机器学习理论基础学习14.2---线性动态系统-粒子滤波 particle filter
一、背景
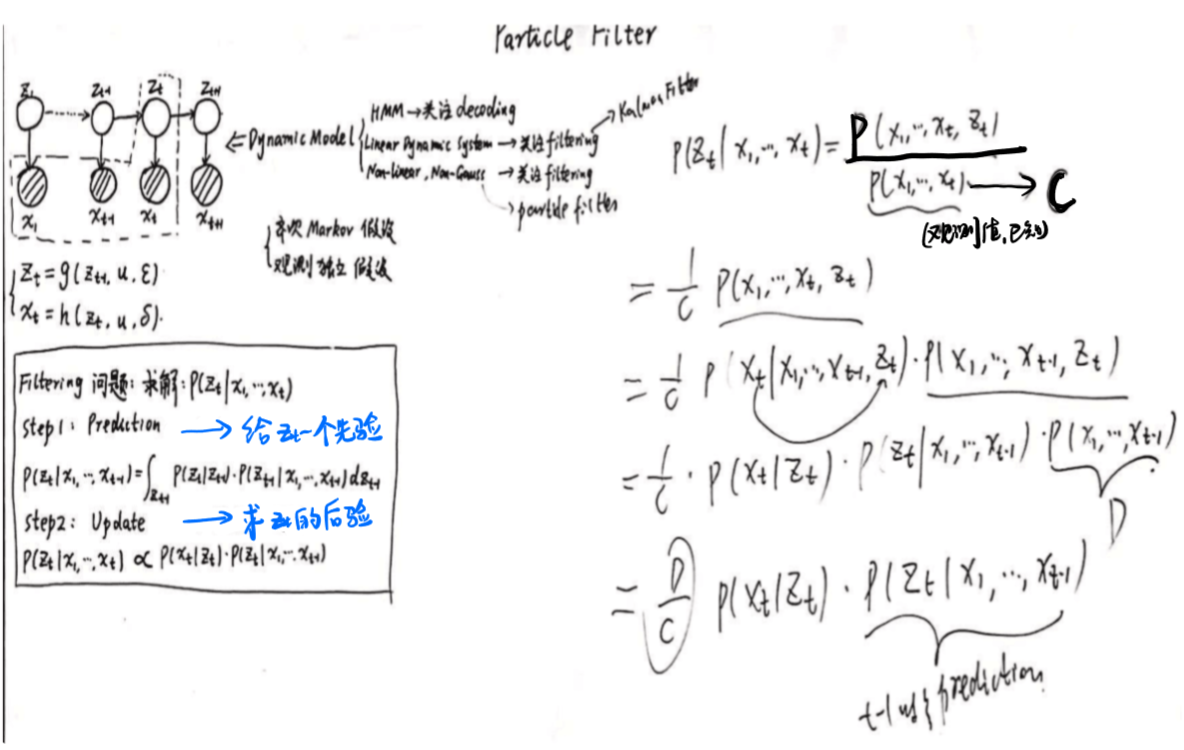
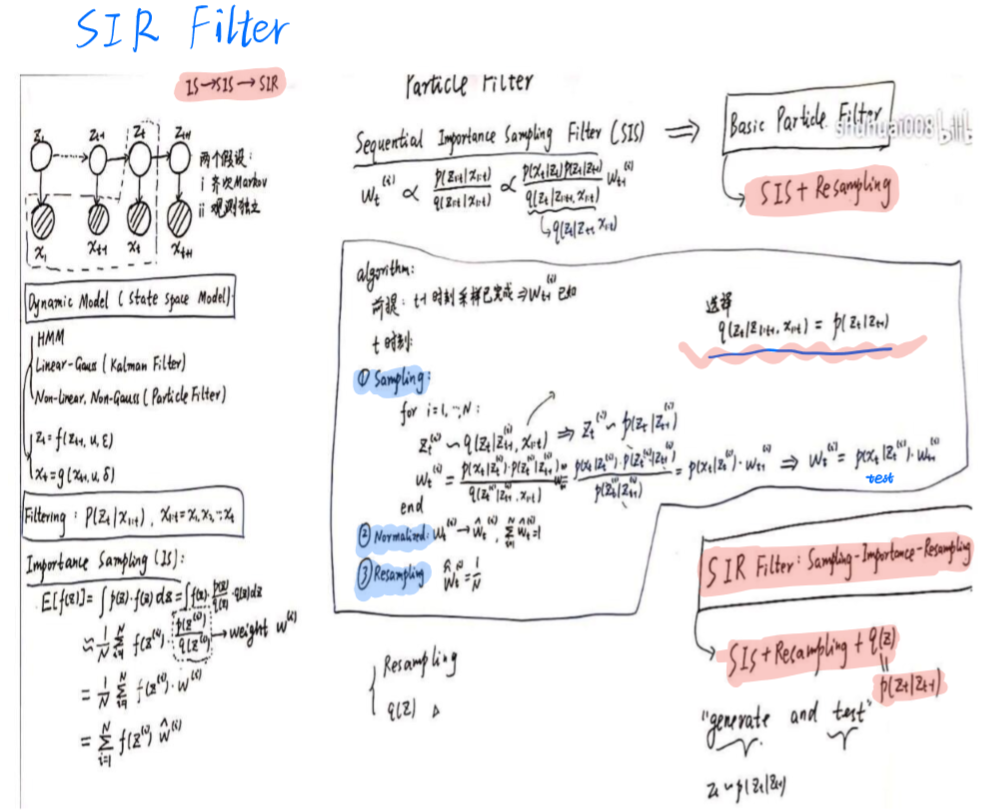
与卡曼滤波不同的是,粒子滤波假设隐变量之间(隐变量与观测变量之间)是非线性的,并且不满足高斯分布,可以是任意的关系。
求解的还是和卡曼滤波一样,但由于分布不明确,所以需要用采样的方法求解。
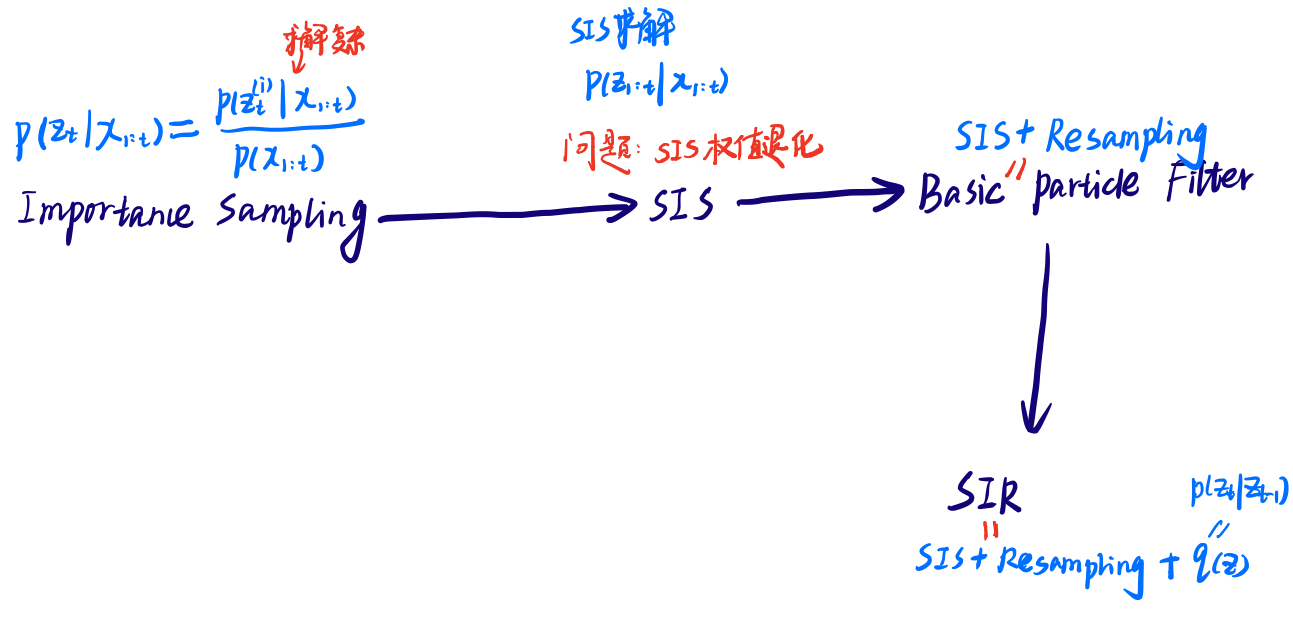
二、重要性采样(importance sampling & SIS)
重要性采样(IS)需要计算p(zt|x1,...,t), t与t-1之间没有递推关系,不易求解
为此引入SIS,转换成求解p(z1,...t|x1,...t),且能够推出递推关系,方便求解

三、重采样Basic Particle Filter
但SIS也有一个严重问题,权重会随着时间增长呈指数递减。
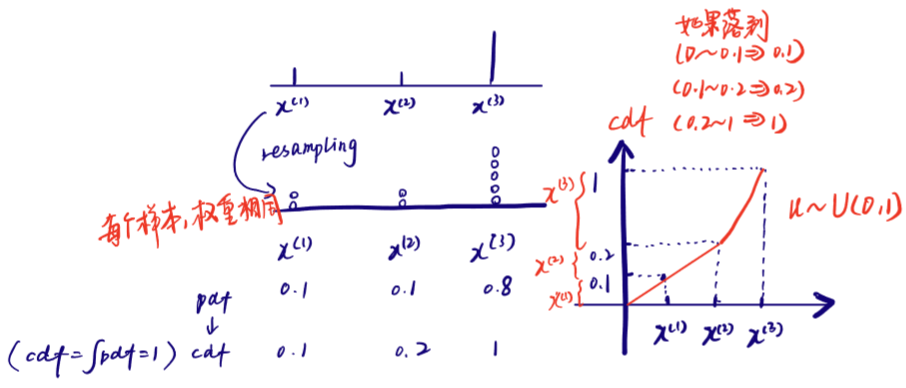
为此引入Basic particle filter = SIS + Resampling(权重大的,多采样)
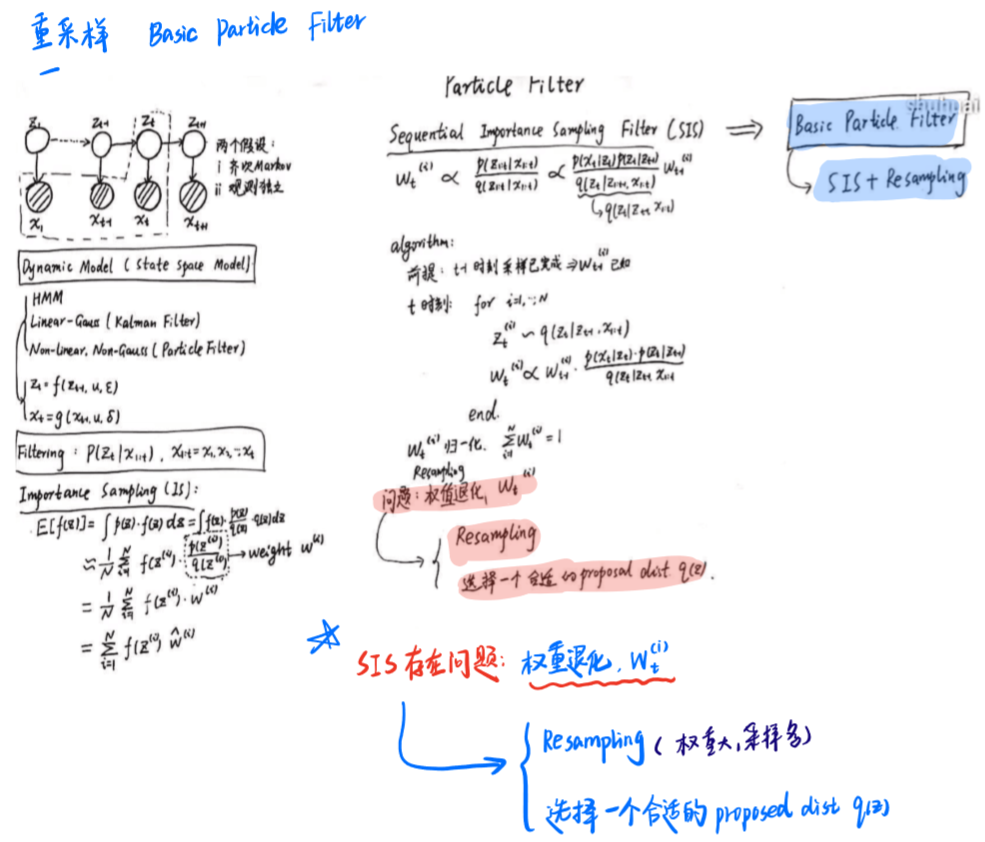
四、SIR Filter
SIR filter与basic particle filter区别在于,选择q(zt|z1,...,zt-1,x1,...,xt) = p(zt|zt-1)
SIR filter = SIS + resampling + q(z)
机器学习理论基础学习14.2---线性动态系统-粒子滤波 particle filter的更多相关文章
- 机器学习理论基础学习14.1---线性动态系统-卡曼滤波 Kalman filter
一.背景 动态模型 = 图 + 时间 动态模型有三种:HMM.线性动态系统(kalman filter).particle filter 线性动态系统与HMM的区别是假设相邻隐变量之间满足线性高斯分布 ...
- 机器学习理论基础学习12---MCMC
作为一种随机采样方法,马尔科夫链蒙特卡罗(Markov Chain Monte Carlo,以下简称MCMC)在机器学习,深度学习以及自然语言处理等领域都有广泛的应用,是很多复杂算法求解的基础.比如分 ...
- 机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题 ...
- 机器学习理论基础学习3.1--- Linear classification 线性分类之感知机PLA(Percetron Learning Algorithm)
一.感知机(Perception) 1.1 原理: 感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别,分别是+1和-1,属于判别模型. 假设训练数据集是线性可分的,感知机学习的目标 ...
- 机器学习理论基础学习3.3--- Linear classification 线性分类之logistic regression(基于经验风险最小化)
一.逻辑回归是什么? 1.逻辑回归 逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的. logistic回归也称为逻辑回归,与线性回归这样输出 ...
- 机器学习理论基础学习3.4--- Linear classification 线性分类之Gaussian Discriminant Analysis高斯判别模型
一.什么是高斯判别模型? 二.怎么求解参数?
- 机器学习理论基础学习3.5--- Linear classification 线性分类之朴素贝叶斯
一.什么是朴素贝叶斯? (1)思想:朴素贝叶斯假设 条件独立性假设:假设在给定label y的条件下,特征之间是独立的 最简单的概率图模型 解释: (2)重点注意:朴素贝叶斯 拉普拉斯平滑 ...
- 机器学习理论基础学习4--- SVM(基于结构风险最小化)
一.什么是SVM? SVM(Support Vector Machine)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性和非线性两大类. ...
- 机器学习理论基础学习5--- PCA
一.预备知识 减少过拟合的方法有:(1)增加数据 (2)正则化(3)降维 维度灾难:从几何角度看会导致数据的稀疏性 举例1:正方形中有一个内切圆,当维度D趋近于无穷大时,圆内的数据几乎为0,所有的数据 ...
随机推荐
- java框架---->quartz的使用(一)
Quartz 是个开源的作业调度框架,为在 Java 应用程序中进行作业调度提供了简单却强大的机制.今天我们就来学习一下它的使用,这里会分篇章对它进行介绍.只是希望能有个人,在我说没事的时候,知道我不 ...
- C#网络编程TCP通信实例程序简单设计
C#网络编程TCP通信实例程序简单设计 采用自带 TcpClient和TcpListener设计一个Tcp通信的例子 只实现了TCP通信 通信程序截图: 压力测试服务端截图: 俩个客户端链接服务端测试 ...
- Spark学习笔记--Spark在Windows下的环境搭建
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
- Elasticsearch学习之深入聚合分析四---案例实战
1. 需求:比如有一个网站,记录下了每次请求的访问的耗时,需要统计tp50,tp90,tp99 tp50:50%的请求的耗时最长在多长时间tp90:90%的请求的耗时最长在多长时间tp99:99%的请 ...
- 基于spring-cloud的微服务(2) eureka服务提供方的注册和消费方的消费
启动Eureka注册中心之后,服务提供方就可以注册到Eureka上去(作为一个Eureka的客户端) 我们使用IDEA提供的spring initializer来新建一个springcloud项目 填 ...
- golang学习资料[Basic]
http://devs.cloudimmunity.com/gotchas-and-common-mistakes-in-go-golang/index.html 基础语法 <Go By Exa ...
- Spark2 Dataset多维度统计cube与rollup
val df6 = spark.sql("select gender,children,max(age),avg(age),count(age) from Affairs group by ...
- ElasticSearch 聚合函数
一.简单聚合 桶 :简单来说就是满足特定条件的文档的集合. 指标:大多数 指标 是简单的数学运算(例如最小值.平均值.最大值,还有汇总),这些是通过文档的值来计算. 桶能让我们划分文档到有意义的集合, ...
- PAT甲1101 Quick Sort
1101 Quick Sort (25 分) There is a classical process named partition in the famous quick sort algorit ...
- 基于Solr和Zookeeper的分布式搜索方案的配置
1.1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...