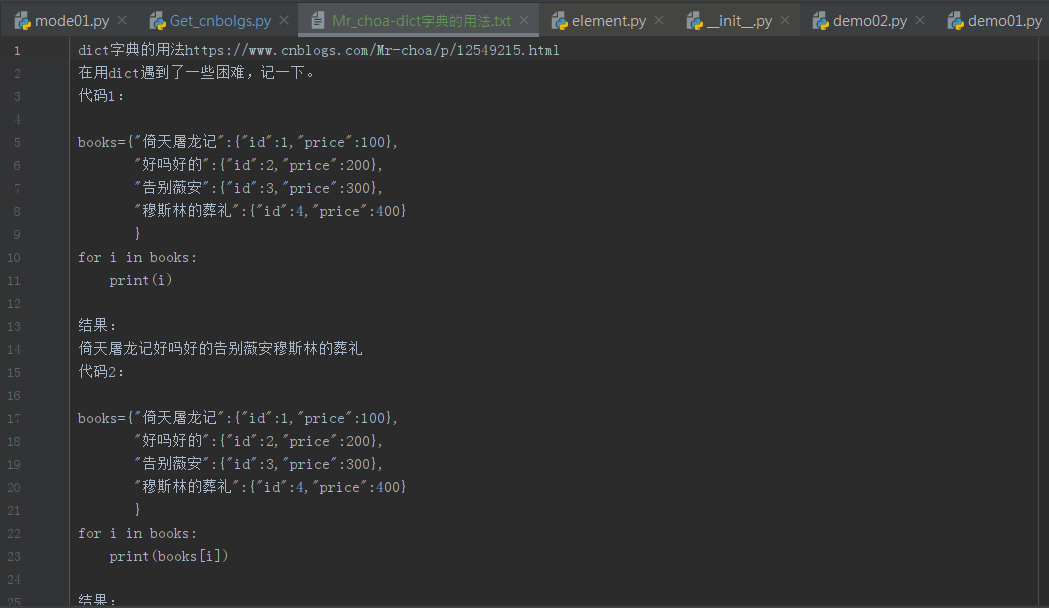
python:爬取博主的所有文章的链接、标题和内容
以爬取我自己的博客为例:https://www.cnblogs.com/Mr-choa/
1、获取所有的文章的链接:

博客文章总共占两页,比如打开第一页:https://www.cnblogs.com/Mr-choa/default.html?page=1的HTML源文件

每篇博客文章的链接都在a标签下,并且具有class属性为"postTitle2",其href属性就指向这篇博文的地址
<a class="postTitle2" href="https://www.cnblogs.com/Mr-choa/p/12615986.html">
简单爬取自己的一篇博客文章
</a>
这样我们可以通过正则表达式获取博文的地址,获取所有的文章的链接就要对博客的页数做一个遍历:
模块代码实现:
# 获取所有的链接
def get_Urls(url,pageNo):
"""
根据url,pageNo,能够返回该博主所有的文章url列表
:param url:
:param pageNo:
:return:
"""
# 创建一个list,用来装博客文章的地址
total_urls=[]
# 对页数做个遍历
for i in range(1,pageNo+1):
# 页数的地址
url_1=url+str(i)
# 获取这一页的全部源代码
html=get_html(url_1)
# 创建一个属性
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
# 通过正则表达式找到所有相关属性的数据,就是所有的博客文章的链接
urls=re.findall(title_pattern,html)
# 把链接放到list容器内
for url_ in urls:
total_urls.append(url_)
#print(total_urls.__len__())
# 返回所有博客文章的链接
return total_urls
2、获取全部源代码
代码实现:
# 获取网页源码
def get_html(url):
"""
返回对应url的网页源码,经过解码的内容
:param url:
:return:
"""
# 创建一个请求对象
req = urllib.request.Request(url)
# 发起请求,urlopen返回的是一个HTTPResponse对象
resp = urllib.request.urlopen(req)
# 获取HTTP源代码,编码格式为utf-8
html_page = resp.read().decode('utf-8')
# 返回网页源码
return html_page
或者用requests库实现:
def get_html(url):
# 创建一个响应对象
response=requests.get(url)
# 获取整个网页的HTML内容
html_page=response.text
# 返回网页的HTML内容
return html_page
3、获取博客文章的标题
代码实现:
# 获取博客文章的标题
def get_title(url):
'''
获取对应url下文章的标题
:param url:
:return:
'''
# 通过博文的地址获取到源代码
html_page = get_html(url)
# 创建str变量
title_pattern = r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)'
# 匹配到相关的数据
title_match = re.search(title_pattern, html_page)
# 获取标题
title = title_match.group(2)
# 返回标题
return title
4、获取博客文章的所有文本
代码实现:
# 获取博客文章的文本
def get_Body(url):
"""
获取对应url的文章的正文内容
:param url:
:return:
"""
html_page = get_html(url)
soup = BeautifulSoup(html_page, 'html.parser')
div = soup.find(id="cnblogs_post_body")
return div.text
5、保存文章
代码实现:
# 保存文章
def save_file(url):
"""
根据url,将文章保存到本地
:param url:
:return:
"""
title=get_title(url)
body=get_Body(url)
filename="Mr_choa"+'-'+title+'.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write(title)
f.write(url)
f.write(body)
# 遍历所有的博客文章链接,保存博客的文章
def save_files(url,pageNo):
'''
根据url和pageNo,保存博主所有的文章
:param url:
:param pageNo:
:return:
'''
totol_urls=get_Urls(url,pageNo)
for url_ in totol_urls:
save_file(url_)
显示所有的代码:
import requests
import urllib.request
import re
from bs4 import BeautifulSoup
#该作者的博文一共有多少页
pageNo=2
#后面需要添加页码
url='https://www.cnblogs.com/Mr-choa/default.html?page='
# 获取网页源码
def get_html(url):
"""
返回对应url的网页源码,经过解码的内容
:param url:
:return:
"""
# 创建一个请求对象
req = urllib.request.Request(url)
# 发起请求,urlopen返回的是一个HTTPResponse对象
resp = urllib.request.urlopen(req)
# 获取HTTP源代码,编码格式为utf-8
html_page = resp.read().decode('utf-8')
# 返回网页源码
return html_page '''# 获取网页源代码
def get_html(url):
# 创建一个响应对象
response=requests.get(url)
# 获取整个网页的HTML内容
html_page=response.text
# 返回网页的HTML内容
return html_page
''' # 获取博客文章的标题
def get_title(url):
'''
获取对应url下文章的标题
:param url:
:return:
'''
# 通过博文的地址获取到源代码
html_page = get_html(url)
# 创建str变量
title_pattern = r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)'
# 匹配到相关的数据
title_match = re.search(title_pattern, html_page)
# 获取标题
title = title_match.group(2)
# 返回标题
return title
# 获取博客文章的文本
def get_Body(url):
"""
获取对应url的文章的正文内容
:param url:
:return:
"""
# 通过博客文章的链接,获取博客文章的源代码
html_page = get_html(url)
# 创建对象,基于bs4库HTML的格式输出
soup = BeautifulSoup(html_page, 'html.parser')
# 定义一个soup进行find()方法处理的标签
div = soup.find(id="cnblogs_post_body")
# 返回博客文章内容
return div.text
# 保存文章
def save_file(url):
"""
根据url,将文章保存到本地
:param url:
:return:
"""
title=get_title(url)
body=get_Body(url)
filename="Mr_choa"+'-'+title+'.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write(title)
f.write(url)
f.write(body)
# 遍历所有的博客文章链接,保存博客的文章
def save_files(url,pageNo):
'''
根据url和pageNo,保存博主所有的文章
:param url:
:param pageNo:
:return:
'''
totol_urls=get_Urls(url,pageNo)
for url_ in totol_urls:
save_file(url_)
# 获取所有的链接
def get_Urls(url,pageNo):
"""
根据url,pageNo,能够返回该博主所有的文章url列表
:param url:
:param pageNo:
:return:
"""
# 创建一个list,用来装博客文章的地址
total_urls=[]
# 对页数做个遍历
for i in range(1,pageNo+1):
# 页数的地址
url_1=url+str(i)
# 获取这一页的全部源代码
html=get_html(url_1)
# 创建一个属性
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
# 通过正则表达式找到所有相关属性的数据,就是所有的博客文章的链接
urls=re.findall(title_pattern,html)
# 把链接放到list容器内
for url_ in urls:
total_urls.append(url_)
#print(total_urls.__len__())
# 返回所有博客文章的链接
return total_urls
save_files(url,pageNo)
效果:

打开.txt:
参考博客:https://www.cnblogs.com/xingzhui/p/7845675.html
python:爬取博主的所有文章的链接、标题和内容的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- 爬取博主的所有文章并保存为PDF文件
继续改进上一个项目,上次我们爬取了所有文章,但是保存为TXT文件,查看不方便,而且还无法保存文章中的代码和图片. 所以这次保存为PDF文件,方便查看. 需要的工具: 1.wkhtmltopdf安装包, ...
- 爬取博主所有文章并保存到本地(.txt版)--python3.6
闲话: 一位前辈告诉我大学期间要好好维护自己的博客,在博客园发布很好,但是自己最好也保留一个备份. 正好最近在学习python,刚刚从py2转到py3,还有点不是很习惯,正想着多练习,于是萌生了这个想 ...
- python: 爬取[博海拾贝]图片脚本
练手代码,聊作备忘: # encoding: utf-8 # from __future__ import unicode_literals import urllib import urllib2 ...
- python抓取伯乐在线的全部文章,对标题分词后存入mongodb中
依赖包: 1.pymongo 2.jieba # -*- coding: utf-8 -*- """ @author: jiangfuqiang "" ...
- python爬取凤凰网站的新闻,及其链接地址,来源,时间和内容,用selenium自动化和requests处理数据
有写规则需要自己定义判断. import requests from selenium import webdriver import time def grasp(urlT): driver = w ...
- python 爬取文章
这里我们利用强大的python爬虫来爬取一篇文章.仅仅做一个示范,更高级的用法还要大家自己实践. 好了,这里就不啰嗦了,找到一篇文章的url地址:http://www.duanwenxue.com/a ...
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 爬虫---lxml爬取博客文章
上一篇大概写了下lxml的用法,今天我们通过案例来实践,爬取我的博客博客并保存在本地 爬取博客园博客 爬取思路: 1.首先找到需要爬取的博客园地址 2.解析博客园地址 # coding:utf-8 i ...
随机推荐
- String字符串位置移动
有规律的String字符串位置移动 1.自定义一个有规律的String字符串 String numstr = "1,2,3,x,y,4,5"; 2.按逗号拆分numstr字符串 S ...
- vue的插件使用
插件通常是为Vue添加全局功能,vue的官网介绍了5中添加插件的方法. vue的插件有个公开方法install.第一个参数是Vue构造器,第二个参数是一个可选的选项对象. 在plugin.js中可以这 ...
- Python进阶练习与爬取豆瓣T250的影片相关信息
(一)Python进阶练习 正所谓要将知识进行实践,才会真正的掌握 于是就练习了几道题:求素数,求奇数,求九九乘法表,字符串练习 import re #求素数 i=1; flag=0 while(i& ...
- JetBrains 第二轮:再为免费全家桶续命三个月
昨天分享了如何通过参与JetBrains的解密任务来获取正版全家桶的兑换码.今天 JetBrains 一早继续在Twitter推出第二波任务: 下面,我们就继续来一起参与一下,为我们的正版JetBra ...
- 【图文+视频新手也友好】Java一维数组详细讲解(内含练习题答案+详解彩蛋喔~)
目录 视频讲解: 一.数组的概述 二.一维数组的使用 三.Arrays工具类中的sort方法(sort方法用的多,我们具体讲一下) 四.数组中的常见异常 五.一维数组练习题 六.彩蛋(本期视频使用的P ...
- flink RPC(akka)
flink中的rpc框架使用的akka.在本节并不详细讲述akka,而是就flink中rpc来讲述akka的部分内容.本节,我从AkkaRpcActor.handleRpcInvocation方法讲起 ...
- XSS(跨站脚本攻击)详解
跨站脚本攻击XSS(Cross Site Scripting),为了不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS.恶意攻击者往Web ...
- JAVA 转换 树结构数据
JAVA 转换 树结构数据 第一步:引入fastjson <dependency> <groupId>com.alibaba</groupId> <artif ...
- Abp 抛出详细异常
Abp在默认情况下,只要后端抛出异常,一概过滤为服务器错误并弹出,这样并不方便调试,这个时候需要开启一个开关即可: 在模块预初始化PreInitialize中开启,代码如下: , 这样就可以看到详细的 ...
- Fast and accurate bacterial species identification in urine specimens using LC-MS/MS mass spectrometry and machine learning (解读人:闫克强)
文献名:Fast and accurate bacterial species identification in urine specimens using LC-MS/MS mass spectr ...