【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览
from selenium import webdriver
from time import sleep # 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的
driver = webdriver.Chrome(r'C:\Python34\chromedriver_x64.exe')
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text('设置')[0].click()
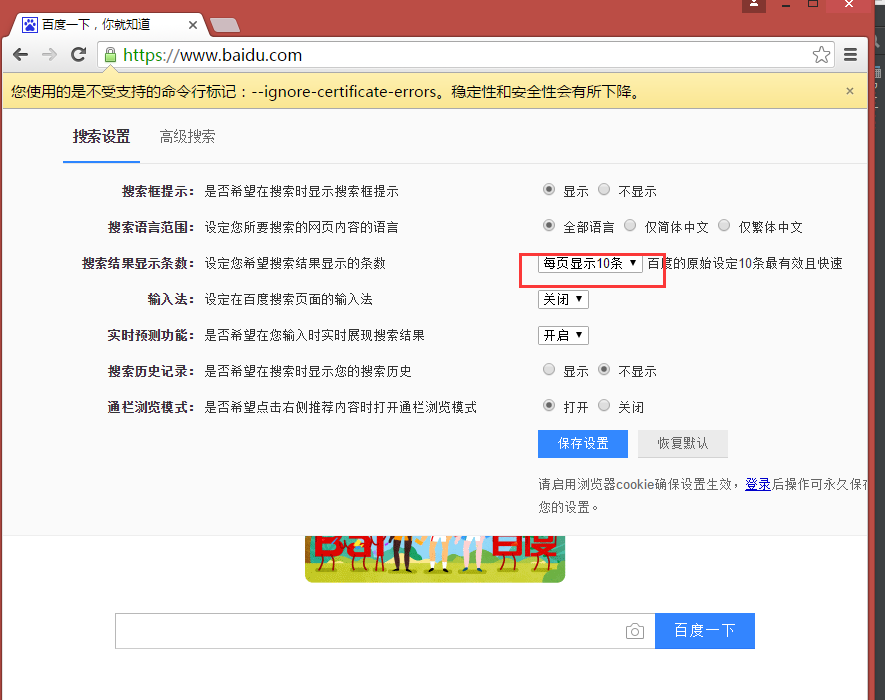
# 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text('搜索设置')[0].click()
sleep(2)
m = driver.find_element_by_id('nr')
sleep(2)
m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
sleep(2)
# 处理弹出的警告页面
driver.find_element_by_class_name("prefpanelgo").click()
sleep(2)
driver.switch_to_alert().accept()
sleep(2)
# 找到百度的输入框,并输入“selenium”
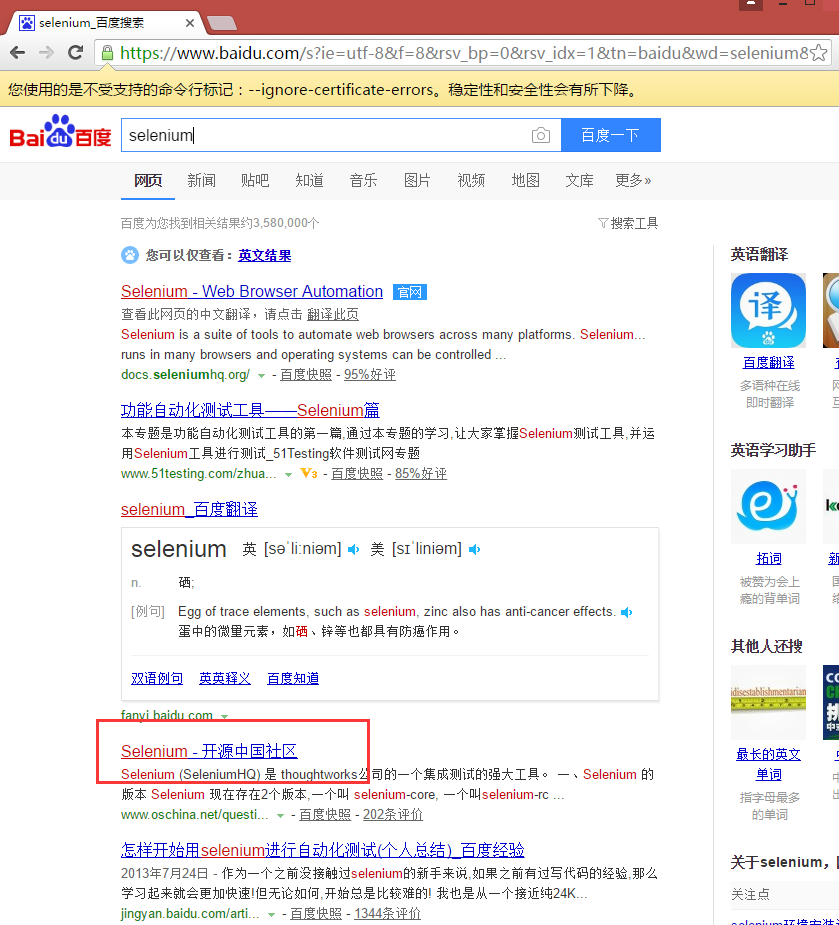
driver.find_element_by_id('kw').send_keys('selenium')
sleep(2)
# 点击搜索按钮
driver.find_element_by_id('su').click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
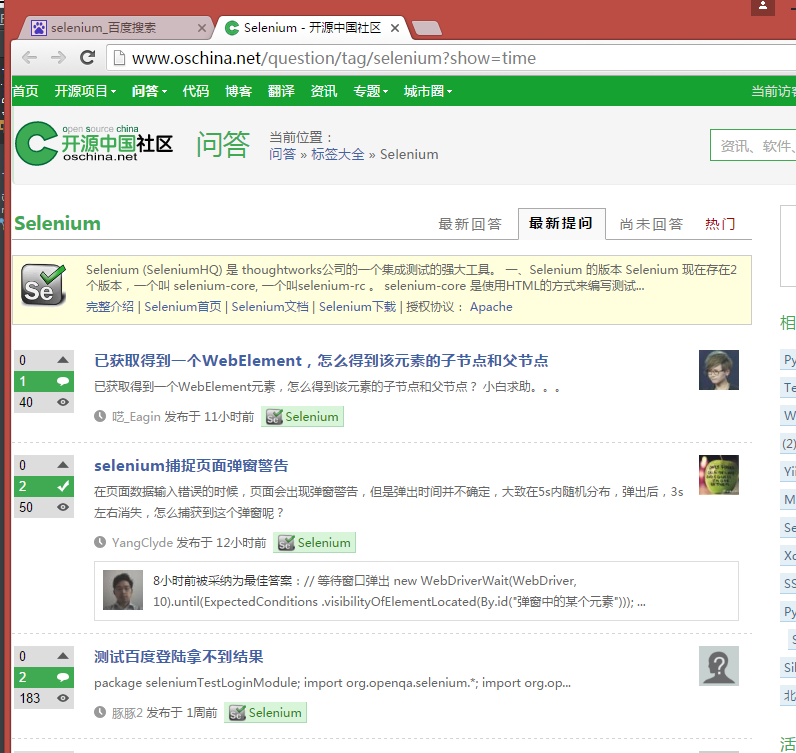
driver.find_elements_by_link_text('Selenium - 开源中国社区')[0].click()
4.以下页面操作都是自动完成
【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python 爬虫利器 Selenium
前面几节,我们学习了用 requests 构造页面请求来爬取静态网页中的信息以及通过 requests 构造 Ajax 请求直接获取返回的 JSON 信息. 还记得前几节,我们在构造请求时会给请求加上 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用 一.简介 二.安装 三.使用 一.简介 Selenium 是自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏 ...
- Python爬虫教程-28-Selenium 操纵 Chrome
我觉得本篇是很有意思的,闲着没事来看看! Python爬虫教程-28-Selenium 操纵 Chrome PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面.Selenium + Phanto ...
- Python爬虫之selenium高级功能
Python爬虫之selenium高级功能 原文地址 表单操作 元素拖拽 页面切换 弹窗处理 表单操作 表单里面会有文本框.密码框.下拉框.登陆框等. 这些涉及与页面的交互,比如输入.删除.点击等. ...
- Python爬虫之selenium库使用详解
Python爬虫之selenium库使用详解 本章内容如下: 什么是Selenium selenium基本使用 声明浏览器对象 访问页面 查找元素 多个元素查找 元素交互操作 交互动作 执行JavaS ...
- selenium与chrome浏览器及驱动的版本匹配
用selenium+python+webdriver完成UI功能自动化,经常会碰到浏览器版本与驱动的版本不匹配而引起报错,下面就selenium与chrome浏览器及驱动的版本匹配 做个总结. 使用W ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
随机推荐
- PLSA的EM推导
本文作为em算法在图模型中的一个应用,推导plsa的em算法. 1 em算法 em算法是解决一类带有隐变量模型的参数估计问题. 1.1 模型的定义 输入样本为,对应的隐变量为.待估计的模型参数为,目标 ...
- T-SQL查询进阶--SQL Server中的事务与锁
为什么需要锁 在任何多用户的数据库中,必须有一套用于数据修改的一致的规则,当两个不同的进程试图同时修改同一份数据时,数据库管理系统(DBMS)负责解决它们之间潜在的冲突.任何关系数据库必须支持事务的A ...
- 《javascript 高级程序设计》 笔记2 8~章
chapter 8 BOM(浏览器对象模型) window对象 表示浏览器的一个实例. 直接在window对象上定义的属性可以通过delete操作符删除,而全局变量不可以. 窗口关系及框架 位置操作 ...
- centos7 yum安装配置redis
1.设置Redis的仓库地址 yum install epel-release 2.安装redis yum install redis 修改配置文件,监听所有的IP地址 vim /etc/redis. ...
- springboot整合mybatis,druid,mybatis-generator插件完整版
一 springboot介绍 Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员 ...
- 使用octave符号运算求解不定积分、微分方程等(兼容matlab)
1.求解1/(1+cos(x))^2的不定积分. 在和学生讨论一道物理竞赛题的时候,出现了这个函数的积分求解需求.查积分表也可写出答案.但是可以使用octave的符号运算工具箱来做. syms x; ...
- C++_异常5-异常规范和栈解退
异常规范 异常规范的理念看似有前途,但实际的使用效果并不好. 忽视异常规范之前,您至少应该知道它是什么样的,如下所示: double harm(double a) throw(bad_thing); ...
- vue项目用webpack打包后跨域问题
在app.js的最开始加上 app.all('*', (req, res, next) => { res.header("Access-Control-Allow-Origin&quo ...
- 学习掌握oracle外表(external table)
[转自] http://blog.chinaunix.net/uid-10697776-id-2935685.html 定义 External tables access data in extern ...
- python 文件处理(基础字符)
基于字符read & write 最基本的文件操作当然就是在文件中读写数据.这也是很容易掌握的.现在打开一个文件以进行写操作: 1. fileHandle = open ( 'test.txt ...