数据算法 --hadoop/spark数据处理技巧 --(3.左外连接 4.反转排序)
三。 左外连接
考虑一家公司,比如亚马逊,它拥有超过2亿的用户,每天要完成数亿次交易。假设我们有两类数据,用户和交易:
users(user_id,location_id)
transactions(transction_id,product_id,user_id,quantity,amout)
所谓左外连接:令T1(左表)和T2(右表)是以下两个关系(其中t1是T1的属性,t2是T2的属性):
T1=(K,t1)
T2=(K,t2)
关系T1,T2在连接键K上左外连接的结果将包含左表(T1)的所有记录,即使连接条件在右表(T2)中未找到任何匹配的记录。如果关于键K的ON子句匹配T2中的0条记录,这个连接仍会在结果中返回一行,不过T2的各个列为NULL。左外连接会返回内链接的所有值以及左表中未与右表匹配的所有值。
sql: select field1,field2 .. from T1 left outer join T2 on T1.K=T2.k



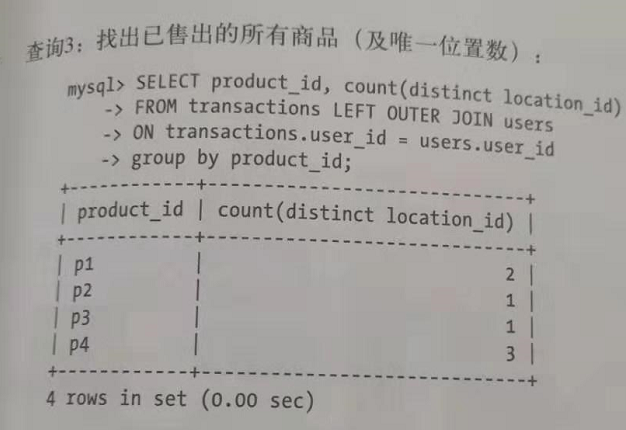
MR左外连接实现:
上图中sql查询3可以提供我们需要的输出,他会找出所有交易中各个售出商品对应的不同用户地址。我们将分两个阶段提供左外连接问题的解决方案。
MR阶段1:找出所有售出的的商品(以及关键的地址)。可以使用上一节中的sql查询1完成这个任务。
MR阶段2:找出所有售出的商品(以及关联的唯一地址数)。可以使用上一届中的sql查询3来实现。

spark左外连接实现:
方案1:通过将两个javaRDD(这里是user和交易RDD),通过javaRDD.union函数返回并集,合并来创建一个新的RDD.
主要方法:transantion.mapToPair.union(users.mapToPair()).goupByKey().flatMapToPair().goupByKey().mapValues().collect()
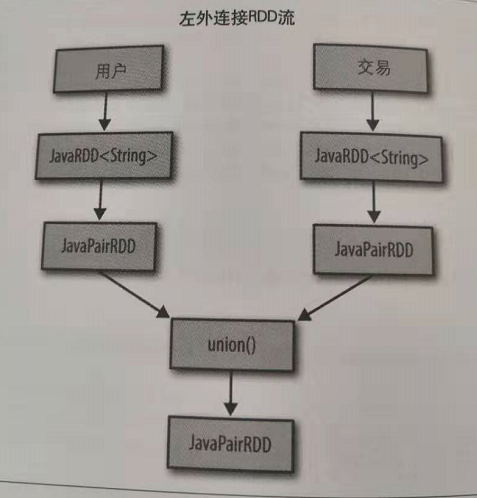
方案2:直接通过leftOuterJoin的方法来实现。
四。反转排序
反转排序(Order Inversion,OI)设计模式,这种设计模式可以用来控制MR框架中规约器值的顺序(这很有用,因为一些计算需要有序的数据。)通常会在数据分析阶段应用OI模式。在Hadoop和Spark中,值到达规约器的顺序是未定义的。(没有明确的顺序,除非我们利用MR的排序阶段将计算所需的数据推至规约器)。OI模式适用成对模式(使用更简单的数据结构,需要更少的规约器的内存),因为规约器阶段不需要额外的规约器值顺序。
为了帮助理解OI模式,下面首先来看一个简单的例子。考虑一个对应组合键(K1,K2)的规约器,假定K1是这个组合键的自然建部分,假设这个规约器接收到下面的值(这些值没有确定的顺序):
v1,v2,v3...
通过实现OI模式,可以对到达规约器(对应键(K1,K2))的值进行排序和分类。使用OI模式的唯一目的是适当的确定提供给规约器的数据的顺序。为了展示OI模式,下面假设K1是组合键的固定部分,在这里K2只是3个不同的值(K2a,K2b,K2c),这将生成下表所示的值。(需要说明,必须把键{K1,K2a}{K1,K2b}{K1,K2c}发送到相同的规约器)。

在这个表中:
m+p+q = n
排序顺序: K2a<K2b<K2c(升序) 或 K2a>K2b>K2c (降序)
利用适当的OI模式实现,可以对规约器值排序,如下所示:
A1,A2,A3,。。。Am ,B1,B2,....Bn,C1,C2,....Cn
由于规约器值是有序的,这就允许我们首先从Ai开始,再到Bi,最后到Ci完成一些计算。需要说明,这里不需要在内存中缓存值。关键问题是如何得到所需的行为。答案就是定义一个定制分区值,他只关注组合键(K1,K2)左边的部分(K1,即自然规约器键)。也就是说,定制分区器只根据左键(K1)的散列进行分区。
例子:

数据算法 --hadoop/spark数据处理技巧 --(3.左外连接 4.反转排序)的更多相关文章
- 数据算法 --hadoop/spark数据处理技巧 --(1.二次排序问题 2. TopN问题)
一.二次排序问题. MR/hadoop两种方案: 1.让reducer读取和缓存给个定键的所有值(例如,缓存到一个数组数据结构中,)然后对这些值完成一个reducer中排序.这种方法不具有可伸缩性,因 ...
- 数据算法 --hadoop/spark数据处理技巧 --(5.移动平均 6. 数据挖掘之购物篮分析MBA)
五.移动平均 多个连续周期的时间序列数据平均值(按相同时间间隔得到的观察值,如每小时一次或每天一次)称为移动平均.之所以称之为移动,是因为随着新的时间序列数据的到来,要不断重新计算这个平均值,由于会删 ...
- 数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九.基于内容的电影推荐 在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理. 本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐. ...
- 数据算法 --hadoop/spark数据处理技巧 --(17.小文件问题 18.MapReuce的大容量缓存)
十七.小文件问题 十八.MR的大容量缓存 在MR中使用和读取大容量缓存,(也就是说,可能包括数十亿键值对,而无法放在一个商用服务器的内存中).本次提出的算法通用,可以在任何MR范式中使用.(eg:MR ...
- 数据算法 --hadoop/spark数据处理技巧 --(11.K-均值聚类 12. k-近邻)
十一.k-均值聚类 这个需要MR迭代多次. 开始时,会选择K个点作为簇中心,这些点成为簇质心.可以选择很多方法啦初始化质心,其中一种方法是从n个点的样本中随机选择K个点.一旦选择了K个初始的簇质心,下 ...
- 数据算法 --hadoop/spark数据处理技巧 --(13.朴素贝叶斯 14.情感分析)
十三.朴素贝叶斯 朴素贝叶斯是一个线性分类器.处理数值数据时,最好使用聚类技术(eg:K均值)和k-近邻方法,不过对于名字.符号.电子邮件和文本的分类,则最好使用概率方法,朴素贝叶斯就可以.在某些情况 ...
- 数据算法 --hadoop/spark数据处理技巧 --(15.查找、统计和列出大图中的所有三角形 16.k-mer计数)
十五.查找.统计和列出大图中的所有三角形 第一步骤的mr: 第二部mr: 找出三角形 第三部:去重 spark: 十六: k-mer计数 spark:
- 数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友. 在所有用户对中找出“共同好友”. eg: a b,c,d,g b a,c,d,e map()-> <a,b>,<b,c,d,g> ;< ...
- 内连接、左外连接、右外连接、全外连接、交叉连接(CROSS JOIN)-----小知识解决大数据攻略
早就听说了内连接与外连接,以前视图中使用过.这次自考也学习了,只是简单理解,现在深入探究学习(由于上篇博客的出现)与实践: 概念 关键字: 左右连接 数据表的连接有: 1.内连接(自然连接): 只有两 ...
随机推荐
- 基于C#的机器学习--垃圾邮件过滤
在这一章,我们将建立一个垃圾邮件过滤分类模型.我们将使用一个包含垃圾邮件和非垃圾邮件的原始电子邮件数据集,并使用它来训练我们的ML模型.我们将开始遵循上一章讨论的开发ML模型的步骤.这将帮助我们理解工 ...
- Java HashSet集合的子类LinkedHashSet集合
说明 HashSet保证元素的唯一性,可是元素存放进去是没有顺序的. 在HashSet下面有一个子类java.util.LinkedHashSet,它是 链表 + 哈希表(数组+链表 或者 数组+红黑 ...
- P3802 小魔女帕琪 概率与期望
P3802 小魔女帕琪 题目背景 从前有一个聪明的小魔女帕琪,兴趣是狩猎吸血鬼. 帕琪能熟练使用七种属性(金.木.水.火.土.日.月)的魔法,除了能使用这么多种属性魔法外,她还能将两种以上属性组合,从 ...
- 三个css属性 设置文字竖直居中
display: flex; justify-content:center; align-items:Center;
- struts2 convention插件
1.struts2自2.1以后推荐使用Convention Plugin支持struts零配置支持(引入jar:struts2-convention-plugin-2.x.x.jar)①convent ...
- 使用Robot Framework框架远程操作UNIX系统
bot Framework是一个强大的自动化测试框架,依靠社区力量编写的Test Library为它提供了非常强的扩展性.下面我将介绍的就是如何使用第三方提供的扩展测试库(Test Library)来 ...
- python scoket
一.简介 scoket(套结字)在python就是模块 二.分类 基于文件型(不用) 基于网络型 名字:AF_INET AF_INET6 三.scoket应用 1.基于tcp 长连接:基于tcp的Se ...
- double涉及大数据的时候会变成科学计数法
double b=1.23456789128E8DecimalFormat df = new DecimalFormat("0.00");//精度自己控制保留几位小数点 Strin ...
- 【Four-Week-Task】四周学习CTF之第一周【寒假更新】
写在最前:为了更好地系统学习CTF(楞头冲很惨 别问我怎么知道的 除非你是天才),决定先看再学,先正向再逆向. /* 出版排版规范中,标题序号等级为:第一级,一.二.三.(用顿号):第二级,(一).( ...
- 解决python爬虫requests.exceptions.SSLError: HTTPSConnectionPool(host='XXX', port=443)问题
爬虫时报错如下: requests.exceptions.SSLError: HTTPSConnectionPool(host='某某某网站', port=443): Max retries exce ...