python爬虫-爬取你想要的小姐姐
一、准备
1. 原地址
2. 检查html发现,网页是有规则的分页, 最大图片的class为pic-large
二、代码
import requests
import os
from bs4 import BeautifulSoup url = 'http://www.win4000.com/wallpaper_detail_157712.html'
imgmkdir = 'D://Download//ghost_1//' # 获取网页url
def getUrlList():
imgUrlList = []
for i in range(0, 10):
imgUrl = ''
url_split = url.split('.html')
if not i == 0:
imgUrl += url_split[0] + '_' + str(i) + '.html'
# print(imgUrl)
imgUrlList.append(imgUrl) return imgUrlList # 下载图片
def downImg(imgUrl):
try:
if not os.path.exists(imgmkdir):
os.mkdir(imgmkdir)
if not os.path.exists(imgUrl):
r = requests.get(imgUrl)
r.raise_for_status()
# 使用with语句可以不用自己手动关闭已经打开的文件流
imgpath = imgmkdir + imgUrl.split('/')[-1]
# 开始写文件, wb表示写二进制文件
with open(imgpath, 'wb') as f:
f.write(r.content)
print(imgUrl + '【爬取完成】')
else:
print(imgUrl.split('/')[-1] + '【文件已存在】')
except Exception as e:
print("爬取失败" + str(e)) # 获取imgHtml标签
def getcontent(soup):
for i in soup.find_all('img', class_='pic-large'):
imgsrc = i['src']
if imgsrc.find('http') >= 0 or imgsrc.find('https') >= 0:
# 下载图片
downImg(imgsrc) # 根据url获取html源码
def getHtmlByUrl(htmlUrl):
htmlText = requests.get(htmlUrl).content
# 使用beautifulSoup解析html
soup = BeautifulSoup(htmlText, 'lxml') return soup def main():
htmlUrlList = getUrlList()
for url in htmlUrlList:
htmltext = getHtmlByUrl(url)
getcontent(htmltext) if __name__ == '__main__':
main()
三、结果
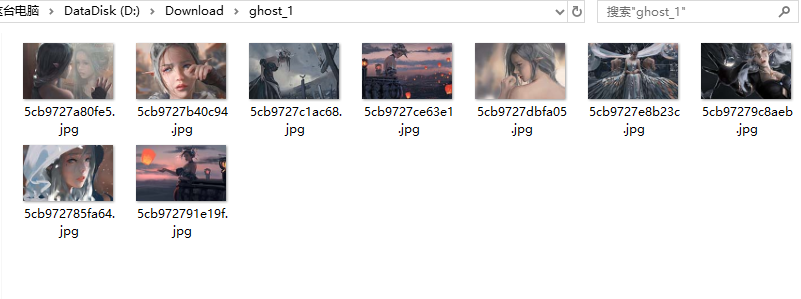
四、总结
代码用比较笨的方法来获取,先试水
python爬虫-爬取你想要的小姐姐的更多相关文章
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- nginx代理mysql
实验环境: 两台编译安装的mysql 一台编译安装的nginx 192.168.3.1 ...
- OpenFOAM显示残差
本文主要讲解两种方法用来显示OpenFOAM的计算残差,一种是采用OpenFOAM自带的foamMonitor来输出残差,另一种就是大家经常看见的采用pyFoam来输出残差.不管采用哪一种方法都必须安 ...
- Ibatis自动解决sql注入机制
疑问1:为什么IBatis解决了大部分的sql注入?(实际上还有部分sql语句需要关心sql注入,比如like) 之前写Java web,一直使用IBatis,从来没有考虑过sql注入:最近写php( ...
- C# 复制数组容易踩到的坑--引用类型与值类型
原文链接:https://my.oschina.net/u/3744313/blog/1794235 笔者近期做的项目里大量使用了数组,而在使用过程中,笔者曾经遇到了一个比较低级的问题:如何将一个数组 ...
- [转]MyEclipse基础学习:Java EE Learning Center
我就不翻译了,直接给出Java EE学习中心的原文链接: Java EE Learning Center 另外,给出MyEclipse IDE 环境中Apache Tomcat server服务器正常 ...
- Java_jdbc 基础笔记之二 数据库连接
/** * DriverManager 类是驱动程序管理器类 * 1)可以通过重载的getConnection()方法获取数据库的连接,较为方便 * 2)可以同时管理多个驱动程序:若注册了多个数据库连 ...
- selenium操作下拉滚动条的几种方法
数据采集中,经常遇到动态加载的数据,我们经常使用selenium模拟浏览器操作,需要多次下拉刷新页面才能采集到所有的数据,就此总结了几种selenium操作下拉滚动条的几种方法 我这里演示的是Java ...
- Vuejs函数式组件,你值得拥有(1)
函数式组件在React社区很流行使用,那么在vue里面我们要怎么用呢 下面会涉及到的知识点: 高阶函数.状态.实例.vue组件 什么是函数式组件 我们可以把函数式组件想像成组件里的一个函数,入参是渲染 ...
- 011 client系列案例
一:Client系列 1.说明 clientWidth:不包括边框的可视区的宽 clientHeight:可视区的高,不包括边框 clientLeft:左边框的宽度 clientTop:上面框的宽度 ...
- 移动端IM系统的协议选型:UDP还是TCP?(转)
源: 移动端IM系统的协议选型:UDP还是TCP?