Python网络爬虫笔记(四):使用selenium获取动态加载的内容
(一) 说明
上一篇只能下载一页的数据,第2、3、4....100页的数据没法获取,在上一篇的基础上修改了下,使用selenium去获取所有页的href属性值。
使用selenium去模拟浏览器有点麻烦,例如有300页就要点300次(按博客园这种一页20条,也就是6000条数据。要是几百万条,这个就得点好长时间了)
研究下有没有办法调用JS修改页面默认显示的数据条数(例如:博客园默认1页显示20条,改成默认显示1万条数据)。
(二) 完整代码
delayed.py的代码还是和之前一样。最好限速,不限速很容易被拒绝连接,而且也不道德。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.support.expected_conditions import StaleElementReferenceException
import time
import urllib.request as ure
from delayed import WaitFor
import lxml.html
import os
import docx
#使用selenium获取所有随笔href属性的值,url只能传小类的,例如https://www.cnblogs.com/cate/python/
def selenium_links(url):
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
#获取最大页数
maxPage = driver.find_element_by_css_selector('#paging_block div.pager a:nth-last-of-type(2)').get_attribute('text')
x=1
url_list=[]
#循环获取当前小类所有页面的href
while x<=int(maxPage):
time.sleep(1) #隐式 显式等待都尝试了,还是报错,只能等待1秒了(调试又正常运行)
x +=1
#等待 Next出现并返回 ,就是博客园翻到下一页的那个元素
lastPage = WebDriverWait(driver, 30).until(expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '#paging_block div.pager a:last-child')))
#等待元素出现并返回list,这里定位的是页面上的随笔
html = WebDriverWait(driver, 30).until(expected_conditions.presence_of_all_elements_located((By.CSS_SELECTOR, 'a.titlelnk')))
#迭代,将href属性的值添加到url_list
for h in html:
url_list.append(h.get_attribute('href'))
lastPage.click()
driver.quit()
#以列表形式返回所有URL
return url_list
#传入包含url的列表
def link_crawler(seed_url):
html_list = []
#下载crawl_queue中的所有网页
waitFor = WaitFor(2)
x =1
while seed_url:
print('第'+str(x)+'个')
x+=1
url = seed_url.pop()
#下载限速
waitFor.wait(url)
html = download(url)
html_list.append(html)
return html_list
#下载网页并返回
def download(url,user_agent='FireDrich',num=2):
print('下载:'+url)
#设置用户代理
headers = {'user_agent':user_agent}
request = ure.Request(url,headers=headers)
try:
#下载网页
html = ure.urlopen(request).read()
except ure.URLError as e:
print('下载失败'+e.reason)
html=None
if num>0:
#遇到5XX错误时,递归调用自身重试下载,最多重复2次
if hasattr(e,'code') and 500<=e.code<600:
return download(url,num-1)
return html #将下载的网页写入Word文档
def createWord(html):
x = 0
while html:
url = html.pop()
tree = lxml.html.fromstring(url) # 解析HTML为统一的格式
title = tree.xpath('//a[@id="cb_post_title_url"]') # 获取标题
the_file = tree.xpath('//div[@id="cnblogs_post_body"]/p') # 获取正文内容
pre = tree.xpath('//pre') # 获取随笔代码部分(使用博客园自带插入代码功能插入的)
img = tree.xpath('//div[@id="cnblogs_post_body"]/p/img/@src') # 获取图片
# 修改工作目录
os.chdir('F:\Python\worm\data\博客园文件')
try:
# 创建一个空白新的Word文档
doc = docx.Document()
# 添加标题
doc.add_heading(title[0].text_content(), 0)
#有的设置成注册用户才能浏览的随笔,调用download函数时下载不到正确的网页,导致获取不到标题
#title会是空列表,这里忽略这篇随笔,利用http.cookiejar模块应该可以解决这种问题,以后再看看这个模块了
except IndexError as e:
continue
for i in the_file:
# 将每一段的内容添加到Word文档(p标签的内容)
doc.add_paragraph(i.text_content())
# 将代码部分添加到文档中
for p in pre:
doc.add_paragraph(p.text_content())
# 将图片添加到Word文档中
for i in img:
try:
ure.urlretrieve(i, '0.jpg')
doc.add_picture('0.jpg')
except UnicodeEncodeError as e:
print('异常'+str(e))
pass
# 截取标题的前8位作为Word文件名
filename = title[0].text_content()[:8] + '.docx'
# 保存Word文档
# 如果文件名已经存在,将文件名设置为title[0].text_content()[:8]+ str(x).docx,否则将文件名设置为filename
if str(filename) in os.listdir('F:\Python\worm\data\博客园文件'):
doc.save(title[0].text_content()[:8] + str(x) + '.docx')
x += 1
else:
doc.save(filename)
#调用selenium_links获取所有url
html = selenium_links('https://www.cnblogs.com/cate/ruby/')
#调用link_crawler下载所有网页
downHtml = link_crawler(html)
#提取已经下载的网页数据到Word文档中
createWord(downHtml)
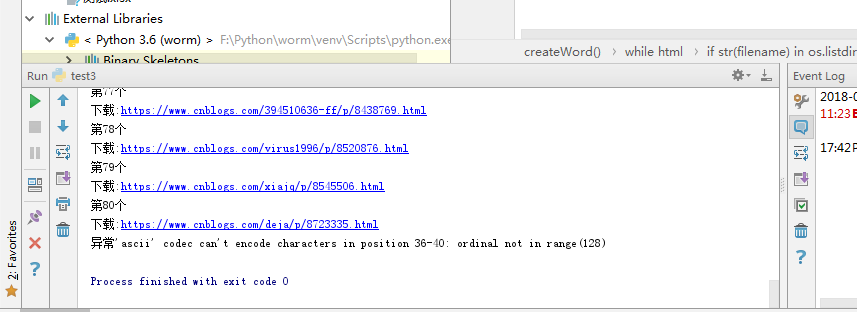
(三)结果
下面这个异常是,有的随笔上传了微信公众号的图片(暂时不确定是全部这样,还是部分这样),解析这个的时候会出现编码错误,目前的处理是输出异常信息,跳过这张图片。
Python网络爬虫笔记(四):使用selenium获取动态加载的内容的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- Golang 网络爬虫框架gocolly/colly 五 获取动态数据
Golang 网络爬虫框架gocolly/colly 五 获取动态数据 gcocolly+goquery可以非常好地抓取HTML页面中的数据,但碰到页面是由Javascript动态生成时,用goque ...
- python网络爬虫之自动化测试工具selenium[二]
目录 前言 一.获取今日头条的评论信息(request请求获取json) 1.分析数据 2.获取数据 二.获取今日头条的评论信息(selenium请求获取) 1.分析数据 2.获取数据 房源案例(仅供 ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 爬虫:获取动态加载数据(selenium)(某站)
如果网站数据是动态加载,需要不停往下拉进度条才能显示数据,用selenium模拟浏览器下拉进度条可以实现动态数据的抓取. 本文希望找到某乎某话题下讨论较多的问题,以此再寻找每一问题涉及的话题关键词(侵 ...
- 爬虫再探实战(四)———爬取动态加载页面——请求json
还是上次的那个网站,就是它.现在尝试用另一种办法——直接请求json文件,来获取要抓取的信息. 第一步,检查元素,看图如下: 过滤出JS文件,并找出包含要抓取信息的js文件,之后就是构造request ...
- 爬虫--selenuim和phantonJs处理网页动态加载数据的爬取
1.谷歌浏览器的使用 下载谷歌浏览器 安装谷歌访问助手 终于用上谷歌浏览器了.....激动 问题:处理页面动态加载数据的爬取 -1.selenium -2.phantomJs 1.selenium 二 ...
- Python网络爬虫实战(四)模拟登录
对于一个网站的首页来说,它可能需要你进行登录,比如知乎,同一个URL下,你登录与未登录当然在右上角个人信息那里是不一样的. (登录过) (未登录) 那么你在用爬虫爬取的时候获得的页面究竟是哪个呢? 肯 ...
随机推荐
- Selenium自动化测试Python四:WebDriver封装
WebDriver 封装 欢迎阅读WebDriver封装讲义.本篇讲义将会重点介绍Selenium WebDriver API的封装的概念和方法,以及使用封装进行自动化测试的设计. WebDriver ...
- 垃圾回收(GC)相关算法笔记
GC需要完成的3件事情: 哪些内存需要回收? 什么时候回收? 如何回收? 引用计数算法 给对象中添维护一个计数器,每当引用这个对象时,计数器加1:当引用失效时,计数器值减1:当计数器值为0时,表示这个 ...
- 07 - JavaSE之容器
本章宗旨:1136 -- 1个图 1个类 3个知识点 6个接口 容器 J2SDK 所提供的容器 API 位于 java.util 包内. 容器 API 的类图如下: Collection 接口的子接口 ...
- j2ee高级开发技术课程第四周
分析hello.java,在hello1项目中.下载链接:https://github.com/javaee/tutorial-examples/tree/master/web/jsf/hello1 ...
- guava EventBus 消息总线的运用
public class Test { public static void main(String[] args) { final EventBus eventBus = new EventBus( ...
- Go http handler 中间件
在http的handler处理中加上中间件,可以进行过滤.记录日志.统计和统一返回结果 package main import ( "fmt" "net/http&quo ...
- 关于Mybatis与Spring整合之后SqlSession与mapper对象之间数量的问题。
1,sqlsession的真实类型和数量 由于使用spring管理bean,当我们在代码中需要使用这个bean的时候,会首先去容器中找,第一次需要调用MapperFactoryBean的getObje ...
- java arrayList vector 区别
1. 关系图 List接口一共有三个实现类,分别是ArrayList.Vector和LinkedList 2. ArrayList.Vector和LinkedList区别 ArrayList是最常用的 ...
- 使用clamav模块对数据流进行病毒检测
准备工作:linux下安装clamav成功,启动clamav并打开本地socket监听"/tmp/clamav.socket" clamav开源工程目录:/usr/local/ 修 ...
- SQl常用语句总结(持续更新……)
创建示例数据库 USE master; GO IF DB_ID (N'mytest') IS NOT NULL DROP DATABASE mytest; GO CREATE DATABASE myt ...