跟我学算法聚类(kmeans)
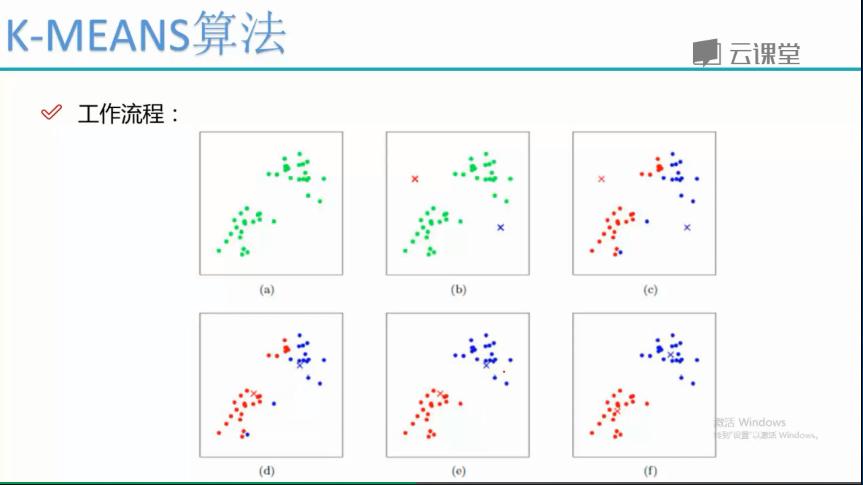
kmeans是一种无监督的聚类问题,在使用前一般要进行数据标准化, 一般都是使用欧式距离来进行区分,主要是通过迭代质心的位置
来进行分类,直到数据点不发生类别变化就停止,
一次分类别,一次变换质心,就这样不断的迭代下去
优势:使用方便
劣势:1.K值难确定
2. 复杂度与样本数量呈线性关系
3.很难发现形状任意的簇
4.容易受初始点的影响
python中使用 sklearn.cluster 模块,使用的时候需要指定参数
第一步:导入数据,提取数据中的变量保存为X
import pandas as pd
beer = pd.read_csv('data.txt', sep=' ') X = beer[["calories","sodium","alcohol","cost"]]
第二步:进行kmans聚类分析
from sklearn.cluster import KMeans km = KMeans(n_clusters=3).fit(X) #聚成三蔟
km2 = KMeans(n_clusters=2).fit(X) #聚成两蔟 beer['cluster'] = km.labels_ #返回聚类的标签结果
beer['cluster2'] = km2.labels_ beer.sort_values('cluster') #根据'cluster'进行排序
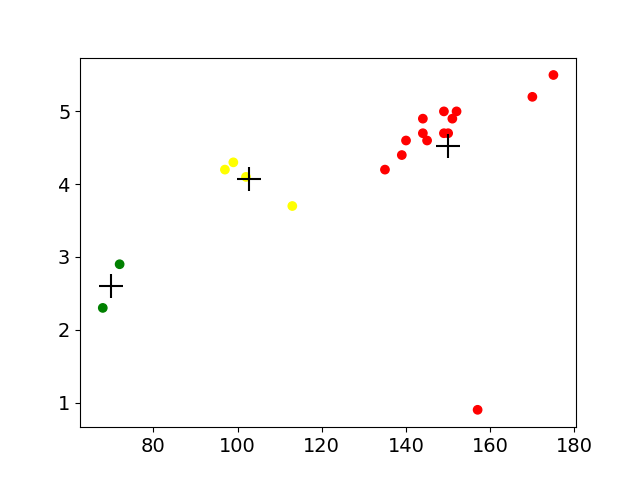
第三步:根据分类结果画出带颜色的散点图,及其混淆矩阵
from pandas.tools.plotting import scatter_matrix
cluster_center = km.cluster_centers_
cluster_center_2 = km2.cluster_centers_
# print(beer.groupby('cluster').mean()) #groupby进行快速分组,mean求平均
#
# print(beer.groupby('cluster2').mean())
centers = beer.groupby("cluster").mean().reset_index() #reset_index()重新添加了序号
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 14 #rcParams 用于修改字体的大小
import numpy as np
color = np.array(['red', 'green', 'yellow', 'blue'])
plt.scatter(beer['calories'], beer['alcohol'], c=color[beer['cluster']])
plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=300, c='black')
scatter_matrix(beer[["calories","sodium","alcohol","cost"]], s=100,alpha = 1 ,c=color[beer['cluster']],\
figsize=(10, 10)) #alpha 代表不透明的意思
plt.suptitle("With 3 centroids initialized")
plt.show()

第四步:对数据进行标准化,再进行kmeans聚类
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaler = scaler.fit_transform(X) #进行转换
new_X_scaler = pd.DataFrame(X_scaler, columns=["calories","sodium","alcohol","cost"]) km = KMeans(n_clusters=3).fit(X_scaler) beer['scaler_cluster'] = km.labels_ beer.sort_values('scaler_cluster') print(beer.groupby('scaler_cluster').mean()) scatter_matrix(new_X_scaler, alpha = 1 ,c=color[beer.scaler_cluster]) plt.show()
第五步:为了比较处理前后的效果,我们引入了轮廓系数 metrics.silhouette_score,发现未标准化的分类结果要好于标准化
from sklearn import metrics
score_scaled = metrics.silhouette_score(X,beer.scaler_cluster)
score = metrics.silhouette_score(X,beer.cluster)
print(score_scaled, score)
第六步: 我们使用轮廓系数(b(i)-a(i))/max(b(i), a(i)), b(i)一个点到自己蔟的距离,a(i)表示一个点到其他蔟的距离,来挑选蔟的参数n_clusters
scores = []
for i in range(2, 15): print(metrics.silhouette_score(X,KMeans(n_clusters=i).fit(X).labels_)) #X变量,KMeans(n_clusters=i).fit(X).labels_分类得到的标签
scores.append(metrics.silhouette_score(X,KMeans(n_clusters=i).fit(X).labels_)) plt.plot(list(range(2, 15)), scores) plt.xlabel('迭代次数') plt.ylabel('轮廓系数') plt.show()

跟我学算法聚类(kmeans)的更多相关文章
- 推荐算法-聚类-K-MEANS
对于大型的推荐系统,直接上协同过滤或者矩阵分解的话可能存在计算复杂度过高的问题,这个时候可以考虑用聚类做处理,其实聚类本身在机器学习中也常用,属于是非监督学习的应用,我们有的只是一组组数据,最终我们要 ...
- 跟我学算法聚类(DBSCAN)
DBSCAN 是一种基于密度的分类方法 若一个点的密度达到算法设定的阖值则其为核心点(即R领域内点的数量不小于minPts) 所以对于DBSCAN需要设定的参数为两个半径和minPts 我们以一个啤酒 ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- [数据挖掘] - 聚类算法:K-means算法理解及SparkCore实现
聚类算法是机器学习中的一大重要算法,也是我们掌握机器学习的必须算法,下面对聚类算法中的K-means算法做一个简单的描述: 一.概述 K-means算法属于聚类算法中的直接聚类算法.给定一个对象(或记 ...
- 浅谈聚类算法(K-means)
聚类算法(K-means)目的是将n个对象根据它们各自属性分成k个不同的簇,使得簇内各个对象的相似度尽可能高,而各簇之间的相似度尽量小. 而如何评测相似度呢,采用的准则函数是误差平方和(因此也叫K-均 ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- 机器学习-聚类-k-Means算法笔记
聚类的定义: 聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小,它是无监督学习. 聚类的基本思想: 给定一个有N个对象的数据集 ...
- 机器学习聚类算法之K-means
一.概念 K-means是一种典型的聚类算法,它是基于距离的,是一种无监督的机器学习算法. K-means需要提前设置聚类数量,我们称之为簇,还要为之设置初始质心. 缺点: 1.循环计算点到质心的距离 ...
随机推荐
- Jmeter-BeanShell Sampler调用java代码
1.添加BeanShell Sampler 2.编写BeanShell Sampler代码 3.引用参数 ${id}
- AngularX 路由总结
路由是 Angular 应用程序的核心,它加载与所请求路由相关联的组件,以及获取特定路由的相关数据.这允许我们通过控制不同的路由,获取不同的数据,从而渲染不同的页面. Installing the r ...
- Luogu3387 缩点 【tarjan】【DP】
Luogu3387 缩点 题目背景 缩点+DP 题目描述 给定一个n个点m条边有向图,每个点有一个权值,求一条路径,使路径经过的点权值之和最大.你只需要求出这个权值和. 允许多次经过一条边或者一个点, ...
- C# 中那些可以被重载的运算符,以及使用它们的那些丧心病狂的语法糖
C# 中的操作符重载并不新鲜.然而,到底有哪些操作符可以重载,重载操作符可以用来做哪些丧心病狂的事情呢? 本文收集了 C# 中所有可以重载的操作符,并且利用他们做了一些丧心病狂的语法糖. 可以重载 ...
- 深入了解 WPF Dispatcher 的工作原理(PushFrame 部分)
在上一篇文章 深入了解 WPF Dispatcher 的工作原理(Invoke/InvokeAsync 部分) 中我们发现 Dispatcher.Invoke 方法内部是靠 Dispatcher.Pu ...
- windows下PyCharm运行和调试scrapy
Scrapy是爬虫抓取框架,Pycharm是强大的python的IDE,为了方便使用需要在PyCharm对scrapy程序进行调试 python PyCharm Scrapy scrapy指令其实就是 ...
- Linux安装vsftpd总结
我使用的是CentOS6安装的vsftpd,转载请注明出处,以下是我的记录: #查看是否已经安装了vsfptd vsftpd -v #安装 yum -y install vsftpd #创建:chro ...
- c++中子类转父类,父类转子类
#include <iostream> using namespace std; class Father { public: virtual void show() { cout< ...
- poj 2187 Beauty Contest——旋转卡壳
题目:http://poj.org/problem?id=2187 学习材料:https://blog.csdn.net/wang_heng199/article/details/74477738 h ...
- bzoj 2535 && bzoj 2109 [Noi2010]Plane 航空管制——贪心
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=2535 https://www.lydsy.com/JudgeOnline/problem.p ...