吴裕雄 python 机器学习——模型选择分类问题性能度量
import numpy as np
import matplotlib.pyplot as plt from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,fbeta_score,classification_report,confusion_matrix,precision_recall_curve,roc_auc_score,roc_curve #模型选择分类问题性能度量accuracy_score模型
def test_accuracy_score():
y_true=[1,1,1,1,1,0,0,0,0,0]
y_pred=[0,0,1,1,0,0,1,1,0,0]
print('Accuracy Score(normalize=True):',accuracy_score(y_true,y_pred,normalize=True))
print('Accuracy Score(normalize=False):',accuracy_score(y_true,y_pred,normalize=False)) #调用test_accuracy_score()
test_accuracy_score()

#模型选择分类问题性能度量precision_score模型
def test_precision_score():
y_true=[1,1,1,1,1,0,0,0,0,0]
y_pred=[0,0,1,1,0,0,0,0,0,0]
print('Accuracy Score:',accuracy_score(y_true,y_pred,normalize=True))
print('Precision Score:',precision_score(y_true,y_pred)) #调用test_precision_score()
test_precision_score()

#模型选择分类问题性能度量recall_score模型
def test_recall_score():
y_true=[1,1,1,1,1,0,0,0,0,0]
y_pred=[0,0,1,1,0,0,0,0,0,0]
print('Accuracy Score:',accuracy_score(y_true,y_pred,normalize=True))
print('Precision Score:',precision_score(y_true,y_pred))
print('Recall Score:',recall_score(y_true,y_pred)) #调用test_recall_score()
test_recall_score()

#模型选择分类问题性能度量f1_score模型
def test_f1_score():
y_true=[1,1,1,1,1,0,0,0,0,0]
y_pred=[0,0,1,1,0,0,0,0,0,0]
print('Accuracy Score:',accuracy_score(y_true,y_pred,normalize=True))
print('Precision Score:',precision_score(y_true,y_pred))
print('Recall Score:',recall_score(y_true,y_pred))
print('F1 Score:',f1_score(y_true,y_pred)) #调用test_f1_score()
test_f1_score()

#模型选择分类问题性能度量fbeta_score模型
def test_fbeta_score():
y_true=[1,1,1,1,1,0,0,0,0,0]
y_pred=[0,0,1,1,0,0,0,0,0,0]
print('Accuracy Score:',accuracy_score(y_true,y_pred,normalize=True))
print('Precision Score:',precision_score(y_true,y_pred))
print('Recall Score:',recall_score(y_true,y_pred))
print('F1 Score:',f1_score(y_true,y_pred))
print('Fbeta Score(beta=0.001):',fbeta_score(y_true,y_pred,beta=0.001))
print('Fbeta Score(beta=1):',fbeta_score(y_true,y_pred,beta=1))
print('Fbeta Score(beta=10):',fbeta_score(y_true,y_pred,beta=10))
print('Fbeta Score(beta=10000):',fbeta_score(y_true,y_pred,beta=10000)) #调用test_fbeta_score()
test_fbeta_score()

#模型选择分类问题性能度量classification_report模型
def test_classification_report():
y_true=[1,1,1,1,1,0,0,0,0,0]
y_pred=[0,0,1,1,0,0,0,0,0,0]
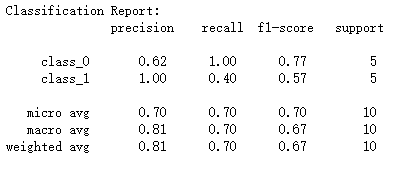
print('Classification Report:\n',classification_report(y_true,y_pred,target_names=["class_0","class_1"])) #调用test_classification_report()
test_classification_report()
#模型选择分类问题性能度量confusion_matrix模型
def test_confusion_matrix():
y_true=[1,1,1,1,1,0,0,0,0,0]
y_pred=[0,0,1,1,0,0,0,0,0,0]
print('Confusion Matrix:\n',confusion_matrix(y_true,y_pred,labels=[0,1])) #调用test_confusion_matrix()
test_confusion_matrix()

#模型选择分类问题性能度量precision_recall_curve模型
def test_precision_recall_curve():
### 加载数据
iris=load_iris()
X=iris.data
y=iris.target
# 二元化标记
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
#### 添加噪音
np.random.seed(0)
n_samples, n_features = X.shape
X = np.c_[X, np.random.randn(n_samples, 200 * n_features)] X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.5,random_state=0)
### 训练模型
clf=OneVsRestClassifier(SVC(kernel='linear', probability=True,random_state=0))
clf.fit(X_train,y_train)
y_score = clf.fit(X_train, y_train).decision_function(X_test)
### 获取 P-R
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
precision = dict()
recall = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i],y_score[:, i])
ax.plot(recall[i],precision[i],label="target=%s"%i)
ax.set_xlabel("Recall Score")
ax.set_ylabel("Precision Score")
ax.set_title("P-R")
ax.legend(loc='best')
ax.set_xlim(0,1.1)
ax.set_ylim(0,1.1)
ax.grid()
plt.show() #调用test_precision_recall_curve()
test_precision_recall_curve()

#模型选择分类问题性能度量roc_curve、roc_auc_score模型
def test_roc_auc_score():
### 加载数据
iris=load_iris()
X=iris.data
y=iris.target
# 二元化标记
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
#### 添加噪音
np.random.seed(0)
n_samples, n_features = X.shape
X = np.c_[X, np.random.randn(n_samples, 200 * n_features)] X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.5,random_state=0)
### 训练模型
clf=OneVsRestClassifier(SVC(kernel='linear', probability=True,random_state=0))
clf.fit(X_train,y_train)
y_score = clf.fit(X_train, y_train).decision_function(X_test)
### 获取 ROC
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
fpr = dict()
tpr = dict()
roc_auc=dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i],y_score[:, i])
roc_auc[i] = roc_auc_score(fpr[i], tpr[i])
ax.plot(fpr[i],tpr[i],label="target=%s,auc=%s"%(i,roc_auc[i]))
ax.plot([0, 1], [0, 1], 'k--')
ax.set_xlabel("FPR")
ax.set_ylabel("TPR")
ax.set_title("ROC")
ax.legend(loc="best")
ax.set_xlim(0,1.1)
ax.set_ylim(0,1.1)
ax.grid()
plt.show() #调用test_roc_auc_score()
test_roc_auc_score()
吴裕雄 python 机器学习——模型选择分类问题性能度量的更多相关文章
- 吴裕雄 python 机器学习——模型选择回归问题性能度量
from sklearn.metrics import mean_absolute_error,mean_squared_error #模型选择回归问题性能度量mean_absolute_error模 ...
- 吴裕雄 python 机器学习——模型选择数据集切分
import numpy as np from sklearn.model_selection import train_test_split,KFold,StratifiedKFold,LeaveO ...
- 吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择学习曲线learning_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择参数优化暴力搜索寻优GridSearchCV模型
import scipy from sklearn.datasets import load_digits from sklearn.metrics import classification_rep ...
- 吴裕雄 python 机器学习——模型选择参数优化随机搜索寻优RandomizedSearchCV模型
import scipy from sklearn.datasets import load_digits from sklearn.metrics import classification_rep ...
- 吴裕雄 python 机器学习——模型选择损失函数模型
from sklearn.metrics import zero_one_loss,log_loss def test_zero_one_loss(): y_true=[1,1,1,1,1,0,0,0 ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
随机推荐
- 根据CPU内核创建多进程
from multiprocessing import Pool import psutil cpu_count = psutil.cpu_count(logical=False) #1代表单核CPU ...
- V8 是怎么跑起来的 —— V8 中的对象表示
V8 是怎么跑起来的 —— V8 中的对象表示 ThornWu The best is yet to come 30 人赞同了该文章 本文创作于 2019-04-30,2019-12-20 迁移至此本 ...
- 完整安装IIS服务
此文主要是针对前面提到的 IIS支持json.geojson文件 添加脚本映射时,提示找不到asp.dll时的解决方法. 主要参考了此文:http://www.kodyaz.com/articles/ ...
- 创建目录命令 - mkdir
(1) 命令名称:mkdir (2) 英文原意:make directories (3) 命令所在路径:/bin/mkdir (4) 执行权限:所有用户 (5) 功能描述:创建新目录 (6) 语法: ...
- Cats and Fish(小猫分鱼吃吱吱吱!)(我觉得是要用贪心的样子!)
炎炎夏日,一堆
- python使用临时文件
# 需求 # 某项目中,我们从传感器中采集数据,没采集1G数据后,做数据分析,最终只保存分析结果 # 这样很大的临时文件如果常驻在内存,将消耗大量地内存资源,我们可以使用临时文件储存(外部储存) # ...
- 如何在linux主机上运行/调试 arm/mips架构的binary
如何在linux主机上运行/调试 arm/mips架构的binary 原文链接M4x@10.0.0.55 本文中用于展示的binary分别来自Jarvis OJ上pwn的add,typo两道题 写这篇 ...
- goto语句的本质
除非跳出多个循环嵌套和远程注入技术,否则尽量少用goto goto会降低程序的可读性,让代码难以调试 利用递归也可以实现循环结构和do while类似 #define _CRT_SECURE_NO_W ...
- sql sever登录问题
重启电脑后会发现连不上数据库了 按下win+r:输入cmd.连接你的ip,(telnet 127.0.0.1 xxxx)发现连接不上 正在连接127.0.0.1..无法打开到主机的连接. 在端口 14 ...
- 【资料】哈代&拉马努金相关,悼文,哈佛演讲,及各种杂七杂八资料整理
悼文和哈佛演讲,因为有一堆公式所以实在懒得放lofter了. 信件和其他资料翻译在这里放个备份,基本上来自<Ramanujan:Letters and commentary>和<Ra ...