python爬虫---从零开始(二)Urllib库
接上文再继续我们的爬虫,这次我们来述说Urllib库
1,什么是Urllib库
Urllib库是python内置的HTTP请求库
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparse robots.txt解析模块
不需要额外安装,python自带的库。
注意:
python2
import urllib2
response = urllib2.urlopen('http://baidu.com')
python3
import urllib.request
response = urilib.request.urlopen('http://www.baidu.com')
python2和python3使用urllib库还是有一定区别的。
2,方法以及模块:
1)request
基本运行:(get方式的请求)
import urllib.request
response = urilib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
运行结果如下:

在这里我们看到,当我们输入urllib.request.urlopen('http://baidu.com')时,我们会得到一大长串的文本,也就是我们将要从这个得到的文本里得到我们所需要的数据。
带有请求参数:(post方式的请求)
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'username':'cainiao'}),encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post',data = data)
print(response.read())
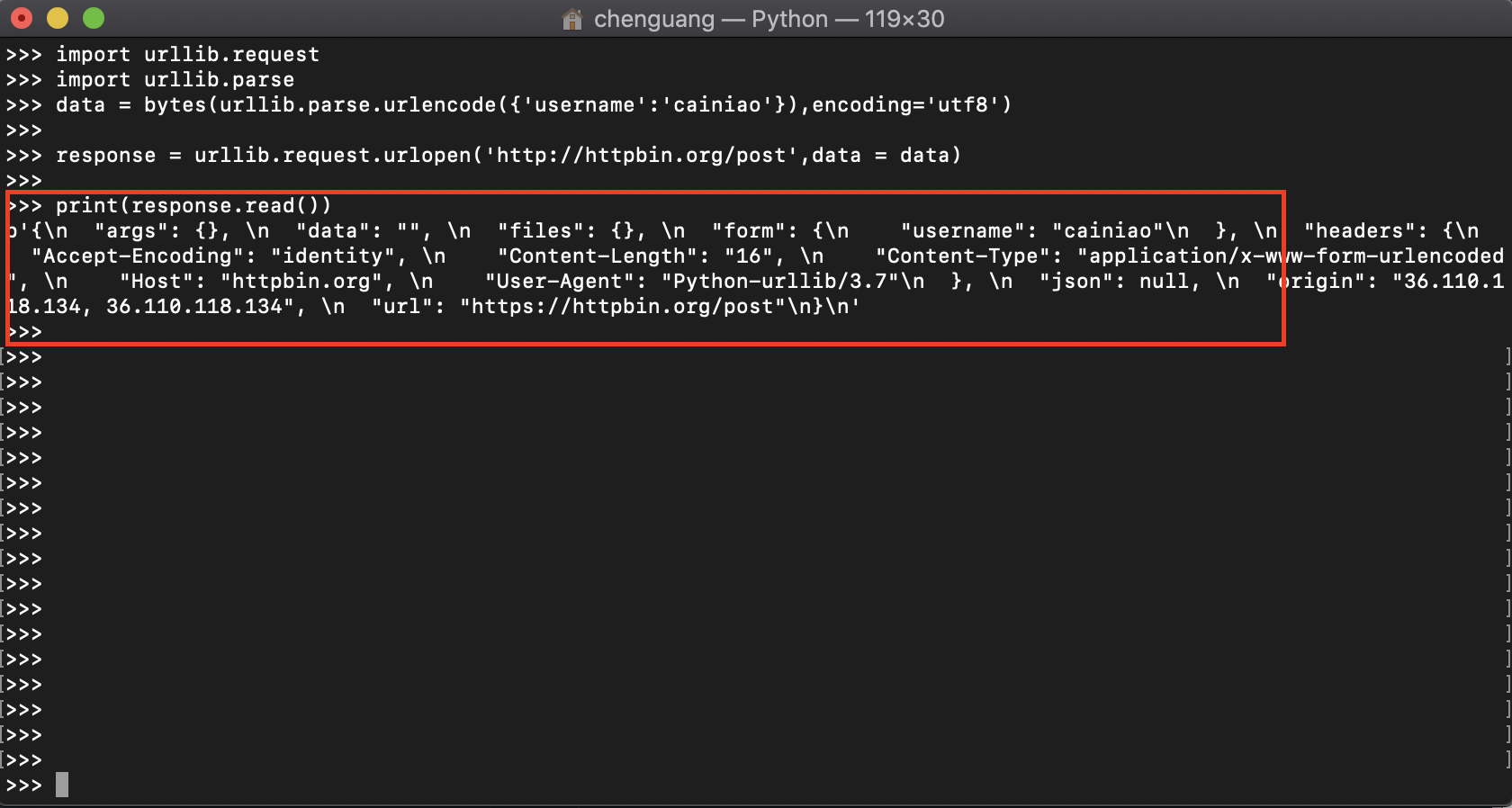
在这里我们不难看出,我们给予的data username参数已经传递过去了。
注意data必须为bytes类型
设置请求超时时间:
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get', timeout = )
print(response.read())

这时我们看到,执行代码时报出timed out错误。我们这时可以使用urllib.error模块,代码如下
import urllib.request
ipmort urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout = 0.1)
print(response.read())
except urllib.error.URLError as e:
print('链接超时啦~!') # 这里我们没有判断错误类型,可以自行加入错误类型判断,然后在进行输出。
说到这,我们就把最简单,最基础的urlopen的基础全都说完了,有能力的小伙伴,可以进行详细阅读其源码,更深入的了解该方法。
2)响应 response
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(type(response))
# 得到一个类型为<class 'http.client.HTTPResponse'>

import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(type(response)) # 响应类型
print(response.status) #上篇文章提到的状态码
print(response.getheaders) # 请求头
print(response.getheader('Server')) # 取得请求头参数

import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8')) # 响应体,响应内容
响应体为字节流形式的内容,我们需要调用decode(decode('utf-8'))进行转码。
常用的post请求基本写法
from urllib import request,parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent':'Mozilla/4.0(compatible;MSIE 5.5;Windows NT)',
'Host':'httpbin.org'
}
dict = {
'name':'cxiaocai'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url =url , data = data , headers = headers , method = 'POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
也可以写成这样的
from urllib import request,parse
url = 'http://httpbin.org/post'
dict = {
'name':'cxiaocai'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url =url , data = data , headers = headers , method = 'POST')
req.add_header('User-Agent':'Mozilla/4.0(compatible;MSIE 5.5;Windows NT)')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
说到这里,我们最基本的urllib请求就可以基本完成了,很大一部分网站也可以进行爬取了。
3,代理设置
代理设置我们这里简单的说一下,后面的博客我们会用实际爬虫来说明这个。
Hander代理
import urllib.request
proxy_hander = urllib.request.ProxyHeader({
'http':'http://127.0.0.1:1111',
'https':'https://127.0.0.1:2222'
})
opener = urllib.request.build_opener(proxy_hander)
response = opener.open('http://www.baidu.com')
print(response.read()) # 我这没有代理,没有测试该方法。
Cookie设置
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
hander = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(hander)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name + "=" + item.value)

例如某些网站是需要登陆的,所有我们在这里需要设置Cookie
我们也可以将Cookie保存为文本文件,便于多次进行读取。
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
hander = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(hander)
response = opener.open("http://www.baidu.com")
cookie.save(ignore_discard=True, ignore_expires=True)
代码运行以后会在项目目录下生成一个cookie.txt

另外一种Cookie的保存格式
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.LWPCookieJar(filename)
hander = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(hander)
response = opener.open("http://www.baidu.com")
cookie.save(ignore_discard=True, ignore_expires=True)
运行代码以后也会生成一个txt文件,格式如下

下面我们来读取我们过程保存的Cookie文件
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt',ignore_expires=True,ignore_discard=True)
hander = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(hander)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
4,异常处理
简单事例,在这里我们来访问一个不存在的网站
from urllib import request,error
try:
response = request.urlopen('https://www.cnblogs.com/cxiaocai/articles/index123.html')
except error.URLError as e:
print(e.reason)
这里我们知道这个网站根本不存在的,会报错,我们捕捉该异常可以保证程序继续运行,我们可以执行重试操作
我们也可以查看官网 https://docs.python.org/3/library/urllib.error.html#module-urllib.error5,URL解析
urlparse模块
主要用户解析URL的模块,下面我们先来一个简单的示例
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1')
print(type(result),result)
这里我们看下输出结果:
该方法可以进行url的拆分
也可以制定请求方式http,或者https方式请求

from urllib.parse import urlparse
result = urlparse('www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1',scheme='https')
print(result)
输出结果如下所示:
在这里我们看到了,请求被制定了https请求
我们会看到输出结果里包含一个fragents,我们想将framents拼接到query后面,我们可以这样来做

from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#commont',allow_fragments=False)
print(result)
输出结果为
如果没有frament,则拼接到path内
示例:
我们现在知道了URl怎么进行拆分,如果我们得到了URl的集合,例如这样dada = ['http','www.baidu.com','index.html','user','a=6','comment']
我们可以使用urlunparse还有urljoin,主要是来进行url的拼接的,接下来我们来看下我们的示例:
以后面的为基准,如果有就留下,如果没有就从前面取。
如果我们的有了一个字典类型的参数,和一个url,我们想发起get请求(上一期说过get请求传参),我们可以这样来做,
在这里我们需要注意的是,url地址后面需要自行加一个‘?’。
最后还有一个urllib.robotparser,主要用robot.txt文件的官网有一些示例,由于这个不常用,在这里我做过多解释。
官网地址:https://docs.python.org/3/library/urllib.robotparser.html#module-urllib.robotparser 感兴趣的小伙伴可以自行阅读官方文档。 到这里我们就把urllib的基本用法全部说了一遍,可以自己尝试写一些爬虫程序了(先用正则解析,后期我们有更简单的方法)。
想更深入的研读urllib库,可以直接登陆官方网站直接阅读其源码。官网地址: https://docs.python.org/3/library/urllib.html
注意:很多小伙伴看到我的代码直接复制过去,但发现直接粘贴会报错,还需要自己删除多余的空行,在这里我并不建议你们复制粘贴,后期我们整理一个github供大家直接使用。
下一篇文章我会弄一篇关于Requests包的使用,个人感觉比urllib更好用,敬请期待。
感谢大家的阅读,不正确的地方,还希望大家来斧正,鞠躬,谢谢python爬虫---从零开始(二)Urllib库的更多相关文章
- PYTHON 爬虫笔记二:Urllib库基本使用
知识点一:urllib的详解及基本使用方法 一.基本介绍 urllib是python的一个获取url(Uniform Resource Locators,统一资源定址器)了,我们可以利用它来抓取远程的 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- Python爬虫入门:Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- 芝麻HTTP:Python爬虫入门之Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- Python爬虫入门:Urllib库的高级使用
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
随机推荐
- word-break: break-all word-break:keep-all word-wrap: break-word三者的区别
word-break属性:指定非CJK脚本的断行规则. 值 描述 normal 使用浏览器默认的换行规则. break-all 允许在单词内换行. keep-all 只能在半角空格或连字符处换行. w ...
- POJ1276【多重背包】
题意: 给出一个价值sum,然后给出n,代表n个方案,接着n对代表个数与价值,要求最接近sum,但不超过sum的价值. 思路: 多重背包,利用二进制拆分达到保证对于0..n间的每一个整数,均可以用若干 ...
- bzoj 4903: [Ctsc2017]吉夫特【lucas+状压dp】
首先根据lucas, \[ C_n^m\%2=C_{n\%2}^{m\%2}*C_{n/2}^{m/2} \] 让这个式子的结果为计数的情况只有n&m==m,因为m的每一个为1的二进制位都需要 ...
- (DP)51NOD 1006 最长公共子序列&1092 回文字符串
1006 给出两个字符串A B,求A与B的最长公共子序列(子序列不要求是连续的). 比如两个串为: abcicba abdkscab ab是两个串的子序列,abc也是,abca也是,其中abc ...
- 第十二篇 .NET高级技术之lambda表达式
最近由于项目需要,刚刚学完了Action委托和Func<T>委托,发现学完了委托就必须学习lambda表达式,委托和Lambda表达式联合起来,才能充分的体现委托的便利.才能使代码更加简介 ...
- Ubuntu还是windows呢
本来想把才换不久的电脑也换成Ubuntu,犹豫再三,还是把这个老电脑作为Ubuntu的主力机把,毕竟大屏幕看着也得劲 新电脑还是win10吧,毕竟现在速度还是刷刷的,等过几年速度降下来了,就换成Ubu ...
- Linux下备份MySQL数据库的Shell脚本
数据库每天都想备份,手动备份太麻烦而又容易忘记,所以写了一个自动备份MySQL数据库的脚本,加入定时计划中,每天自运运行. 创建Shell脚本代码如下,命名为mysql_dump.sh #!/bin/ ...
- 1391:局域网(net)
[题目描述] 某个局域网内有n(n≤100)台计算机,由于搭建局域网时工作人员的疏忽,现在局域网内的连接形成了回路,我们知道如果局域网形成回路那么数据将不停的在回路内传输,造成网络卡的现象.因为连接计 ...
- SAE上无法加载css等文件
如果你的SAE用到了这些文件,你会发现本地虽然能够运行成功,但是SAE上却无法加载. 其实就是地址发生了变化,我们告诉SAE这些东西怎么找就可以了. 例如我的css和js文件放在了app/static ...
- Codeforces Round #405 (rated, Div. 2, based on VK Cup 2017 Round 1) E
Description Bear Limak prepares problems for a programming competition. Of course, it would be unpro ...



