://book.douban.com/tag/' + str(book.string))
return book_url_list #获得评分人数的函数
def get_person(person):
person = person.get_text().split()[0]
person = re.findall(r'[0-9]+',person)
return person #当detail分为四段时候的获得价格函数
def get_rmb_price1(detail):
price = detail.get_text().split('/',4)[-1].split()
if re.match("USD", price[0]):
price = float(price[1]) * 6
elif re.match("CNY", price[0]):
price = price[1]
elif re.match("\A$", price[0]):
price = float(price[1:len(price)]) * 6
else:
price = price[0]
return price #当detail分为三段时候的获得价格函数
def get_rmb_price2(detail):
price = detail.get_text().split('/',3)[-1].split()
if re.match("USD", price[0]):
price = float(price[1]) * 6
elif re.match("CNY", price[0]):
price = price[1]
elif re.match("\A$", price[0]):
price = float(price[1:len(price)]) * 6
else:
price = price[0]
return price #测试输出函数
def test_print(name,author,intepretor,publish,time,price,score,person):
print('name: ',name)
print('author:', author)
print('intepretor: ',intepretor)
print('publish: ',publish)
print('time: ',time)
print('price: ',price)
print('score: ',score)
print('person: ',person) #解析每个页面获得其中需要信息的函数
def get_url_content(url):
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html.encode('utf-8'),"lxml")
tag = url.split("?")[0].split("/")[-1] #页面标签,就是页面链接中'tag/'后面的字符串
titles = soup.select(".subject-list > .subject-item > .info > h2 > a") #包含书名的a标签
details = soup.select(".subject-list > .subject-item > .info > .pub") #包含书的作者,出版社等信息的div标签
scores = soup.select(".subject-list > .subject-item > .info > div > .rating_nums") #包含评分的span标签
persons = soup.select(".subject-list > .subject-item > .info > div > .pl") #包含评价人数的span标签 print("*******************这是 %s 类的书籍**********************" %tag) #打开文件,将信息写入文件
file = open("C:/Users/lenovo/Desktop/book_info.txt",'a') #可以更改为你自己的文件地址
file.write("*******************这是 %s 类的书籍**********************" % tag) #用zip函数将相应的信息以元祖的形式组织在一起,以供后面遍历
for title,detail,score,person in zip(titles,details,scores,persons):
try:#detail可以分成四段
name = title.get_text().split()[0] #书名
author = detail.get_text().split('/',4)[0].split()[0] #作者
intepretor = detail.get_text().split('/',4)[1] #译者
publish = detail.get_text().split('/',4)[2] #出版社
time = detail.get_text().split('/',4)[3].split()[0].split('-')[0] #出版年份,只输出年
price = get_rmb_price1(detail) #获取价格
score = score.get_text() if True else "" #如果没有评分就置空
person = get_person(person) #获得评分人数
#在控制台测试打印
test_print(name,author,intepretor,publish,time,price,score,person)
#将书籍信息写入txt文件
try:
file.write('name: %s ' % name)
file.write('author: %s ' % author)
file.write('intepretor: %s ' % intepretor)
file.write('publish: %s ' % publish)
file.write('time: %s ' % time)
file.write('price: %s ' % price)
file.write('score: %s ' % score)
file.write('person: %s ' % person)
file.write('\n')
except (IndentationError,UnicodeEncodeError):
continue except IndexError:
try:#detail可以分成三段
name = title.get_text().split()[0] # 书名
author = detail.get_text().split('/', 3)[0].split()[0] # 作者
intepretor = "" # 译者
publish = detail.get_text().split('/', 3)[1] # 出版社
time = detail.get_text().split('/', 3)[2].split()[0].split('-')[0] # 出版年份,只输出年
price = get_rmb_price2(detail) # 获取价格
score = score.get_text() if True else "" # 如果没有评分就置空
person = get_person(person) # 获得评分人数
#在控制台测试打印
test_print(name, author, intepretor, publish, time, price, score, person)
#将书籍信息写入txt文件
try:
file.write('name: %s ' % name)
file.write('author: %s ' % author)
file.write('intepretor: %s ' % intepretor)
file.write('publish: %s ' % publish)
file.write('time: %s ' % time)
file.write('price: %s ' % price)
file.write('score: %s ' % score)
file.write('person: %s ' % person)
file.write('\n')
except (IndentationError, UnicodeEncodeError):
continue except (IndexError,TypeError):
continue except TypeError:
continue
file file.write('\n')
file.close() #关闭文件 #程序执行入口
if __name__ == '__main__':
#url = "https://book.douban.com/tag/程序"
book_url_list = provide_url() #存放豆瓣所有分类标签页URL的列表
for url in book_url_list:
get_url_content(url) #解析每一个URL的内容
下面是效果图:
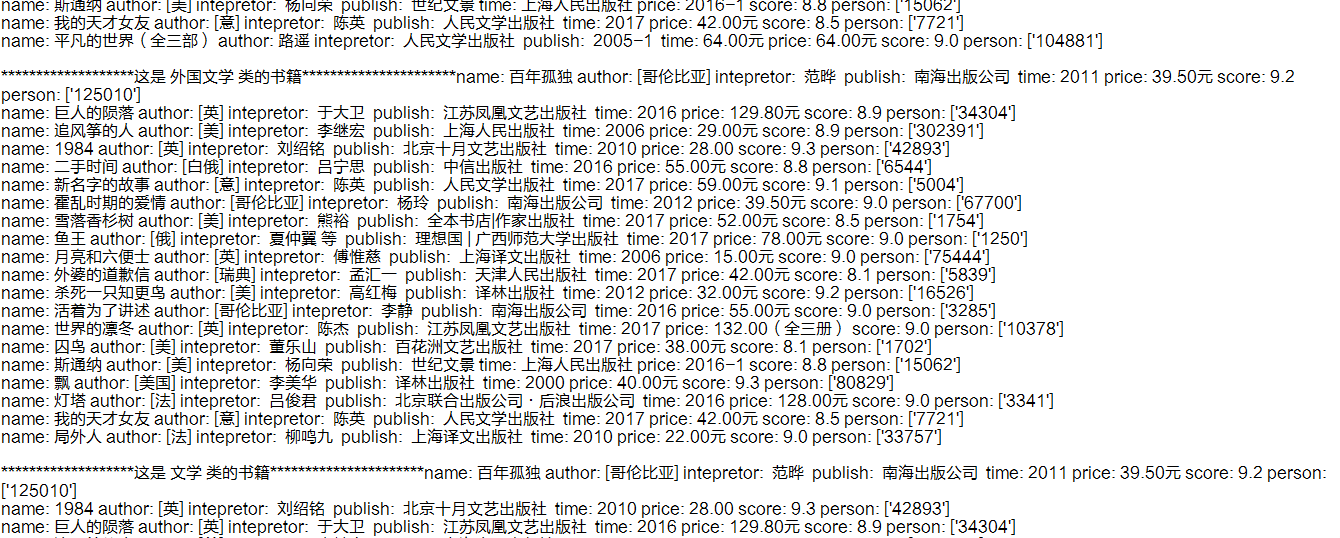
Python豆瓣书籍信息爬虫的更多相关文章
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- [Python] 豆瓣电影top250爬虫
1.分析 <li><div class="item">电影信息</div></li> 每个电影信息都是同样的格式,毕竟在服务器端是用 ...
- 豆瓣电影TOP250和书籍TOP250爬虫
豆瓣电影 TOP250 和书籍 TOP250 爬虫 最近开始玩 Python , 学习爬虫相关知识的时候,心血来潮,爬取了豆瓣电影TOP250 和书籍TOP250, 这里记录一下自己玩的过程. 电影 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
这一篇首先从allitebooks.com里抓取书籍列表的书籍信息和每本书对应的ISBN码. 一.分析需求和网站结构 allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页. ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
开始学习网络数据挖掘方面的知识,首先从Beautiful Soup入手(Beautiful Soup是一个Python库,功能是从HTML和XML中解析数据),打算以三篇博文纪录学习Beautiful ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- 【Python3爬虫】网络小说更好看?十四万条书籍信息告诉你
一.前言简述 因为最近微信读书出了网页版,加上自己也在闲暇的时候看了两本书,不禁好奇什么样的书更受欢迎,哪位作者又更受读者喜欢呢?话不多说,爬一下就能有个了解了. 二.页面分析 首先打开微信读书:ht ...
- Python爬取十四万条书籍信息告诉你哪本网络小说更好看
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TM0831 PS:如有需要Python学习资料的小伙伴可以加点击 ...
随机推荐
- Effective Java 读书笔记(一):创建和销毁对象
1 构造器 => 静态工厂方法 (1)优势 静态工厂方法有名字 静态工厂方法不必在每次被调用时都产生一个新的对象 静态工厂方法能返回原返回类型的任意子类型的对象 静态工厂方法根据调用时传入的不同 ...
- JQuery实现密码可见不可见
在Html页面上实现密码可见不可见,使用的阿里巴巴矢量图标库. html部分: <!doctype html> <html> <head> <meta cha ...
- ABP 基于DDD的.NET开发框架 学习(三)创建模块:任务管理
1.图标i获取:https://material.io/icons/查看2.js中创建如var _tenantService = abp.services.app.tenant;需清除页面的缓存,按c ...
- OpenSSL 1.1.1 国密算法支持
OpenSSL 1.1.1 国密算法支持 https://www.openssl.org/ https://github.com/openssl/openssl OpenSSL 1.1.1 新特性: ...
- 每周分享五个 PyCharm 使用技巧(三)
文章首发于 微信公众号:Python编程时光 PyCharm 是大多数 Python 开发者的首选 IDE,每天我们都在上面敲着熟悉的代码,写出一个又一个奇妙的功能. 一个每天都在使用的工具,如果能掌 ...
- 关于iview下拉菜单无法添加点击事件的解决办法
效果如下图所示,点击下拉菜单,点击退出,然后跳到登录界面 代码如下: <Dropdown trigger="click" style="margin-left: 2 ...
- c# dynamic实现动态实体,不用定义实体就能序列化为标准json
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.D ...
- Java 之 ObjectOutputStream 类
ObjectOutputStream 类 1.概述 java.io.ObjectOutputStream extends OutputStream ObjectOutputStream:对象的序列化流 ...
- arm9交叉编译工具链
Arm-linux-gcc: gcc和arm-linux-gcc的头文件并不一样. Eg. Arm-linux-ld:链接器,-T参数是使用链接器脚本. Eg. Arm-linux-readelf:读 ...
- java网络编程--httpurlconnection
HttpURLConnection是基于HTTP协议的,其底层通过socket通信实现.如果不设置超时(timeout),在网络异常的情况下,可能会导致程序僵死而不继续往下执行.可以通过以下两个语句来 ...