scrapy-splash抓取动态数据例子四
一、介绍
本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息。
给定关键字:打通;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
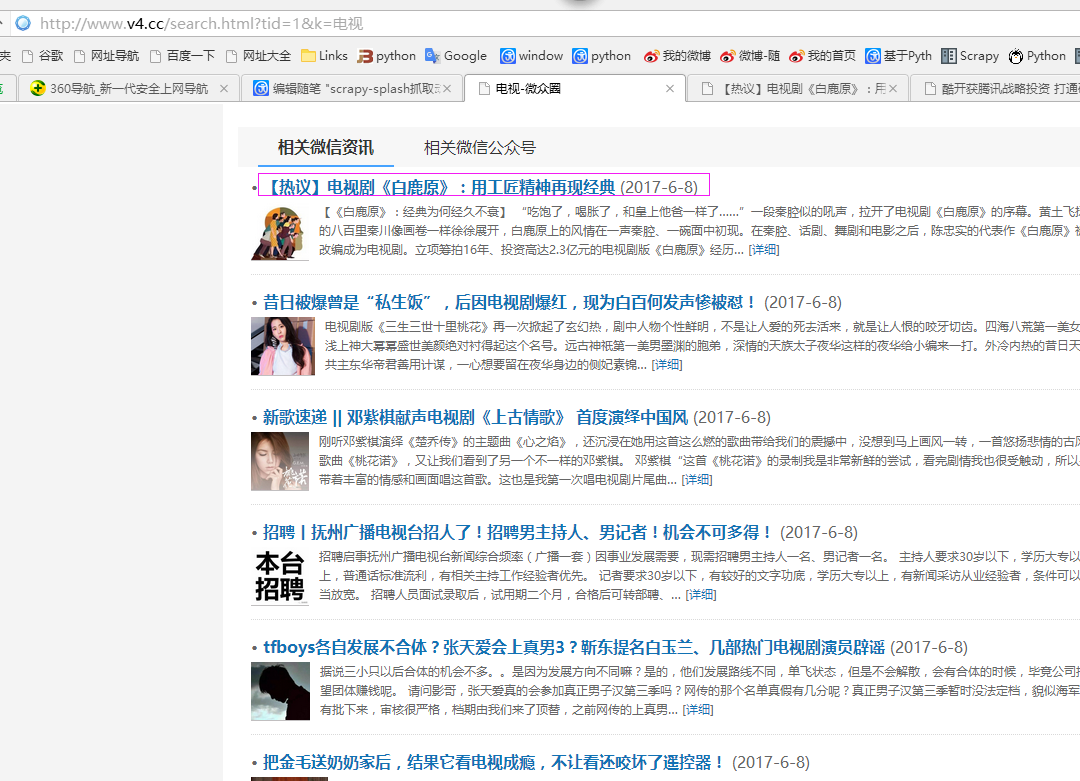

三、数据抓取
针对上面的网站信息,来进行抓取
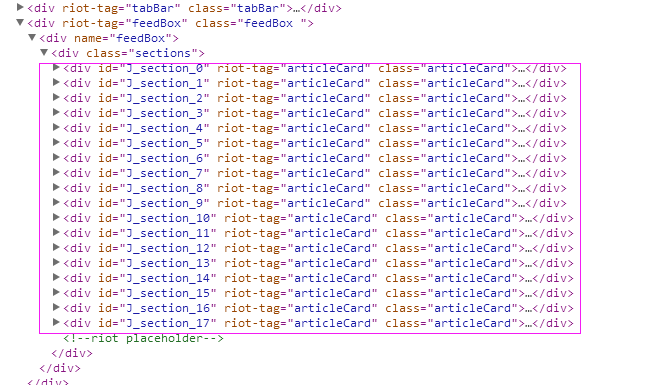
1、首先抓取信息列表
抓取代码:sels = site.xpath('//li[@class="itemtitle"]')
2、抓取标题
首先列表页面,根据标题和日期来判断是否自己需要的资讯,如果是,就今日到资讯对应的链接,来抓取来源,如果不是,就不用抓取了
抓取代码:titles = sel.xpath('.//text()')
title =str(titles[1].extract())
3、抓取链接
抓取代码:url = 'http://www.v4.cc'+ str(sel.xpath('.//a/@href')[0].extract())
4、抓取日期
抓取代码:flag,date =self.date_isValid(str(titles[2].extract()))
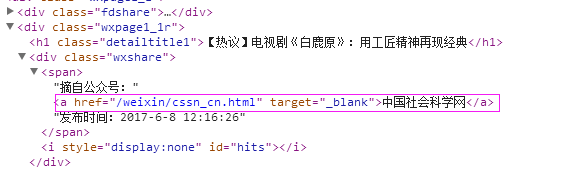
5、抓取来源
抓取代码:sources = site.xpath('//div[@class="wxshare"]/span/a/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') sys.stdout = open('output.txt', 'w') class weizhongquanSpider(Spider):
name = 'weizhongquan' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_keywords = cf.GetValue("section", "information_keywords")
information_wordlist = information_keywords.split(';')
websearchurl = cf.GetValue("weizhongquan", "websearchurl")
start_urls = []
for word in information_wordlist:
start_urls.append(websearchurl + word) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
index = url.rfind('=')
yield SplashRequest(url
, self.parse
, args={'wait': ''},
meta={'keyword': url[index + 1:]}
) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate,strDate[0])==0:
return True,currentDate
return False, ''
def parse(self, response):
site = Selector(response)
keyword = response.meta['keyword']
sels = site.xpath('//li[@class="itemtitle"]')
for sel in sels:
titles = sel.xpath('.//text()')
title =str(titles[1].extract())
flag,date =self.date_isValid(str(titles[2].extract()))
if flag and title.find(keyword)>-1:
url = 'http://www.v4.cc'+ str(sel.xpath('.//a/@href')[0].extract())
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword,'title':title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//div[@class="wxshare"]/span/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
return it
scrapy-splash抓取动态数据例子四的更多相关文章
- scrapy-splash抓取动态数据例子十四
一.介绍 本例子用scrapy-splash爬取超级TV网站的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4. ...
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
随机推荐
- ubuntu 软件包(package)更换源(source)为阿里云镜像 update&upgrade
在ubuntu下用apt-get install安装软件时,发现package list中没有所需的软件, 估计可能是package list太旧了,于是需要apt-get update & ...
- FFT模板 生成函数 原根 多项式求逆 多项式开根
FFT #include<iostream> #include<cstring> #include<cstdlib> #include<cstdio> ...
- highcharts高级画图柱状图和折线图
折线图一枚 $("#z_line").highcharts({ chart: { type: 'line' }, credits: { enabled: false // 禁用版权 ...
- 利用tengine的nginx_upstream_check_module来检测后端服务状态
nginx_upstream_check_module 是专门提供负载均衡器内节点的健康检查的外部模块,由淘宝的姚伟斌大神开发,通过它可以用来检测后端 realserver 的健康状态.如果后端 re ...
- 从TS流定位H264的每一个视频帧开始,判断出帧类型
从TS流定位H264的每一个视频帧开始,判断出帧类型(待续)
- Sonar常见的审查结果
格式:问题名字+问题出现的次数 Resources should be closed2 资源未关闭,打开发现有两处用到的IO流没有关闭 Conditions should not unconditio ...
- 最短路-Bellmanford
简介: 给定一个图和一个源点,求源点到其余点的最短路径,图中有可能存在负权边. 算法步骤 1.初始化:将除源点外的所有顶点的最短距离估计值 dist[v] ← +∞, dist[s] ←0; 2.迭代 ...
- Bootstrap 实现CRUD示例及代码
https://github.com/wenzhixin/bootstrap-table-examples/blob/master/crud/index.html <!DOCTYPE html& ...
- js中__proto__和prototype的区别和关系
首先,要明确几个点:1.在JS里,万物皆对象.方法(Function)是对象,方法的原型(Function.prototype)是对象.因此,它们都会具有对象共有的特点.即:对象具有属性_ ...
- python中join函数的用法
这个函数可以对字符串按照某种方式进行拼接,比如你要在三个字母中间都添加一个特定字符,就可以用这个函数实现 result = '*'.join(['A','B','C']) print(result) ...