吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙。



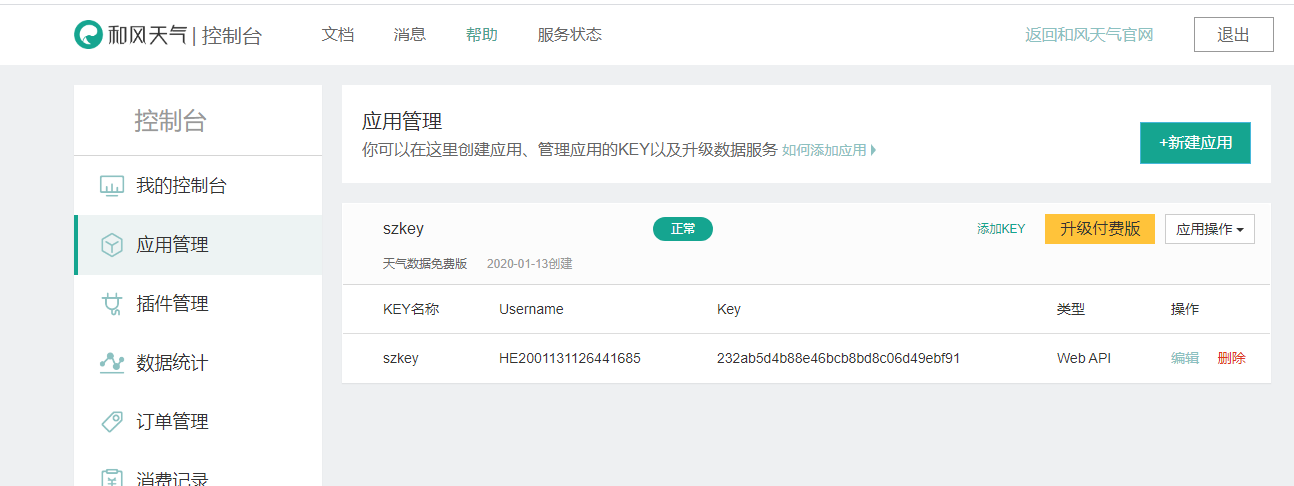
这个key现在是要自己创建的,名称自己写,key值可以不写,创建的时候会自动生成。
接下来就是要阅读这个API文档。

包括上面怎么创建获取这个key这个API文档也有介绍的。

选择API这部分来阅读。
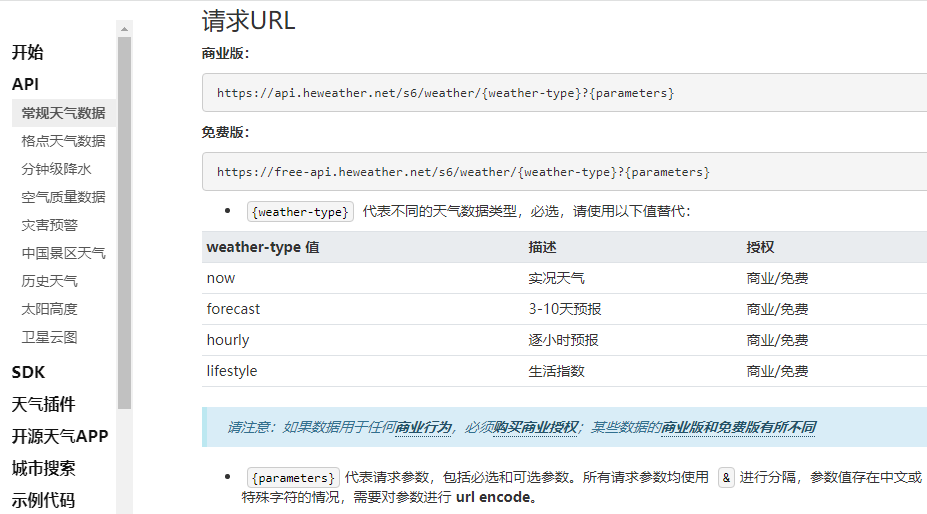
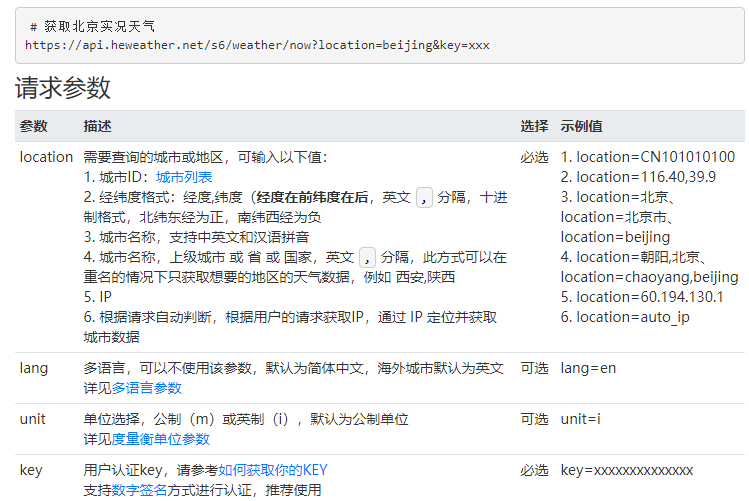
接口地址:
#获取城市列表
import requests url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
response.encoding='utf8'
data = response.text
data_1 = data.split('\n')
print(data_1)
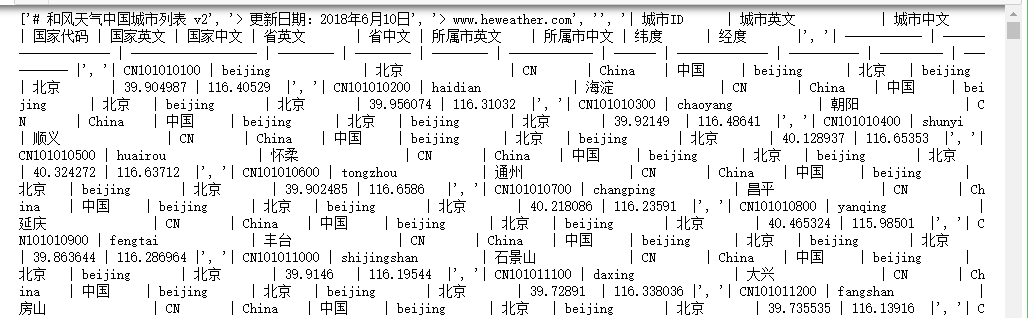

for i in range(3):
data_1.remove(data_1[0])
for item in data_1:
print(item[0:11])

获取城市ID后,下一步就是调用接口获取数据。
#获取城市数据
import time
import requests url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
response.encoding='utf8'
data = response.text
data_1 = data.split('\n')
for i in range(3):
data_1.remove(data_1[0])
for item in data_1:
url = 'https://free-api.heweather.net/s6/weather/forecast?location='+item[1:13]+'&key=232ab5d4b88e46bcb8bd8c06d49ebf91'
strhtml = requests.get(url)
time.sleep(3)
print(strhtml.text)
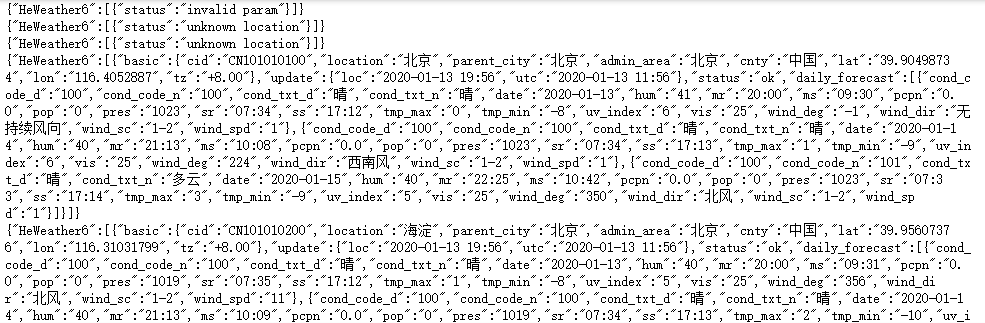
可以看到数据是以json数据格式返回的。如果要将返回的数据解析出来可以使用for循环。
可以使用JSON在线结构化的工具观察数据结构,网址:http://www.json.org.cn/tools/JSONEditorOnline/index.htm


上图左边是原Json数据,右边显示的是它的保存数据的结构。
#获取城市数据
import os
import time
import requests url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
response.encoding='utf8'
data = response.text
data_1 = data.split('\n')
for i in range(3):
data_1.remove(data_1[0]) temp = 1
for item in data_1:
url = 'https://free-api.heweather.net/s6/weather/forecast?location='+item[1:13]+'&key=232ab5d4b88e46bcb8bd8c06d49ebf91'
strhtml = requests.get(url)
time.sleep(3)
dic = strhtml.json()
if(temp>3):
#获取风向值
print(dic['HeWeather6'][0]['daily_forecast'][0]['wind_dir'])
#获取最低气温
print(dic['HeWeather6'][0]['daily_forecast'][0]['tmp_min'])
#获取最高气温
print(dic['HeWeather6'][0]['daily_forecast'][0]['tmp_max'])
print('================')
else:
temp+=1

吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/' strhtml = requests.get(url) print(strhtml.text) URL='h ...
- 吴裕雄--天生自然python学习笔记:爬取我国 1990 年到 2017年 GDP 数据并绘图显示
绘制图形所需的数据源通常是不固定的,比如,有时我们会需要从网页抓取, 也可能需从文件或数据库中获取. 利用抓取网页数据技术,把我国 1990 年到 2016 年的 GDP 数据抓取出来 ,再利用 Ma ...
- 吴裕雄--天生自然python学习笔记:Python3 错误和异常
语法错误 Python 的语法错误或者称之为解析错,是初学者经常碰到的,如下实例 >>>while True print('Hello world') File "< ...
随机推荐
- iOS 开发之 SDWebImage 底层实现原理分析
SDWebImage 是一个比较流行的用于网络图片缓存的第三方类库.这个类库提供了一个支持缓存的图片下载器.为了方便操作者调用,它提供了很多 UI 组件的类别,例如:UIImageView.UIBut ...
- 3_6 环状序列(UVa1584)
长度为n的环状串有n种表示法,分别为某个位置开始顺时针得到.例如,图中的环状串有10种表示: CGAGTCAGCT,GAGTCAGCTC,AGTCAGCTCG等.在这些表示法中,字典序最小的称为“最小 ...
- 安卓开发:用ImageView放上图片后上下有间隙
想不到在我使用第一个UI控件ImageView时候就遇上了问题,简单使用ImageView如下: <ImageView android:layout_width="match_pare ...
- leetcode网解题心得——61. 旋转链表
目录 leetcode网解题心得--61. 旋转链表 1.题目描述 2.算法分析: 3.用自然语言描述该算法 4.java语言实现 5.C语言实现 leetcode网解题心得--61. 旋转链表 1. ...
- Python中的代码块及其缓存机制、深浅copy
一.代码块及其缓存机制 代码块 一个模块.一个函数.一个类.一个文件等都是一个代码块:交互式命令下,一行就是一个代码块. 同一个代码块内的缓存机制(字符串驻留机制) 机制内容:Python在执行同一个 ...
- Educational Codeforces Round 73 (Rated for Div. 2)F(线段树,扫描线)
这道题里线段树用来区间更新(每次给更大的区间加上当前区间的权重),用log的复杂度加快了更新速度,也用了区间查询(查询当前区间向右直至最右中以当前区间端点向右一段区间的和中最大的那一段的和),也用lo ...
- PLSQL报错: ORA-12170:TNS connect timeout occurred
本人的问题已解决,先在安装oracle的服务器上黑窗口输入tnsping,提示说no listener,这是监听服务没有打开. 打开服务后还是不行,最后原因是服务器的网络有防火墙的问题,关掉防火墙连接 ...
- 「NOI2006」最大获利
「NOI2006」最大获利 传送门 最小割. 对于每一组用户群 \(A_i, B_i, C_i\) ,连边 $S \to A_i, S \to B_i, $ 容量为成本,还有 \(i \to T\) ...
- java判断文件或文件夹是否在
public static void main(String[] args) { File file = new File("G:\\Jeff.txt"); File dir = ...
- Python 之并发编程之manager与进程池pool
一.manager 常用的数据类型:dict list 能够实现进程之间的数据共享 进程之间如果同时修改一个数据,会导致数据冲突,因为并发的特征,导致数据更新不同步. def work(dic, lo ...