大数据【八】Flume部署
如果说大数据中分布式收集日志用的是什么,你完全可以回答Flume!(面试小心问到哦)
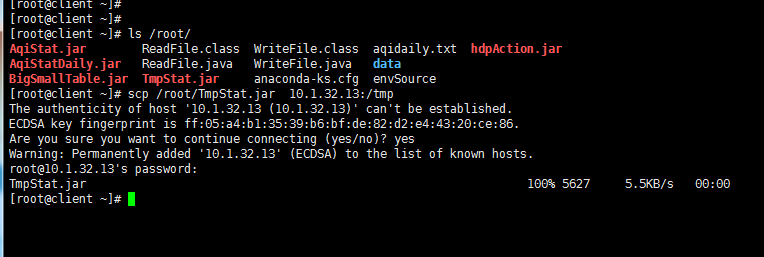
首先说一个复制本服务器文件到目标服务器上,需要目标服务器的ip和密码:
命令: scp filename ip:目标路径
一 概述
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据现在由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
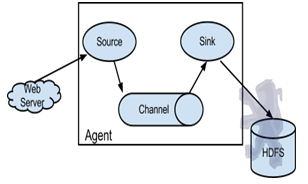
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成。
二 启动Flume集群
1‘ 首先,启动Hadoop集群(详情见前博客)。
2’ 其次,(剩下的所有步骤只需要在master上操作就可以了)安装并配置Flume任务,内容如下:
将Flume 安装包解压到/usr/cstor目录,并将flume目录所属用户改成root:root。
tar -zxvf flume-1.5.2.tar.gz -c /usr/cstor
chown -R root:root /usr/cstor/flume
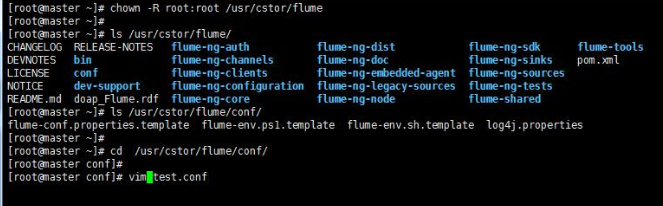
3‘ 进入解压目录下,在conf目录下新建test.conf文件并添加以下配置内容:
#定义agent中各组件名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
# source1组件的配置参数
agent1.sources.source1.type=exec
#此处的文件/home/source.log需要手动生成,见后续说明
agent1.sources.source1.command=tail -n +0 -F /home/source.log
# channel1的配置参数
agent1.channels.channel1.type=memory
agent1.channels.channel1.capacity=1000
agent1.channels.channel1.transactionCapactiy=100
# sink1的配置参数
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:8020/flume/data
agent1.sinks.sink1.hdfs.fileType=DataStream
#时间类型
agent1.sinks.sink1.hdfs.useLocalTimeStamp=true
agent1.sinks.sink1.hdfs.writeFormat=TEXT
#文件前缀
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d-%H-%M
#60秒滚动生成一个文件
agent1.sinks.sink1.hdfs.rollInterval=60
#HDFS块副本数
agent1.sinks.sink1.hdfs.minBlockReplicas=1
#不根据文件大小滚动文件
agent1.sinks.sink1.hdfs.rollSize=0
#不根据消息条数滚动文件
agent1.sinks.sink1.hdfs.rollCount=0
#不根据多长时间未收到消息滚动文件
agent1.sinks.sink1.hdfs.idleTimeout=0
# 将source和sink 绑定到channel
agent1.sources.source1.channels=channel1
agent1.sinks.sink1.channel=channel1
4' 然后,在HDFS上创建/flume/data目录:
cd /usr/cstor/hadoop/bin
./hdfs dfs -mkdir /flume
./hdfs dfs -mkdir /flume/data
5' 最后,进入Flume安装的bin目录下
cd /usr/cstor/flume/bin
6' 启动Flume,开始收集日志信息。
./flume-ng agent --conf conf --conf-file /usr/cstor/flume/conf/test.conf --name agent1 -Dflume.root.logger=DEBUG,console
!!!>>运行此命令有时候会出现一个权限问题,此时需要用命令 chmod o+x flume-ng
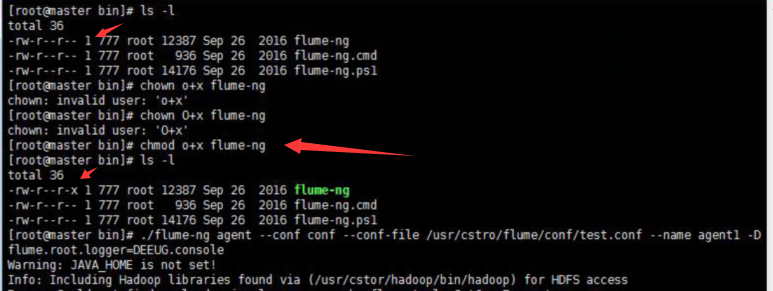
如果正常运行,最后悔显示 started,如图:
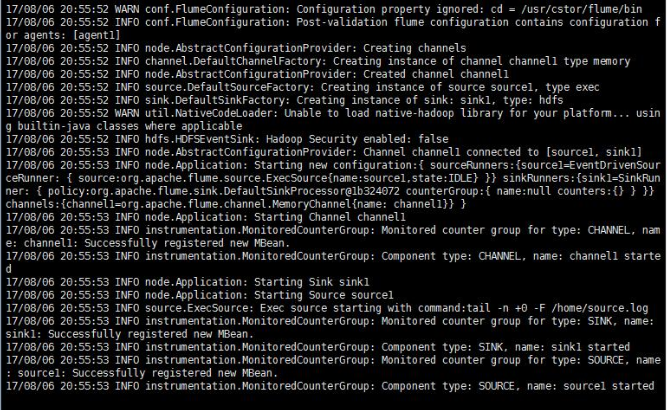
三 收集日志
1’ 启动成功之后需要手动生成消息源即配置文件中的/home/source.log,使用如下命令去不断的写入文字到/home/source.log中:

2' 到此就可以去查看生成结果:
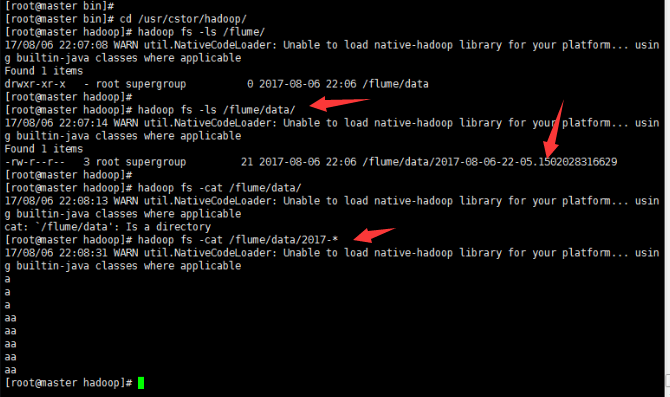
小结:
这只是配置Flume,然后简单的读写日志。想要深入下去,还要收集更复杂,更庞大的日志。
大数据【八】Flume部署的更多相关文章
- 大数据(9) - Flume的安装与使用
Flume简介 --(实时抽取数据的工具) 1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. 2) Flume基于流式架构 ...
- FusionInsight大数据开发---Flume应用开发
Flume应用开发 要求: 了解Flume应用开发适用场景 掌握Flume应用开发 Flume应用场景Flume的核心是把数据从数据源收集过来,在送到目的地.为了保证输送一定成功,发送到目的地之前,会 ...
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- Redis安装,mongodb安装,hbase安装,cassandra安装,mysql安装,zookeeper安装,kafka安装,storm安装大数据软件安装部署百科全书
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/server-sofeware-install.html 一.安装mongodb 官网下载包mongo ...
- 大数据之Flume
什么是Flume ApacheFlume是一个分布式的.可靠的.可用的系统,用于高效地收集.聚合和将大量来自不同来源的日志数据移动到一个集中的数据存储区. 系统要求 1. JDK 1.8 或以上版本 ...
- 大数据学习——flume日志分类采集汇总
1. 案例场景 A.B两台日志服务机器实时生产日志主要类型为access.log.nginx.log.web.log 现在要求: 把A.B 机器中的access.log.nginx.log.web.l ...
- 大数据学习——flume拦截器
flume 拦截器(interceptor)1.flume拦截器介绍拦截器是简单的插件式组件,设置在source和channel之间.source接收到的事件event,在写入channel之前,拦截 ...
- 入门大数据---通过Flume、Sqoop分析日志
一.Flume安装 参考:Flume 简介及基本使用 二.Sqoop安装 参考:Sqoop简介与安装 三.Flume和Sqoop结合使用案例 日志分析系统整体架构图: 3.1配置nginx环境 请参考 ...
- 最新版大数据平台安装部署指南,HDP-2.6.5.0,ambari-2.6.2.0
一.服务器环境配置 1 系统要求 名称 地址 操作系统 root密码 Master1 10.1.0.30 Centos 7.7 Root@bidsum1 Master2 10.1.0.105 Cent ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
随机推荐
- JDK8 - Function介绍
注:写这个文档只是为了方便加深记忆,加强理解,重点关注两个default方法中泛型[V]. JDK8作为一个还在维护阶段的长期版本,势必会在企业应用中占据相当大的市场份额,所以还是以JDK8作为例子的 ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装用来定时任务apscheduler库(图文详解)
不多说,直接上干货! Anaconda2 里 PS C:\Anaconda2\Scripts> PS C:\Anaconda2\Scripts> pip.exe install apsc ...
- linux less命令详情
less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大.less 的用法比起 more .tail更加的有弹性.在 more 的时候,我们并没有办 ...
- Java NIO系列教程(七) FileChannel
Java NIO中的FileChannel是一个连接到文件的通道.可以通过文件通道读写文件. FileChannel无法设置为非阻塞模式,它总是运行在阻塞模式下. 打开FileChannel 在使用F ...
- VMware ESX常用命令
一. VMware ESX Command 1. 看你的esx版本 vmware –v 2. 查看显示ESX硬件,内核,存储,网络等信息 esxcfg-info -a(显示所有相关的信息) esxcf ...
- eclipse安装quick text search插件,全文搜索
主要有两种方法 1.InstaSearch 同样可以做到workspace下的全文搜索 可以使用eclipse marktplace中搜索instaSearch,与普通软件安装类似 安装成功后的界面如 ...
- k-近邻算法(KNN)
最近邻算法可以说是最简单的分类算法,其思想是将被预测的项归类为和它最相近的项相同的类.我们通过简单的计算比较即将被预测的项与已有训练集中各项的距离(差距),选择其中差距最小的一项,该项的类别即为我们即 ...
- nodejs项目总结
前几天花了3天时间,搭建.开发了一个包含客户端.cms.server端的项目,也因着以前有php的开发经验,以及sql的设计和应用能力,倒也没遇到什么阻碍.至于项目结构搭建(架构),也是共通的,以模块 ...
- 【学习笔记】浅析Promise函数
一.Promise是什么? 在JavaScript中,所有的代码都是单线程执行,所以javaScript的所有网络操作(“GET”/"POST"/"PUT"/& ...
- 使用EntityManager批量保存数据
@PersistenceContext EntityManager em; 从别的系统中定期同步某张表的数据,由于数据量较大,采用批量保存 JPA EntityManager的四个主要方法 ① pub ...