五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门

我的搜素简单实现原理
我们可以用js来实现,首先用js获取到输入的搜索词
设置一个数组里存放搜素词,
判断搜索词在数组里是否存在如果存在删除原来的词,重新将新词放在数组最前面
如果不存在直接将新词放在数组最前面即可,然后循环数组显示结果即可
热门搜索
实现原理,当用户搜索一个词时,可以保存到数据库,然后记录搜索次数,
利用redis缓存搜索次数最到的词,过一段时间更新一下缓存
备注:Django结合Scrapy的开源项目可以学习一下
django-dynamic-scraper
https://github.com/holgerd77/django-dynamic-scraper
补充
默认的elasticsearch(搜索引擎)只能搜索1万条数据,在大就会报错了
设置方法
步骤一:
打开项目的索引库地址,将该索引先关闭,否则设置操步骤二无法提交
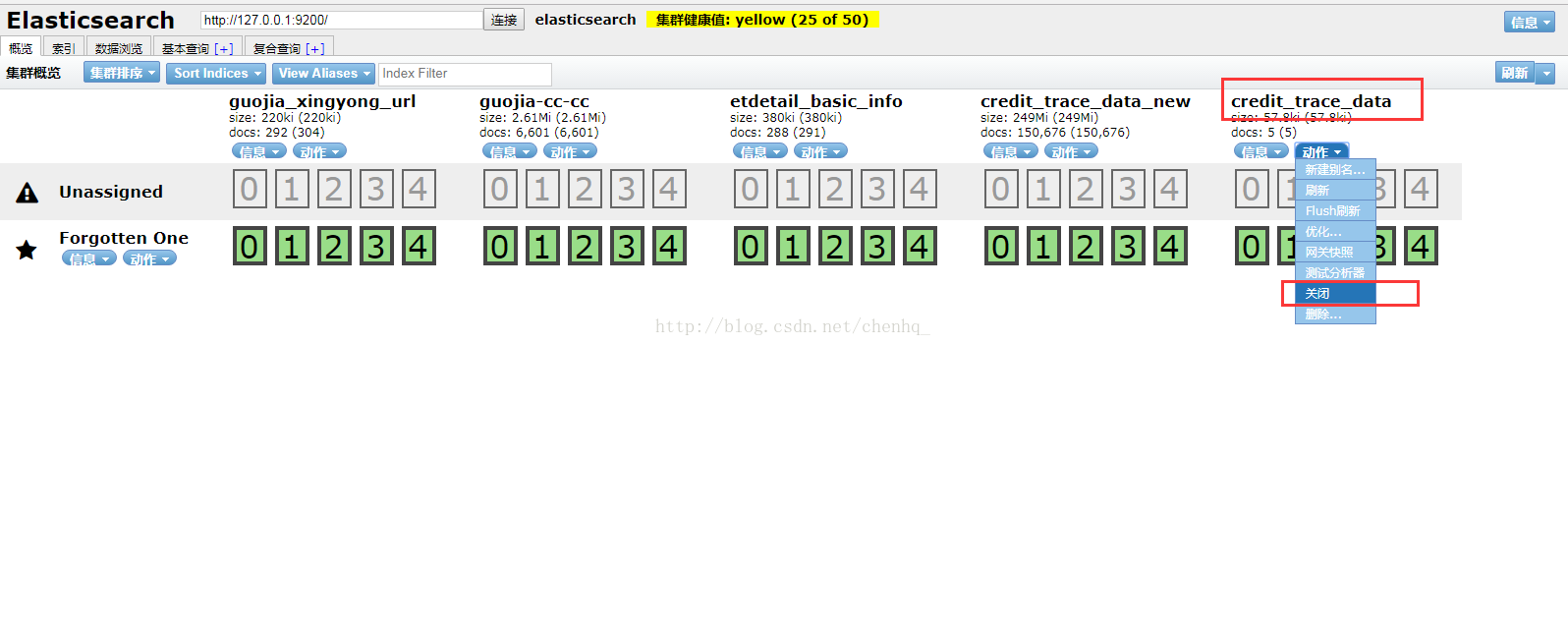
步骤二:
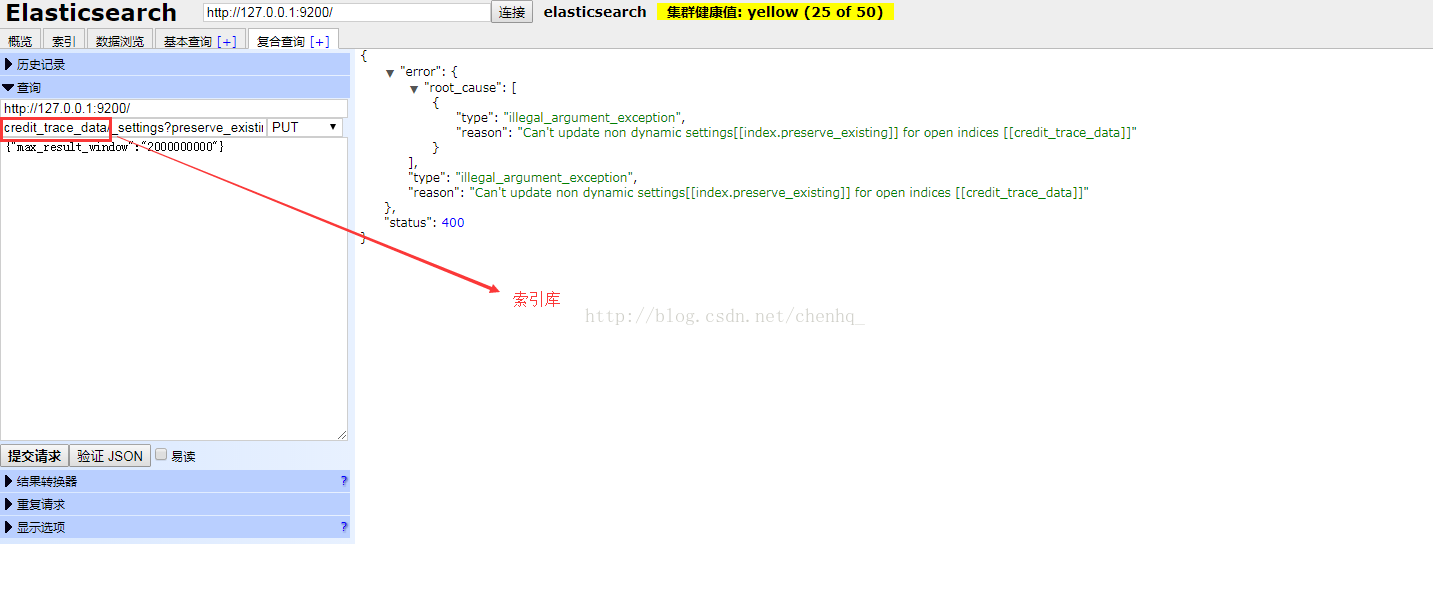
打开复合查询,填入如下信息,记得选择PUT方式提交,credit_trace_data改为本索引库中的索引,max_result_window设为20亿,此值是integer类型,不能无限大
http://127.0.0.1:9200/ PUT
credit_trace_data/_settings?preserve_existing=true
{
"max_result_window" : "2000000000"
}
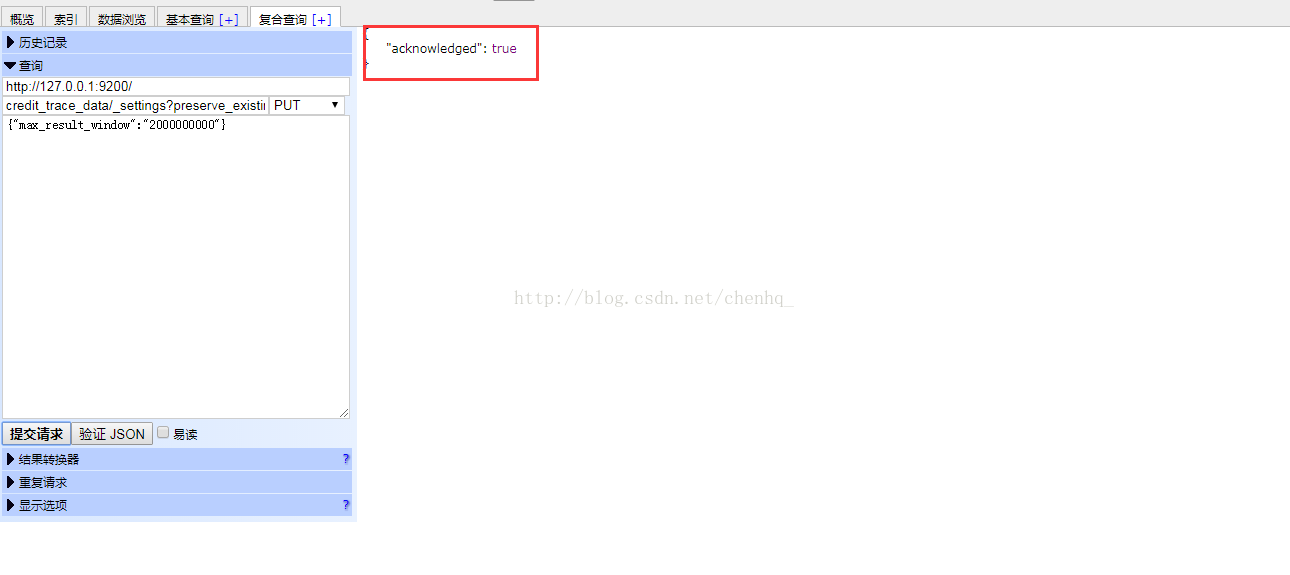
最后点击提交申请,如果配置正确右侧窗口会显示如下信息
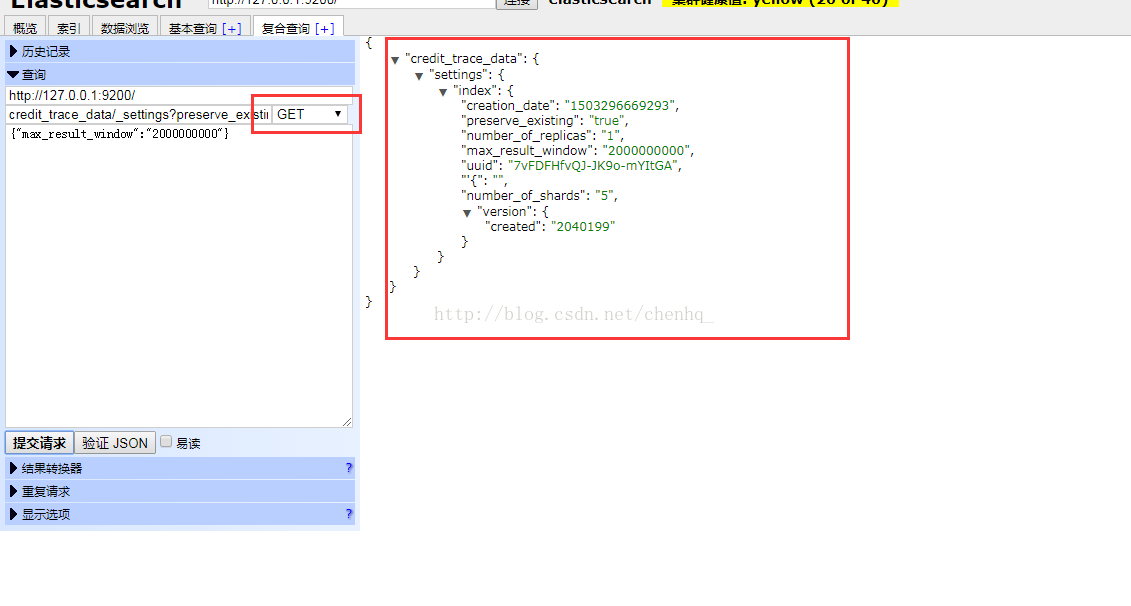
如果要查询max_result_window时只需要将PUT改为get即可
最后记得开启索引!
五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索的更多相关文章
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- Java 语言基础之函数
函数的定义: 函数就是定义在类中的具有特定功能的一段独立小程序 函数也称为方法 函数定义格式: 修饰符 返回值类型 函数名(参数类型 形式参数1, 参数类型 形式参数2,...) { 执行语句; re ...
- XP系统中IIS访问无法显示网页,目前访问网站的用户过多。终极解决办法
无法显示网页 目前访问网站的用户过多. -------------------------------------------------------------------------------- ...
- elastic search远程测试
elastic search远程测试 推荐:elastic官方教程:https://www.elastic.co/guide/en/elasticsearch/reference/6.2/index. ...
- 洛谷 [BJOI2012]最多的方案
洛谷 这题是旁边同学介绍的,听他说记忆化搜索可以过... 不过我还是老老实实的想\(dp\)吧- 先看看数据范围,\(n\leq10^{18}\)相当于\(n \leq fib[86]\). 以前打\ ...
- Android之网络----使用HttpClient发送HTTP请求(通过get方法获取数据)
[正文] 一.HTTP协议初探: HTTP(Hypertext Transfer Protocol)中文 "超文本传输协议",是一种为分布式,合作式,多媒体信息系统服务,面向应用层 ...
- 大家一起来学 NHibernate+NUnit (VS2012+SQL Server2008)
大家一起来学 NHibernate+NUnit (VS2012+SQL Server2008) 分类: C#2013-08-10 18:47 1589人阅读 评论(5) 收藏 举报 NHibernat ...
- php 内存泄漏
所谓内存泄漏是指进称在执行过程中,内存的占有率逐步升高,不释放, 系统所拥有的可用内存越来越少的现象. php-fpm耗光内存,不释放,就是所谓的内存泄漏,内存泄漏对长期运行的程序有威胁,所以应该定期 ...
- hadoop26----netty,多个handler
k客户端: package cn.itcast_03_netty.sendorder.client; import io.netty.bootstrap.Bootstrap; import io.ne ...
- systemverilog中module与program的区别
我们知道,verilog语法标准中是没有program的,program是systemverilog语法标准新增的内容. 那么,为什么要新增一个program呢?主要考量是基于电路的竞争与冒险. 为避 ...
- Cocos2d-x项目移植到WP8系列之九:使用自定义shader
本文原链接:http://www.cnblogs.com/zouzf/p/3995132.html 有时候想得到一些例如灰度图等特殊的渲染效果,就得用到自定义shader,关于shader的一些背景知 ...