python简单爬豆瓣电影排名
爬豆瓣电影
网站分析:
1 打开https://movie.douban.com,选择 【排行榜】,然后随便选择一类型,我这里选择科幻
2 一直浏览网页,发现没有下一的标签,是下滑再加载的,可以判定使用了 ajax 请求,进行异步的加载

检查请求信息:
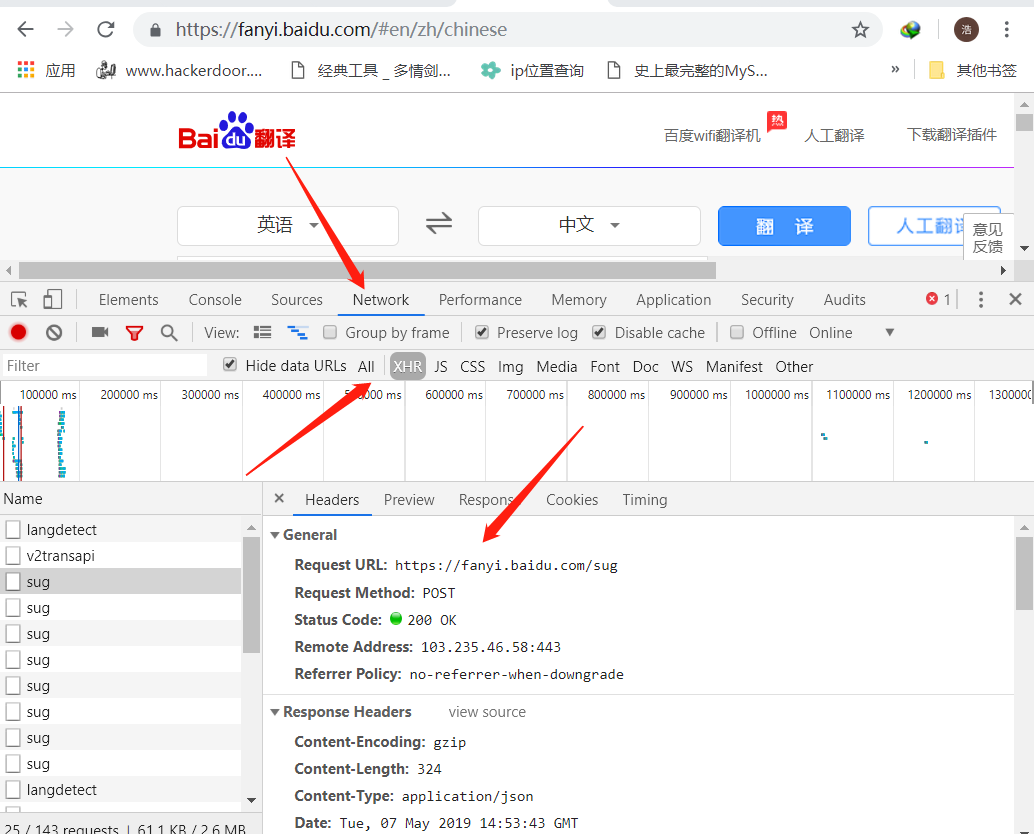
1.右键【检查】>【Network】
2 找url
简单实现代码
from urllib import request
import json
import time headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
# url 信息:interval_id 表示排名段 可修改 ,limit 限制20个,就是每页请求多少个
url = "https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20" rsp = request.urlopen(url)
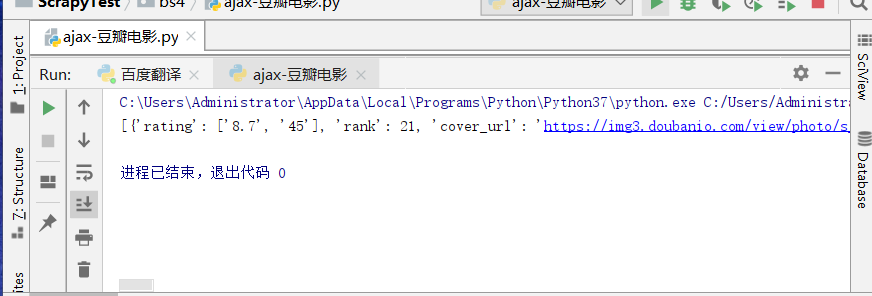
data = rsp.read().decode() data = json.loads(data) print(data)
运行效果
优化输出格式,代码
from urllib import request
import json url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20" rsp = request.urlopen(url)
data = rsp.read().decode() data = json.loads(data) #遍历输出每个'k'和‘v’的值
for item in data:
print("排名:", item['rank'],"\n",
"名称:",item['title'],"\n",
"类型:",item['types'],"\n",
"主演:",item['actors'],"\n",
"国家:",item['regions'],"\n",
"分数:",item['score'],"\n",
"图片:",item['cover_url'],"\n---------------")
优化效果

好了,这样的效果,看起来更顺眼了
python简单爬豆瓣电影排名的更多相关文章
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
- Scala学习之爬豆瓣电影
简单使用Scala和Jsoup对豆瓣电影进行爬虫,技术比較简单易学. 写文章不易,欢迎大家採我的文章,以及给出实用的评论,当然大家也能够关注一下我的github:多谢. 1.爬虫前期准备 找好须要抓取 ...
- 2_爬豆瓣电影_ajax动态加载
爬豆瓣 什么是 AJAX ? AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. AJAX = Asynchronous JavaScript and XML(AJAX = 异步 ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- python爬虫--用xpath爬豆瓣电影
步骤 将目标网站下的页面抓取下来 将抓取下来的数据根据一定规则进行提取 具体流程 将目标网站下的页面抓取下来 1. 倒库 import requests 2.头信息(有时候可不写) headers ...
- 一、python简单爬取静态网页
一.简单爬虫框架 简单爬虫框架由四个部分组成:URL管理器.网页下载器.网页解析器.调度器,还有应用这一部分,应用主要是NLP配合相关业务. 它的基本逻辑是这样的:给定一个要访问的URL,获取这个ht ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- Python简单爬取图书信息及入库
课堂上老师布置了一个作业,如下图所示: 就是简单写一个借书系统. 大概想了一下流程,登录-->验证登录信息-->登录成功跳转借书界面-->可查看自己的借阅书籍以及数量... 登录可以 ...
随机推荐
- Windows平台编译libevent
使用VisualStudio来编译,我的电脑上安装的是VS2013.1.在开始菜单项里面(或者在VS安装路径中)打开Developer Command Prompt for VS2013.exe2.在 ...
- AYITOJ-括号序列-栈的入门
题目描述 给定一个由括号组成的字符串 问其是否为一个合法的括号序列 合法的括号序列的定义如下 1. 空字符串是合法的括号序列 2. 若字符串A是合法的括号序列, 那么{A},[A],(A)也是合法的括 ...
- Java 内部类,成员类,局部类,匿名类等
根据内部类的位置不同,可将内部类分为 :成员内部类与局部内部类. class outer{ class inner{//成员内部类 } public void method() { class loc ...
- 1.1_springboot2.x与缓存原理介绍&使用缓存
一.springboot与缓存介绍&使用缓存 1.JSR107 JAVA Cahing定义了5个核心接口,分别是CachingProvider.CacheManager.Cache.Entry ...
- Django之13种必会查询
1.常见的13中查询方式(必须记住) <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> g ...
- appium + python 自动化调试手机时 UiAutomator exited unexpectedly with code 0, signal null
放上appium报错图,appium在手机里安装了appium setting 和unlock 软件,输入法也被变成了appium input ,但是就是点不到目标软件,手机也可以被cmd adb ...
- Print Article /// 斜率优化DP oj26302
题目大意: 经典题 数学分析 G(a,b)<sum[i]时 a优于b G(a,b)<G(b,c)<sum[i]时 b必不为最优 #include <bits/stdc++.h& ...
- 3_基本框架_VMXON
原理参考 3卷 23.7节等 本节实施流程参考Intel手册: 3卷 31.5节 1 vt整体框架; 首先 开锁: 1 开启 Cr4.[VMXE]: 上一节,检测了 VMX 需要的环境:最后一个 CR ...
- Georgia and Bob
Georgia and Bob 给出一个严格递增的正整数数列\(\{a_i\}\),每一次操作可以对于其中任意一个数减去一个正整数,但仍然要保证数列的严格递增性,现在两名玩家轮流操作,不能操作的玩家判 ...
- python事件调度库sched
事件调度 sched模块内容很简单,只定义了一个类.它用来最为一个通用的事件调度模块. class sched.scheduler(timefunc, delayfunc)这个类定义了调度事件的通用接 ...