爬虫值requests库
requests简介
简介
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库
,使用起来比urllib简洁很多
因为是第三方库,所以使用前需要cmd安装
pip install requests
安装完成后import一下,正常则说明可以开始使用了。
基本用法:
requests.get()用于请求目标网站,类型是一个HTTPresponse类型
import requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
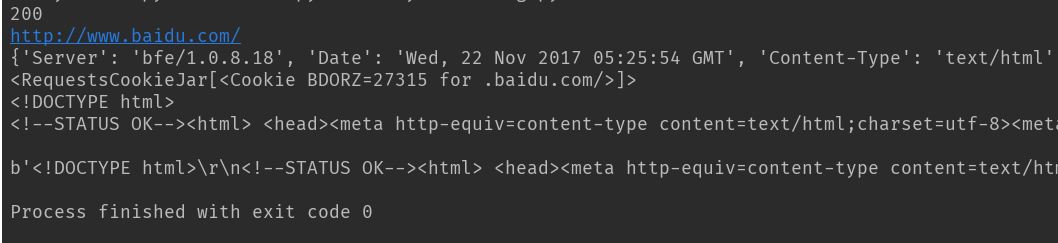
运行结果:
状态码:200
url:www.baidu.com
headers信息
各种请求方式:
import requests
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
基本的get请求
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
结果

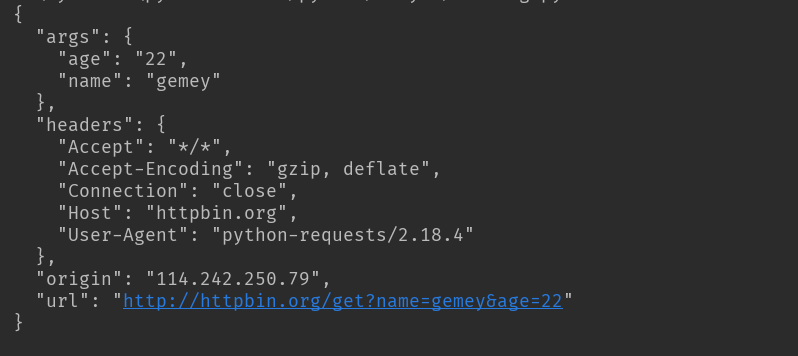
带参数的GET请求:
第一种直接将参数放在url内
import requests response = requests.get(http://httpbin.org/get?name=gemey&age=22)
print(response.text)
结果
另一种先将参数填写在dict中,发起请求时params参数指定为dict
import requests
data = {
'name': 'tom',
'age': 20
}
response = requests.get('http://httpbin.org/get', params=data)
print(response.text)
结果同上
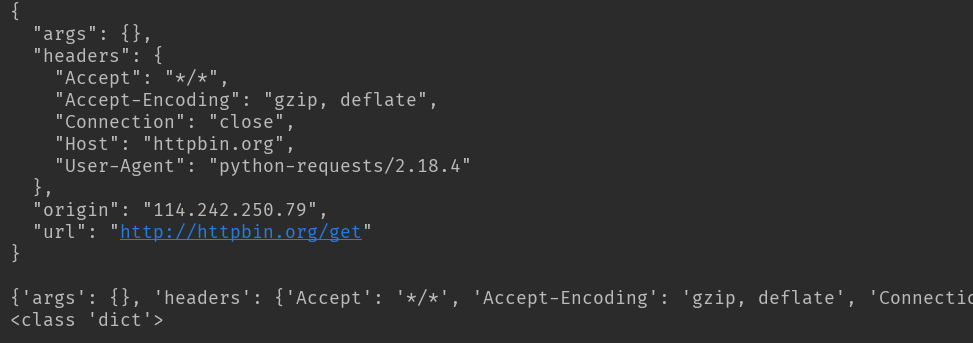
解析json
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
print(response.json()) #response.json()方法同json.loads(response.text)
print(type(response.json()))
结果
简单保存一个二进制文件
二进制内容为response.content
import requests
response = requests.get('http://img.ivsky.com/img/tupian/pre/201708/30/kekeersitao-002.jpg')
b = response.content
with open('F://fengjing.jpg','wb') as f:
f.write(b)
为请求添加头信息
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
使用代理
同添加headers方法,代理参数也要是一个dict
这里使用requests库爬取了IP代理网站的IP与端口和类型
因为是免费的,使用的代理地址很快就失效了。
import requests
import re def get_html(url):
proxy = {
'http': '120.25.253.234:812',
'https' '163.125.222.244:8123'
}
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
req = requests.get(url, headers=heads,proxies=proxy)
html = req.text
return html def get_ipport(html):
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="类型">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
for i in iplist:
for p in portlist:
for t in typelist:
pass
pass
a = t+','+i + ':' + p
sumray.append(a)
print('高匿代理')
print(sumray) if __name__ == '__main__':
url = 'http://www.kuaidaili.com/free/'
get_ipport(get_html(url))
结果:

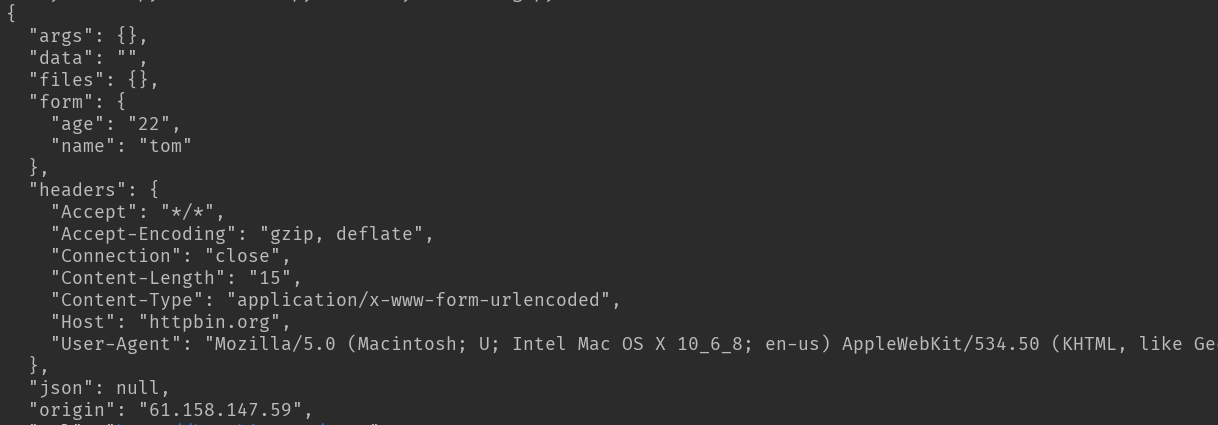
基本POST请求:
import requests
data = {'name':'tom','age':''}
response = requests.post('http://httpbin.org/post', data=data)
获取cookie
#获取cookie
import requests response = requests.get('http://www.baidu.com')
print(response.cookies)
print(type(response.cookies))
for k,v in response.cookies.items():
print(k+':'+v)
结果:

会话维持
import requests session = requests.Session()
session.get('http://httpbin.org/cookies/set/number/12345')
response = session.get('http://httpbin.org/cookies')
print(response.text)
结果:

证书验证设置
import requests
from requests.packages import urllib3 urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code) 打印结果:200
超时异常捕获
import requests
from requests.exceptions import ReadTimeout try:
res = requests.get('http://httpbin.org', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print(timeout)
异常处理
在你不确定会发生什么错误时,尽量使用try...except来捕获异常
所有的requests exception:
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
爬虫值requests库的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- 爬虫相关--requests库
requests的理想:HTTP for Humans 一.八个方法 相比较urllib模块,requests模块要简单很多,但是需要单独安装: 在windows系统下只需要在命令行输入命令 pip ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- python网络爬虫之requests库
Requests库是用Python编写的HTTP客户端.Requests库比urlopen更加方便.可以节约大量的中间处理过程,从而直接抓取网页数据.来看下具体的例子: def request_fun ...
- python网络爬虫之requests库 二
前面一篇在介绍request登录CSDN网站的时候,是采用的固定cookie的方式,也就是先通过抓包的方式得到cookie值,然后将cookie值加在发送的数据包中发送到服务器进行认证. 就好比获取如 ...
- 【Python爬虫】爬虫利器 requests 库小结
requests库 Requests 是一个 Python 的 HTTP 客户端库. 支持许多 HTTP 特性,可以非常方便地进行网页请求.网页分析和处理网页资源,拥有许多强大的功能. 本文主要介绍 ...
- (爬虫)requests库
一.requests库简介 urllib库和request库的作用一样,都是服务器发起请求数据,但是requests库比urllib库用起来更方便,它的接口更简单,选用哪种库看自己. 如果没有安装过这 ...
随机推荐
- Windows200864位操作系统下的SQLPLUS.EXE 无法找到入口解决办法和Oracle环境变量的设置
本机环境:Windows2008 64位中文版操作系统+Oracle11G+安装了Oracle32位和64位客户端驱动 问题起源:Path环境变量被360安全卫士优化修复后,整个给清空了,hosts文 ...
- AngularJS进阶(十七)在AngularJS应用中实现微信认证授权遇到的坑
在AngularJS应用中集成微信认证授权遇到的坑 注:请点击此处进行充电! 前言 项目开发过程中,移动端新近增加了一个功能"微信授权登录",由于自己不是负责移动端开发的,但最后他 ...
- Android进阶(二十一)创建Android虚拟机
创建Android虚拟机
- 如何修改新建脚本模板-ScriptTemplates(Unity3D开发之十五)
猴子原创,欢迎转载.转载请注明: 转载自Cocos2Der-CSDN,谢谢! 原文地址: http://blog.csdn.net/cocos2der/article/details/44957631 ...
- 新版MATERIAL DESIGN 官方动效指南(一)
Google 刚发布了新版Material Design 官方动效指南,全文包括三个部分:为什么说动效很重要?如何制作优秀的Material Design动效及转场动画,动效的意义.新鲜热辣收好不谢! ...
- RTMPdump(libRTMP) 源代码分析 6: 建立一个流媒体连接 (NetStream部分 1)
===================================================== RTMPdump(libRTMP) 源代码分析系列文章: RTMPdump 源代码分析 1: ...
- ROS探索总结(十二)——坐标系统
在机器人的控制中,坐标系统是非常重要的,在ROS使用tf软件库进行坐标转换. 相关链接:http://www.ros.org/wiki/tf/Tutorials#Learning_tf 一.tf简介 ...
- nasm预处理器(1)
与处理器将所有以反斜杠结尾的连续行合并为一行. 单行的宏以%define来定义:当单行的宏被扩展后还含有其他宏时,会在执行时而不是定义时展开. %define a(x) 1+b(x) %define ...
- LeetCode(63)-First Bad Version
题目: You are a product manager and currently leading a team to develop a new product. Unfortunately, ...
- XSS攻击过滤处理
关于XSS攻击 XSS是一种经常出现在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中. XSS漏洞的危害 网络钓鱼,包括盗取各类用户账号: 窃取用户cooki ...