Spark之搜狗日志查询实战
1、下载搜狗日志文件:
地址:http://www.sogou.com/labs/resource/chkreg.php
2、利用WinSCP等工具将文件上传至集群。
3、创建文件夹,存放数据:
mkdir /home/usr/hadoopdata
4、将搜狗日志数据移到(mv命令)3中创建的目录下,并解压
tar -zxvf SogouQ.mini.tar.gz
5、查看解压后文件格式
file SogouQ.sample
显示:
不是UTF-8,用head/cat命名查看,中文乱码(影响后续进程),需对文件格式进行转换:
iconv -f gb2312 SogouQ.sample -o SogouQ.sample2
再次查看即可正常显示中文。

6、启动集群(Hadoop、spark)。启动后,进入hadoop安装目录下,在hdfs上新建存放数据的目录,并将5中已进行格式转换后的日志文件放到hdfs上,再查看文件是否上传成功,命令如下:
cd /home/usr/hadoop/hadoop-2.8.
hadoop fs -mkdir /sogoumini
hadoop fs -put /home/chenjj/hadoopdata/testdata/SogouQ.sample2 /sogoumini
hadoop fs -ls /sogoumini/SogouQ.sample2
结果:

7、进入spark安装目录下bin,启动spark-shell,由于本集群采用yarn模式部署的,故启动时选取yarn,其他参数可自行配置。
cd spark/spark-2.1.-bin-hadoop2./bin
./spark-shell --master yarn --executor-memory 2g --driver-memory 2g
8、进入spark-shell后,执行以下操作,在每句后面有说明
val path="hdfs:///sogoumini/SogouQ.sample2"——声明路径
val sogouminirdd=sc.textFile(path)——读取hdfs上搜狗日志文件
sogouminirdd.count()——查看文件总共多少条记录
val mapsogouminirdd=sogouminirdd.map(_.split("\\s")).filter(_.length==)——筛选出格式正确的数据
mapsogouminirdd.count()——查看格式正确的有多少条,是否所有数据均正确
val firstmapsogouminirdd=mapsogouminirdd.filter(_().toInt==).filter(_().toInt==)——筛选出当日搜索结果排名第一同时点击结果排名也是第一的数据量
firstmapsogouminirdd.count()——查看结果是第多少条数据
注:(1) 元数据文件格式和官网描述不一致问题,官方说明排名和用户点击的顺序号之间是以Tab键分隔的,而实际是以空格分隔。
解决方法: spark分词时用split("\\s")代替split("\t"))。
9、使用toDebugString查看RDD血统(lineage)
firstmapsogouminirdd.toDebugString
结果如下:
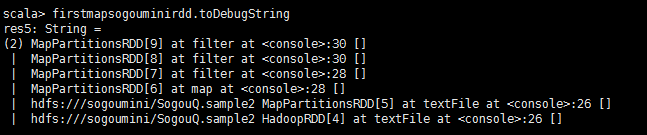
可见其血统关系是:HadoopRDD->MappedRDD->MappedRDD->FilteredRDD->FilteredRDD->FilteredRDD。
10、用户ID查询次数排行榜:
val sortrdd=mapsogouminirdd.map(x=>(x(),)).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
sortrdd.count()
11、将结果存放在hdfs中:
val outputpath="hdfs:///sogoumini/SogouQresult.txt"——存放路径及文件名
sortrdd.saveAsTextFile(outputpath)——存结果
Spark之搜狗日志查询实战的更多相关文章
- 使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- 使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用 pa ...
- 使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog import org.apache.hadoop.io.{LongWritable, Text} import org.apache.hadoop.mapred.Tex ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- 《图解Spark:核心技术与案例实战》介绍及书附资源
本书中所使用到的测试数据.代码和安装包放在百度盘提供 下载 ,地址为https://pan.baidu.com/s/1o8ydtKA 密码:imaa 另外在百度盘提供本书附录 下载 ,地址为http ...
- 《图解Spark:核心技术与案例实战》作者经验谈
1,看您有维护博客,还利用业余时间著书,在技术输出.自我提升以及本职工作的时间利用上您有没有什么心得和大家分享?(也可以包含一些您写书的小故事.)回答:在工作之余能够写博客.著书主要对技术的坚持和热爱 ...
- Spark Streaming 进阶与案例实战
Spark Streaming 进阶与案例实战 1.带状态的算子: UpdateStateByKey 2.实战:计算到目前位置累积出现的单词个数写入到MySql中 1.create table CRE ...
- 日志检索实战 grep sed
日志检索实战 grep sed 参考 sed命令 使用 grep -5 'parttern' inputfile //打印匹配行的前后5行 grep -C 5 'parttern' inputfile ...
- Spark SQL知识点大全与实战
Spark SQL概述 1.什么是Spark SQL Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块. 与基本的Spark RDD API不同,Sp ...
随机推荐
- Best Coder #86 1002 NanoApe Loves Sequence
NanoApe Loves Sequence Accepts: 531 Submissions: 2481 Time Limit: 2000/1000 MS (Java/Others) Memory ...
- 面向亿万级用户的QQ一般做什么?——兴趣部落的Web同构直出分享
作者:李强,腾讯web开发工程师 商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处. 原文链接:http://wetest.qq.com/lab/view/348.html 一.什么是同构 ...
- 【最新版】从零开始在 macOS 上配置 Lua 开发环境
脚本语言,你可能更需要的是 Lua 不同的脚本语言有不同的特性,第一接触的脚本语言,可能会影响自己对整个脚本语言的理解和认知.我以前接触最多的脚本语言是 JavaScript.后果就是:我一度以为脚本 ...
- 第三方软件内嵌IE出现纵向滚动条消失的BUG,奇葩的IE BUG 真是无奇不有
混了这么久 竟然还有这样难以解决的BUG,最后都跑到英文的MSDN上提问了,因为谷歌都谷不出朕的忧伤了,有木有. 提问原文如下:https://social.msdn.microsoft.com/Fo ...
- thinkphp后台ajaxReturn提示下载的问题
thinkphp新版设置了ajaxreturn方法如果是JSON格式会自动设置头信息为JSON格式,这样做在谷歌下可以正常解析,但是在IE和OPERA浏览器下就会提示下载,从而导致程序出错,修改方法如 ...
- Power BI本地部署(10月正式版)
Power BI安装环境要求 Windows 7/Windows Server 2008 R2 或更高版本 .NET 4.5 或更高版本 Internet Explorer 9 或更高版本 内存 (R ...
- 记录一次Session偶尔获取不到的解决过程
导读 平台下某子系统有密码登录需求,初步考虑用Session,登录后设置Session[key]=value;Session中若某key对应的Session,即Session[key]为null则限制 ...
- C#Session丢失问题的解决办法
关于c# SESSION丢失问题解决办法 我们在用C#开发程序的时候经常会遇到Session很不稳定,老是数据丢失.下面就是Session数据丢失的解决办法希望对您有好处.1.在WEB.CONFI ...
- requests和BeautifulSoup
一:Requests库 Requests is an elegant and simple HTTP library for Python, built for human beings. 1.安装 ...
- [转]分布式消息中间件 MetaQ 作者庄晓丹专访
MetaQ(全称Metamorphosis)是一个高性能.高可用.可扩展的分布式消息中间件,思路起源于LinkedIn的Kafka,但并不是Kafka的一个Copy.MetaQ具有消息存储顺序写.吞吐 ...