HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货!
我的集群机器情况是 bigdatamaster(192.168.80.10)、bigdataslave1(192.168.80.11)和bigdataslave2(192.168.80.12)
然后,安装目录是在/home/hadoop/app下。
官方建议在master机器上安装Hue,我这里也不例外。安装在bigdatamaster机器上。
Hue版本:hue-3.9.0-cdh5.5.4
需要编译才能使用(联网) 说给大家的话:大家电脑的配置好的话,一定要安装cloudera manager。毕竟是一家人的。
同时,我也亲身经历过,会有部分组件版本出现问题安装起来要个大半天时间去排除,做好心里准备。废话不多说,因为我目前读研,自己笔记本电脑最大8G,只能玩手动来练手。
纯粹是为了给身边没高配且条件有限的学生党看的! 但我已经在实验室机器群里搭建好cloudera manager 以及 ambari都有。
大数据领域两大最主流集群管理工具Ambari和Cloudera Manger
Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
说在前面的话:
[hadoop]这块,配置如下 (注意官网说,WebHdfs 或者 HttpFS)(一般用WebHdfs,那是因为非HA集群。如果是HA集群,则必须还要配置HttpFS)
配置 WebHDFS 或者 HttpFS
Hue 可以通过下面两种方式访问 Hdfs 中的数据:
WebHDFS:提供高速的数据传输,客户端直接和 DataNode 交互。HttpFS:一个代理服务,方便与集群外部的系统集成。
两者都支持 HTTP REST API,但是 Hue 只能配置其中一种方式;对于 HDFS HA部署方式,只能使用 HttpFS。
- 1、对于 WebHDFS 方式,在每个节点上的 hdfs-site.xml 文件添加如下配置并重启服务:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
- 2、 配置 Hue 为其他用户和组的代理用户。对于 WebHDFS 方式,在 core-site.xml 添加:
<!-- Hue WebHDFS proxy user setting -->
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
对于 HttpFS 方式,在 /etc/hadoop-httpfs/conf/httpfs-site.xml 中添加下面配置并重启 HttpFS 进程:
<!-- Hue HttpFS proxy user setting -->
<property>
<name>httpfs.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>httpfs.proxyuser.hue.groups</name>
<value>*</value>
</property>
对于 HttpFS 方式,在 core-site.xml 中添加下面配置并重启 hadoop 服务:
<property>
<name>hadoop.proxyuser.httpfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.groups</name>
<value>*</value>
</property>
- 3、修改 /etc/hue/conf/hue.ini 中 hadoop.hdfs_clusters.default.webhdfs_url 属性。
对于 WebHDFS:
webhdfs_url=http://master:50070/webhdfs/v1/
对于 HttpFS:
webhdfs_url=http://master:14000/webhdfs/v1/
https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_ig_hue_config.html#concept_ezg_b2s_hl

首先,这是官网提供的参考步骤
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.0/manual.html
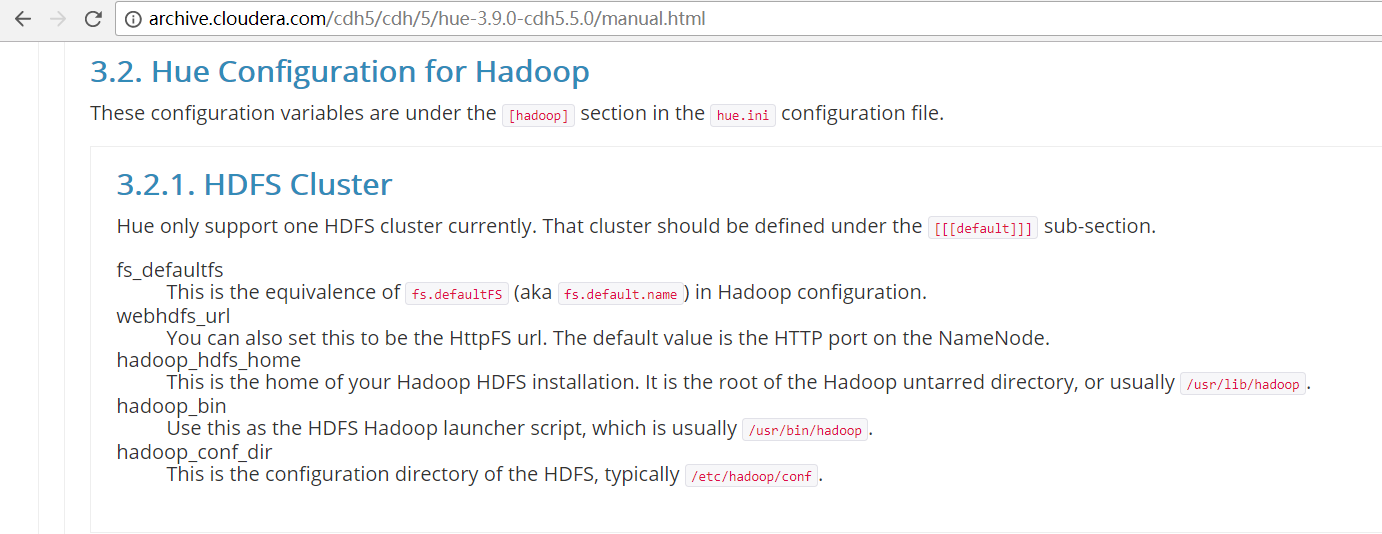
一、以下是默认的配置文件
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
# HA support by using HttpFs [[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://localhost:8020 # NameNode logical name.
## logical_name= # Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is for HttpFs.
## webhdfs_url=http://localhost:50070/webhdfs/v1 # Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false # In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True # Directory of the Hadoop configuration
## hadoop_conf_dir=$HADOOP_CONF_DIR when set or '/etc/hadoop/conf'
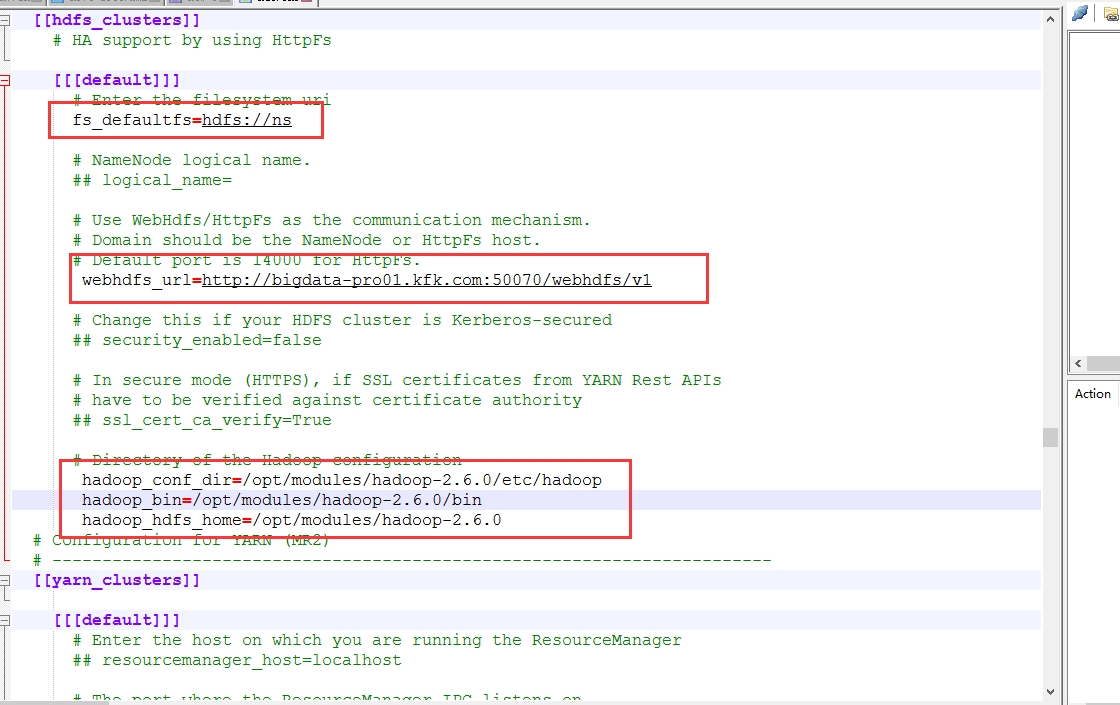
二、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的hdfs_clusters模块)
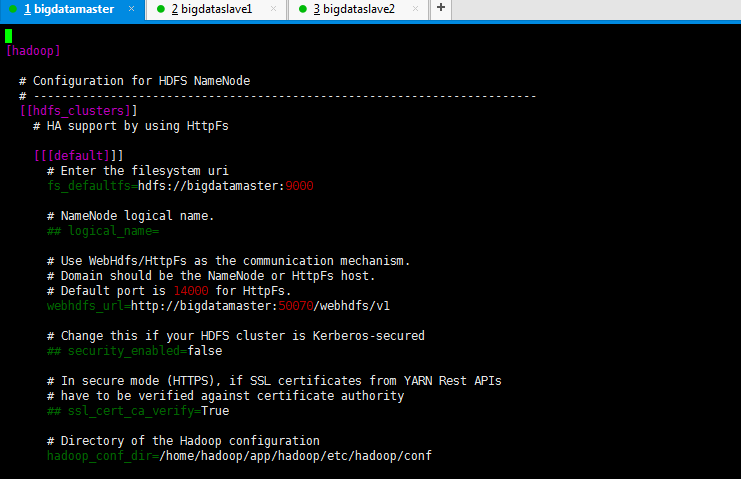
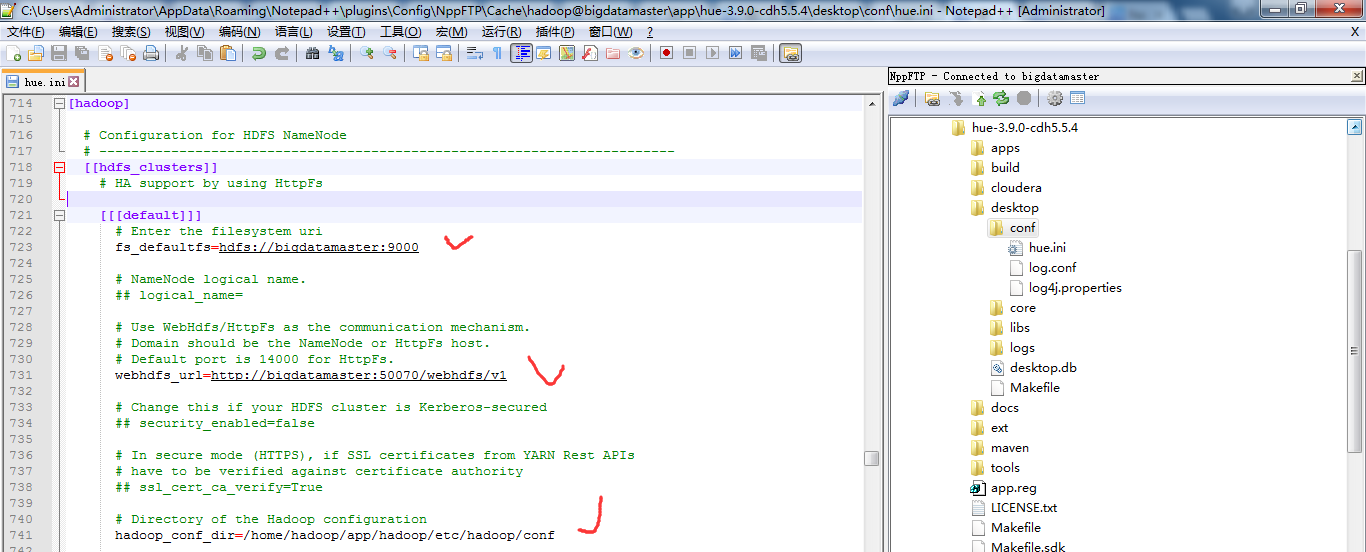
最终我的非HA配置信息如下
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
# HA support by using HttpFs [[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://bigdatamaster:9000 # NameNode logical name.
## logical_name= # Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is for HttpFs.
webhdfs_url=http://bigdatamaster:50070/webhdfs/v1 # Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false # In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True # Directory of the Hadoop configuration
hadoop_conf_dir=/home/hadoop/app/hadoop/etc/hadoop/conf
三、以下是跟我机器集群匹配的配置文件(HA集群下怎么配置Hue的hdfs_clusters模块)
hadoop-2.6.0.tar.gz的集群搭建(5节点)
注意,在hdfs_clusters模块里,若要配置HA的话,则必须是要用到HttpFs。请看Hue的官网配置例子
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.4/manual.html#_install_hue
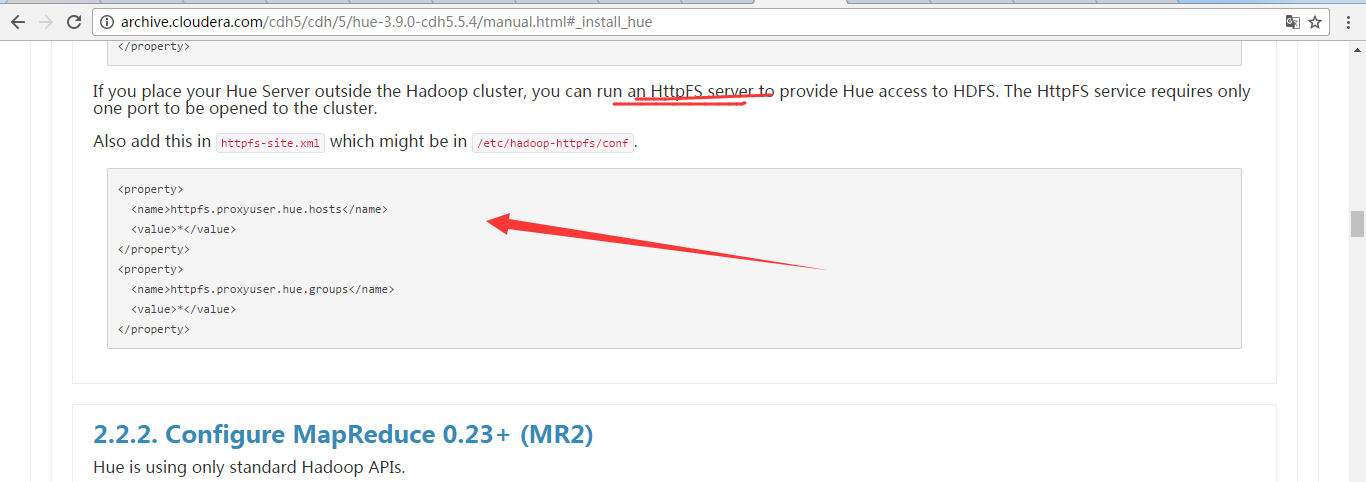
注意: 在$HADOOP_HOME/etc/hadoop/下的httpfs-site.xml。(djt11、djt12、djt12、djt14和djt15都需要配置)
先配置好如下
<property>
<name>httpfs.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>httpfs.proxyuser.hue.groups</name>
<value>*</value>
</property>
同时,还要配置WebHdfs,别忘记啦!
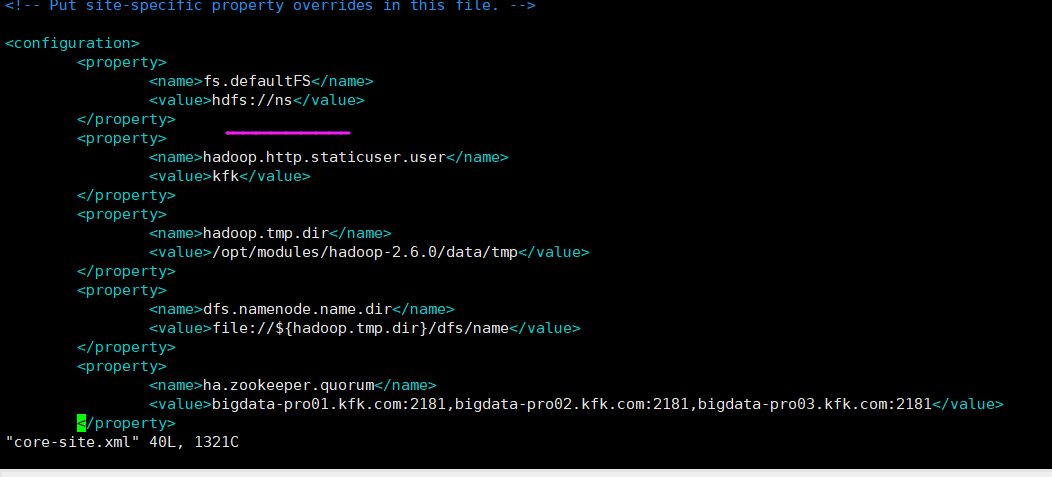
在core-site.xml 和 hdfs-site.xml下,添加如下

core-site.xml下

<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
hdfs-site.xml下
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
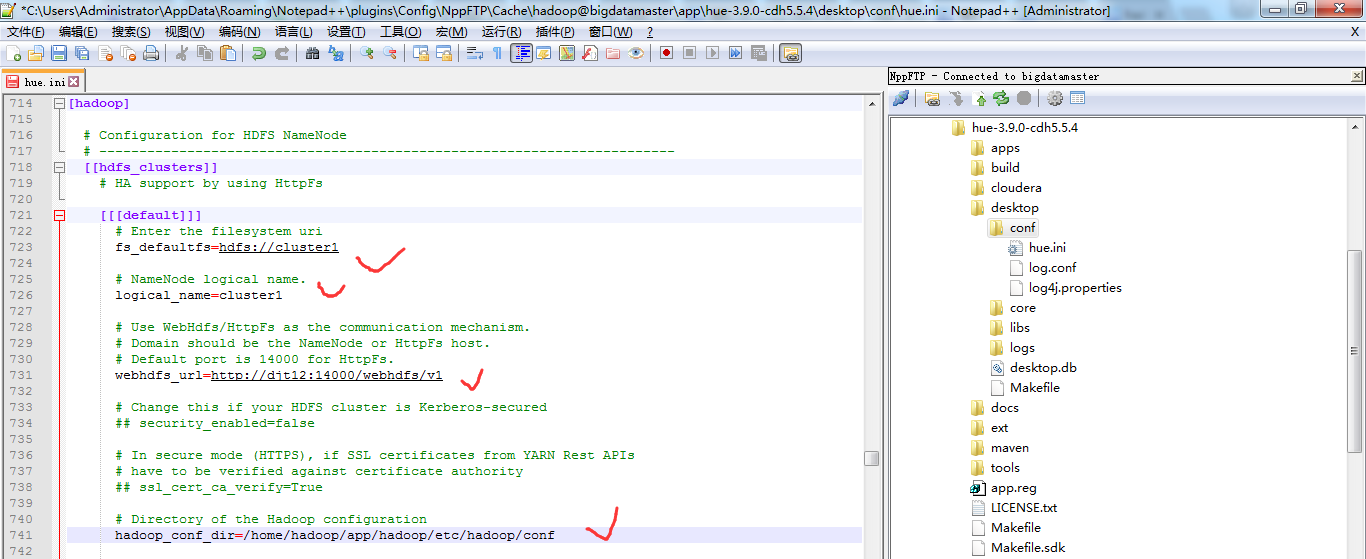
hdfs_cluster模块
[[hdfs_clusters]]
# HA support by using HttpFs [[[default]]]
# Enter the filesystem uri
##--Customer Configuration --##
fs_defaultfs=hdfs://cluster1 # NameNode logical name.
logical_name=cluster1 # Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is for HttpFs.
##--Customer Configuration --##
webhdfs_url=http://djt12:14000/webhdfs/v1 # Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false # In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True # Directory of the Hadoop configuration
hadoop_conf_dir=/home/hadoop/app/hadoop/etc/hadoop/conf
成功!
同时,大家还要安装好HttpFS,怎么安装,请移步我下面的博客
CentOS和Ubuntu系统下安装 HttpFS (助推Hue部署搭建)
因为配置了httpfs,hue才能去操作hdfs中的数据。
或者,比如,我的HA集群是如下

hue.ini文件
在hadoop的core-site.xml下面加上
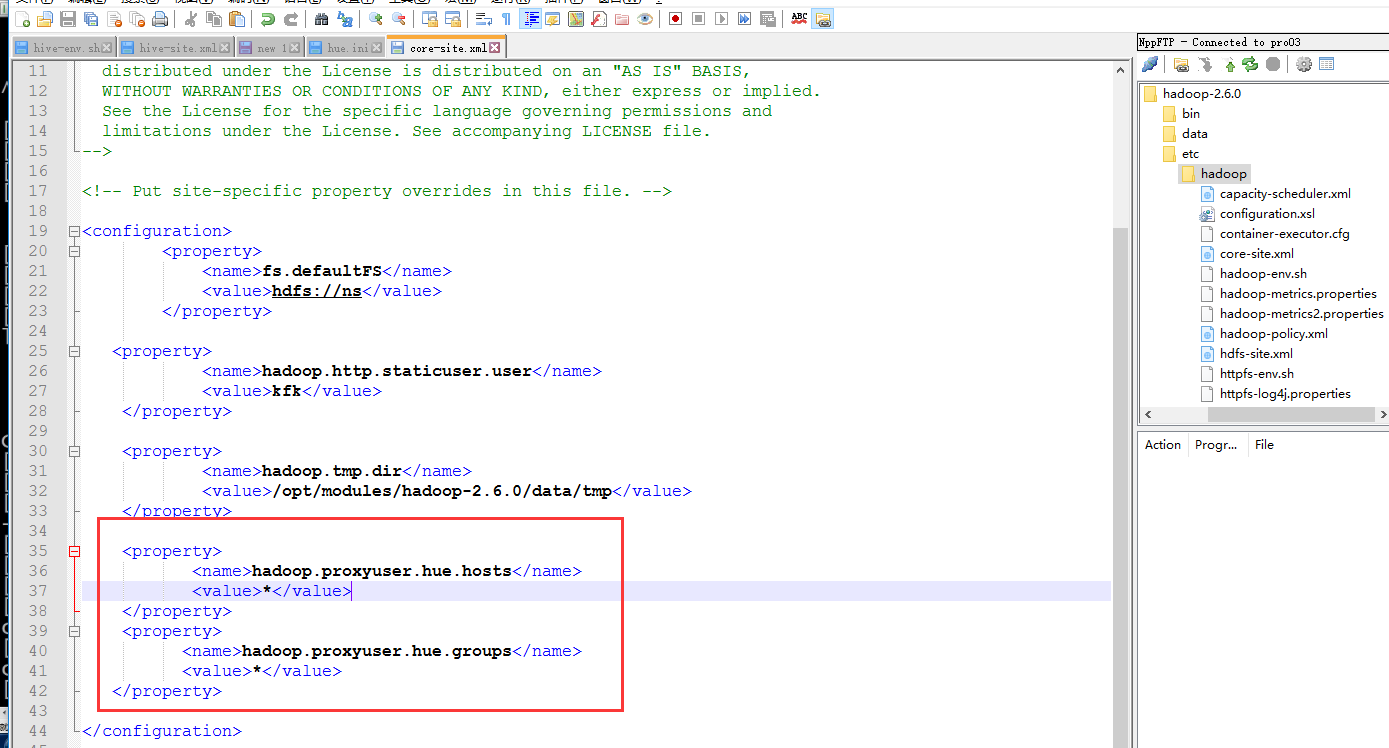
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
然后,把这修改的core-site.xml分发到每台机器上。
分发完之后我们重启一下服务
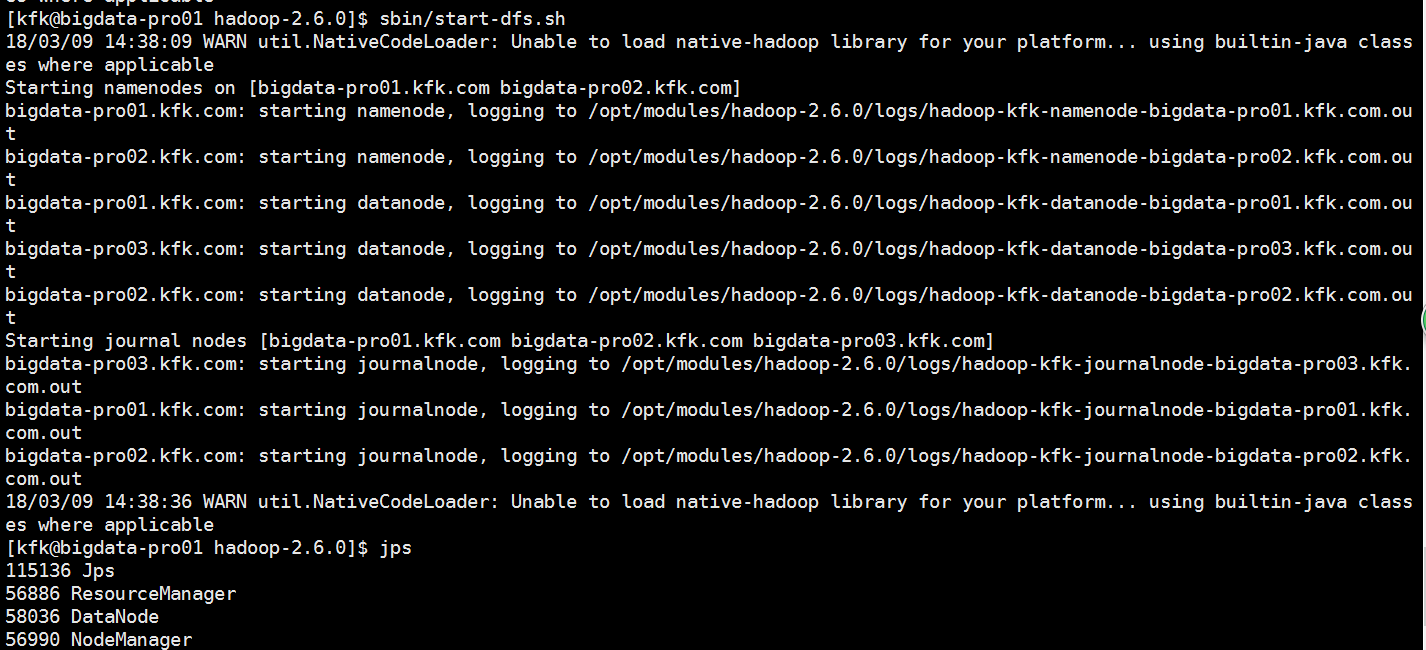
把hue也启动一下
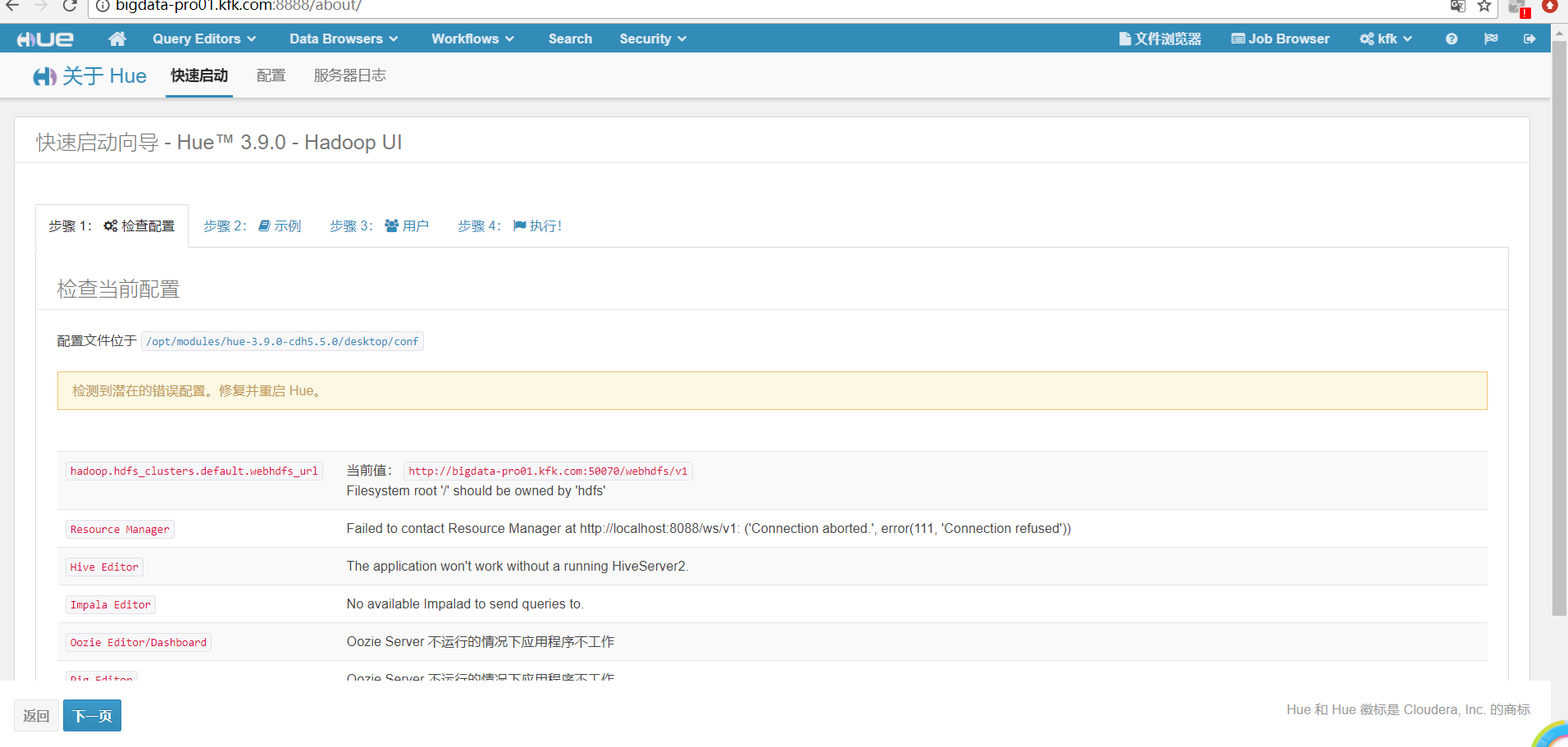
再次进入Hue的可视化界面
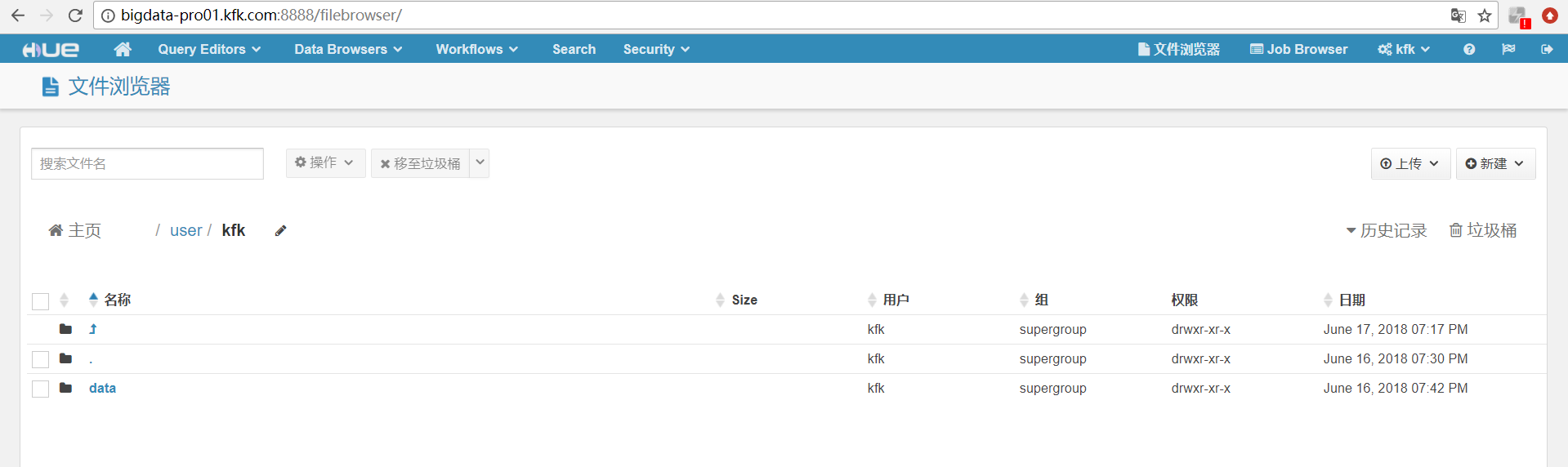
参考
http://gethue.com/how-to-build-hue-on-ubuntu-14-04-trusty/
http://gethue.com/how-to-configure-hue-in-your-hadoop-cluster/
http://cloudera.github.io/hue/docs-3.8.0/manual.html#_hadoop_configuration
http://docs.hortonworks.com/HDPDocuments/HDP1/HDP-1.3.2/bk_installing_manually_book/content/rpm-chap-hue-5.html
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)的更多相关文章
- HUE配置文件hue.ini 的filebrowser模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的yarn_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hbase模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的impala模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hive和beeswax模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的zookeeper模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的pig模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 一.默认的pig配置文件 ########################################################################### ...
- HUE配置文件hue.ini 的liboozie和oozie模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
随机推荐
- Windows could not set the offline local information.Error code:0X80000001解决方法
我的笔记本是联想Y460(白色) 昨天在重装系统的时候遇到如下错误:Windows could not set the offline local information.Error code:0X8 ...
- 201709015工作日记--上下文的理解,ASM
1.Android上下文理解 Android上下文对象,在Context中封装一个所谓的“语境”,Activity.Service.Application都继承自Context,所以在这三者创建时都会 ...
- hibernate 一对多,由谁维护性能最优
举例如下 Customer类: public class Customer { private int id; private String name; private Set orders = ne ...
- CAS实战の遇到的问题
1.客户端启动报错,报错信息如下: 严重: Exception starting filter CAS Single Sign Out Filter java.lang.IllegalArgument ...
- C++虚函数表(vtbl)
C++的虚函数的作用就是为了实现多态的机制,利用内存的指针偏移来实现将基类型的指针指向的内存空间用子类对象来初始化.这样经过内部虚表的运作,实现可以通过基类指针来调用子类所定义的方法. 这种技术,其实 ...
- List<T>用法
所属命名空间:System.Collections.Generic public class List<T> : IList<T>, ICollection<T>, ...
- vsftpd 常见问题
一.vsftp服务能开启却连接不上的解决办法: 用虚拟机装了centos,vsftp是用centos自带的.启动vsftd服务后却一直连不上,原因是被防火墙给挡了. 查看防火墙状态:/etc/init ...
- azkaban作业参数使用介绍
azkaban作业参数使用介绍 参数传递是调度系统工作流运行时非常重要的一部分,工作流的执行,单个作业的执行,多个工作流之间的依赖执行,历史任务重算,都涉及参数传递和同步. azkaban的工作流中的 ...
- .net core 读取本地指定目录下的文件
项目需求 asp.net core 读取log目录下的.log文件,.log文件的内容如下: xxx.log ------------------------------------------beg ...
- 935. Knight Dialer
A chess knight can move as indicated in the chess diagram below: . This time, we place o ...