mysql group by分组查询
分组的SQL语句有2个:
group by 和分组聚合函数实现 partition by (oracle和postgreSQL中的语句)功能
group by + having 组合赛选数据
注意:having 条件的字段必须在前面查询赛选存在,否则语法错误
错误格式:
SELECT MAX(ID),U_ID FROM mlzm_comments GROUP BY U_ID HAVING Data_Status >
正确格式:
SELECT MAX(ID),U_ID,Data_Status FROM mlzm_comments GROUP BY U_ID HAVING Data_Status >
group by强调的是一个整体,就是组,只能显示一个组里满足聚合函数的一条记录, partition by 在整体后更强调个体,能显示组里所有个体的记录。
#实际需求,获取满足条件第一条信息或最后一条信息
步骤拆解:
#步骤一:找出所有符合第一条件条件的数据,默认排序是按主键索引升序排列,这里按u_id 字段排序方便审阅
SELECT
a.ID,a.U_ID
FROM
mlzm_content a
WHERE
a.Data_Status =
ORDER BY a.U_ID,a.ID ASC;
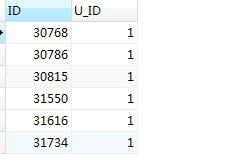
#步骤2:利用group by 和max()、min()函数,对符合第一条件的数据进行分组,并获取当前分组中最小和最大的,注意当前结果集中的id字段不一定是最小的,若想要最小或最大id,需要对表a先进行排序处理
#未对表a 进行排序
SELECT
b.ID,b.U_ID,MIN(b.ID),MAX(b.ID)
FROM
(
SELECT
a.ID,a.U_ID
FROM
mlzm_content a
WHERE
a.Data_Status =
) AS b
GROUP BY b.U_ID;
上面的语句等效于
#优化处理,但这样的数据无法保证a.ID 排序的有效性
SELECT
a.ID,a.U_ID,MIN(a.ID),MAX(a.ID)
FROM
mlzm_content a
WHERE
a.Data_Status =
GROUP BY a.U_ID;
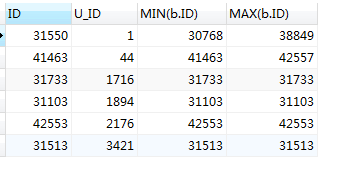
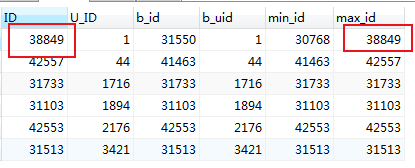
在这可以明确看出,所得的结果集中,当前的id 并非最小的也非最大的(如第1条显示的,当前id 为 31550 而最小的是 30768 最大的为38849),因此这种情况id字段不能作为后面的赛选条件
接下来用未排序的ID 字段作为依据查找的数据也并想要的
#以未排序的id字段作为参考依据,结果并非想要的
SELECT
c.ID,c.U_ID,b.ID as b_id,b.U_ID as b_uid ,b.min_id,b.max_id
FROM
mlzm_content AS c
INNER JOIN (
SELECT
a.ID,
a.U_ID,
MIN(a.ID) as min_id,
MAX(a.ID) as max_id
FROM
mlzm_content as a
WHERE a.Data_Status=
GROUP BY
a.U_ID
ORDER BY a.U_ID
) AS b ON c.ID =b.ID
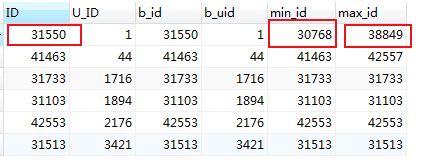
这种情况想要得到最小/最大的的一条信息,需要以min_id /max_id作为参考依据
#从未排序结果集中获取最小的一条信息
SELECT
c.ID,c.U_ID,b.ID as b_id,b.U_ID as b_uid ,b.min_id,b.max_id
FROM
mlzm_content AS c
INNER JOIN (
SELECT
a.ID,
a.U_ID,
MIN(a.ID) as min_id,
MAX(a.ID) as max_id
FROM
mlzm_content as a
WHERE a.Data_Status=
GROUP BY
a.U_ID
ORDER BY a.U_ID
) AS b ON c.ID =b.min_id
#从未排序结果集中获取最大的一条信息
SELECT
c.ID,c.U_ID,b.ID as b_id,b.U_ID as b_uid ,b.min_id,b.max_id
FROM
mlzm_content AS c
INNER JOIN (
SELECT
a.ID,
a.U_ID,
MIN(a.ID) as min_id,
MAX(a.ID) as max_id
FROM
mlzm_content as a
WHERE a.Data_Status=
GROUP BY
a.U_ID
ORDER BY a.U_ID
) AS b ON c.ID =b.max_id
最小的一条结果
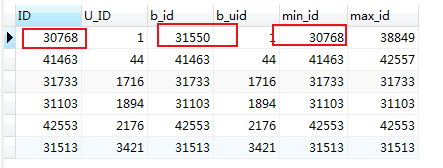
耗时:0.0310 秒
最大的一条结果
先排序后再获取数据
#对表a 进行先排序处理
SELECT
b.ID,b.U_ID,MIN(b.ID),MAX(b.ID)
FROM
(
SELECT
a.ID,a.U_ID
FROM
mlzm_content a
WHERE
a.Data_Status =
ORDER BY a.ID ASC
) AS b
GROUP BY b.U_ID;
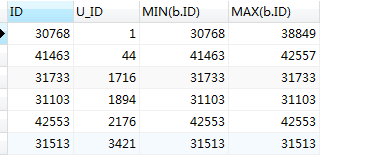
先进行排序后可以看出当前的id 和min(b.id)一致,现在可用id字段作为赛选条件
接下来用排序后得到的id 和min_id 来进行获取分组中最小的一条信息
#用排序后得到的id作为判断依据
SELECT
d.ID,
d.U_ID,
c.ID AS c_id,
c.U_ID AS c_uid,
c.min_id,
c.max_id
FROM
mlzm_content AS d
INNER JOIN (
SELECT
b.ID,
b.U_ID,
MIN(b.ID) AS min_id,
MAX(b.ID) AS max_id
FROM
(
SELECT
a.ID,
a.U_ID
FROM
mlzm_content a
WHERE
a.Data_Status =
ORDER BY
a.ID ASC
) AS b
GROUP BY
b.U_ID
) AS c ON d.ID = c.ID #用min_id 作为依据
SELECT
d.ID,
d.U_ID,
c.ID AS c_id,
c.U_ID AS c_uid,
c.min_id,
c.max_id
FROM
mlzm_content AS d
INNER JOIN (
SELECT
b.ID,
b.U_ID,
MIN(b.ID) AS min_id,
MAX(b.ID) AS max_id
FROM
(
SELECT
a.ID,
a.U_ID
FROM
mlzm_content a
WHERE
a.Data_Status =
ORDER BY
a.ID ASC
) AS b
GROUP BY
b.U_ID
) AS c ON d.ID = c.min_id
得到的结果集相同,因此先排序处理后id是可作为判断依据的否则只能用min_id作为判断依据
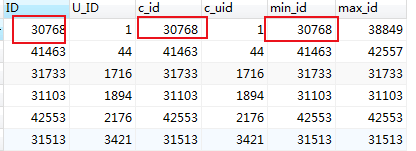
耗时:0.0410 秒
结论:先进行排序处理,关键字段可做判断依据,否则需要用获取的max(column_name)或min(column_name)作为判断依据。
但先进行排序会比不排序耗费的时间多,因此排序直接使用max(column_name)或min(column_name)作为判断依据处理要高效点。
错误的筛选方式:
#该方式判断是错误的,因为 结果集b中并未进行条件赛选,因此的到的结果中的min_id 对应的数据可能并不满足Data_Status=2的条件,最后做判断的时候这些数据会被排除掉。
SELECT
c.ID,c.U_ID,b.ID as b_id,b.U_ID as b_uid ,b.min_id,b.max_id
FROM
mlzm_content AS c
INNER JOIN (
SELECT
a.ID,
a.U_ID,
MIN(a.ID) as min_id,
MAX(a.ID) as max_id
FROM
mlzm_content as a
GROUP BY
a.U_ID
) AS b ON c.ID =b.min_id WHERE c.Data_Status=
这是错误的判断方式,谨记啊
这样得到的结果集要少于真实的数据集。
除了(INNER) JOIN 外也可通过 in 和 exists 来获取
#用in 方式
SELECT
c.ID,c.U_ID
FROM
mlzm_content AS c
WHERE
c.ID in
(
SELECT
MIN(a.ID) as min_id
FROM
mlzm_content as a
WHERE a.Data_Status=
GROUP BY
a.U_ID
)
ORDER BY U_ID
耗时:0.0410 秒
#用exists 方式获取
SELECT
c.ID,c.U_ID
FROM
mlzm_content AS c
WHERE
exists
(
SELECT * from (
SELECT
MIN(a.ID) as min_id
FROM
mlzm_content as a
WHERE a.Data_Status=
GROUP BY
a.U_ID
) as b where b.min_id = c.ID
)
ORDER BY U_ID
耗时:0.0520 秒
小结:
in 和 exists 执行效率收 子表大小的影响,子表小in的效率高,反之,若子表大则exists的效率高。
in和exists效率比 join 低,因为只有1个字段判断,特别是在数据量大的时候差距更大,10万数据+的话 join 和 in至少差距在5分钟以上,因此最佳方式是使用INNER JOIN 连表查询。
//=====================================================================================================//
获取满足条件的最小一条数据或最大一条数据,sql优化后:
最小:
SELECT
c.*
FROM
mlzm_content AS c
INNER JOIN (
SELECT
MIN(a.id) as min_id
FROM a
WHERE a.status= (条件判断)
GROUP BY a.U_ID (分组依据)
) AS b ON c.id =b.min_id
where (其他条件)
最大:
SELECT
c.*
FROM
mlzm_content AS c
INNER JOIN (
SELECT
max(a.id) as max_id
FROM a
WHERE a.status= (条件判断)
GROUP BY a.U_ID (分组依据)
) AS b ON c.id =b.max_id
where (其他条件)
//=====================================================================================================//
上面利用group by分组方式 只能获取到最大或最小的,那么若是想要获取到指定位置的条数呢?如,获取满足条件的第5 条信息。
mysql中是不存在聚合函数 partition by的 ,要想实现类似功能需要利用 group_concat + substr等函数处理
partition by 语法
select .... over( partition by column1 order by column2) from table_name ...
函数:
concat(str1, str2,...)
功能:将多个字符串连接成一个字符串
结果:返回的结果为参数相连接产生的字符串,注意,若其中任意参数为null,则返回的结果也为null
concat('str1','、 ','str2','、','str3') 对应的结果为:str1、str2、str3,但这样每次都要填写分隔符,看起来很是臃肿,那有没有简单的实现方式呢?
有那就是concat_ws(separator, str1, str2, ...)函数(concat_ws就是concat with separator),功能与concat类似将多个字符串连接成一个字符串,但是可以一次性指定分隔符。
上面的代码可简化为concat_ws('、','str1', 'str2', 'str3')
注意:concat()和concat_ws()一样,只要传入的参数有null 则返回结果均为null,分隔符为null也是一样的。
group_concat(expr[表达式])聚合函数 ,
前言:在有group by的查询语句中,select指定的字段要么就包含在group by语句的后面,作为分组的依据,要么就包含在聚合函数中。(有关group by的知识:浅析SQL中Group By的使用)。
group_concat()函数
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
SELECT
GROUP_CONCAT(a.ID)as ids,a.U_ID
FROM
mlzm_content AS a
WHERE
a.Data_Status =
GROUP BY
a.U_ID
ORDER BY a.U_ID
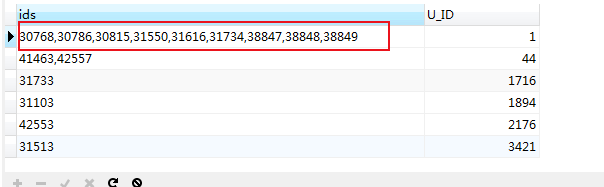
将id倒序连接
# 以'# #' 来分割连接
SELECT
GROUP_CONCAT(DISTINCT a.ID ORDER BY a.id DESC separator '# #')as ids,a.U_ID
FROM
mlzm_content AS a
WHERE
a.Data_Status =
GROUP BY
a.U_ID
ORDER BY a.U_ID
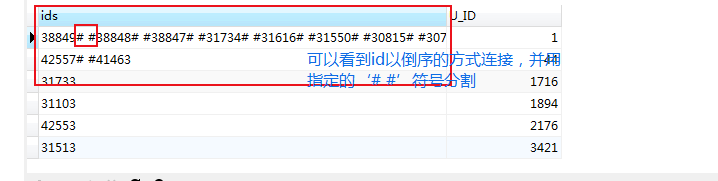
接下来用substring_index(“待截取有用部分的字符串”,“截取数据依据的字符(分隔符)”,截取字符的位置N)函数来截取想要的数据
如:获取满足条件的前5 条信息
SELECT
substring_index(GROUP_CONCAT(DISTINCT a.ID ORDER BY a.id ASC separator ','),',',) as sub_id,
a.U_ID
FROM
mlzm_content AS a
WHERE
a.Data_Status =
GROUP BY
a.U_ID
ORDER BY a.U_ID
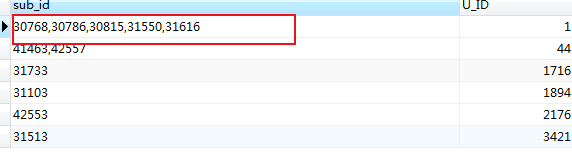
错误的获取(in):
SELECT c.id,c.U_ID FROM mlzm_content as c
JOIN
(SELECT
substring_index(GROUP_CONCAT(DISTINCT a.ID ORDER BY a.id ASC separator ','),',',) as sub_id,
a.u_id
FROM
mlzm_content AS a
WHERE
a.Data_Status =
GROUP BY
a.U_ID
) as t
ON c.u_id = t.u_id
WHERE c.id in (t.sub_id)
ORDER BY c.u_id
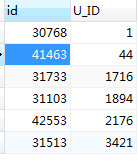
可以看出in操作只匹配了第一个元素。若想要用in 操作的话可把子查询的结果集提出来再当做参数传入,如用PHP 中拆成2步来进行,先通过substring_index()函数把满足条件的数据先筛选出来,再通过结果集去循环查询匹配的数据,但是这样效率低,占用资源多,(因此舍弃这种操作)
正确的获取(find_in_set):
SELECT c.id,c.u_id FROM mlzm_content as c
JOIN
(SELECT
substring_index(GROUP_CONCAT(DISTINCT a.ID ORDER BY a.id ASC separator ','),',',) as sub_id,
a.u_id
FROM
mlzm_content AS a
WHERE
a.Data_Status =
GROUP BY
a.U_ID
) as t
ON c.u_id = t.u_id
WHERE FIND_IN_SET(c.id,t.sub_id)
ORDER BY c.u_id
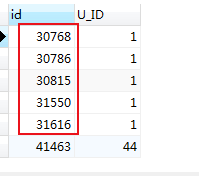
若是想得到前5条信息中最后一条信息
SELECT c.id,c.U_ID FROM mlzm_content as c
JOIN
(SELECT
substring_index(substring_index(GROUP_CONCAT(DISTINCT a.ID ORDER BY a.id ASC separator ','),',',),',',-) as sub_id,
a.U_ID
FROM
mlzm_content AS a
WHERE
a.Data_Status =
GROUP BY
a.U_ID
) as t
ON c.id = t.sub_id
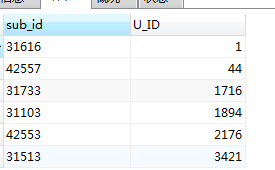
利用这个方案, 以下类似业务需求都可以这么做, 如:
1. 查找每个用户过去10个的登陆IP
2. 查找每个班级中总分最高的两个人
greatest(value1,value2,...)函数,获取传入参数中最大的值
SELECT greatest(,,,)
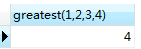
SELECT greatest('a','b','c','bb','ae','d')
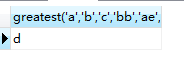
SELECT greatest('a','b','c','bb','ae','d'),ASCII('a'),ASCII('b'),ASCII('c'),ASCII('bb'),ASCII('ae'),ASCII('d')

从上面可以看出,greatest()函数在字符比较的时候,只取第一个字符进行ASCII 值比较
参考:https://blog.csdn.net/mary19920410/article/details/76545053/
in 与exists性能区分:https://www.cnblogs.com/beijingstruggle/p/5885137.html
mysql 函数参考:https://www.cnblogs.com/zwesy/p/9428509.html
mysql group by分组查询的更多相关文章
- mysql group by分组查询后 查询个数
mysql group by分组查询后 查询个数2个方法随便你选 <pre>select count(distinct colA) from table1;</pre>< ...
- mysql group by分组查询错误修改
select @@global.sql_mode;set @@sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR ...
- 【mybatis】【mysql】mybatis查询mysql,group by分组查询报错:Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column
mybatis查询mysql,group by分组查询报错:Expression #1 of SELECT list is not in GROUP BY clause and contains no ...
- Mysql按时间段分组查询
Mysql按时间段分组查询来统计会员的个数,mysql个数 Mysql按时间段分组查询来统计会员的个数,mysql个数 1.使用case when方法(不建议使用)- 代码如下 复制代码SELECT ...
- Mysql:实现分组查询拼接未分组同一字段字符group_concat()
Mysql:实现分组查询拼接未分组同一字段字符group_concat() MySQL中,如果想实现将分组之后的多个数据合并到一列,可以使用group_concat函数,如下图所示: 在oralce中 ...
- ysql常用sql语句(12)- group by 分组查询
测试必备的Mysql常用sql语句,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1683347.html 前言 ...
- mysql按照时间分组查询
mysql 按年.月.周.日分组查询 1.按照年份分组查询 SELECT DATE_FORMAT(t.bill_time,'%Y') month_time,sum(t.pay_price) total ...
- SQL group by分组查询(转)
本文导读:在实际SQL应用中,经常需要进行分组聚合,即将查询对象按一定条件分组,然后对每一个组进行聚合分析.创建分组是通过GROUP BY子句实现的.与WHERE子句不同,GROUP BY子句用于归纳 ...
- Group by 分组查询 实战
实战经历,由于本人在共享单车上班,我们的单车管理模块,可以根据单车号查询单车,但是单车号没有设置unique(独一无二约束),说以这就增加了单车号可能重复的风险,但是一般情况下,单车号是不会重复的,因 ...
随机推荐
- pycharm如何显示工具栏
1.没有工具栏的效果图如下: 2.在view中找到Toolbar打上勾即可显示: 3.工具栏设置成功显示效果图如下: 3.如何显示一个类或方法所在的文件,以及该文件下的所有方法,可以快速定位到该行
- 在使用Reference Source调试.Net 源代码时如何取消optimizations(代码优化)-翻译
在使用PDB调试XAF时,发现好多变量都看不到.都被优化掉了. 下面的方法可以解决. 当你在使用Reference Source functionality in VS 2008 调试.Net 的源代 ...
- Direct2D处理几何图形之间的碰撞检测(上)
转载请注明出处:http://www.cnblogs.com/Ray1024 一.概述 Direct2D中支持以下几种类型的几何图形: a.简单几何图形(Simple Geometry):矩形.圆角矩 ...
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- KClient——kafka消息中间件源码解读
目录 kclient消息中间件 kclient-processor top.ninwoo.kclient.app.KClientApplication top.ninwoo.kclient.app.K ...
- day12生成器
迭代器 __iter__() 获取迭代器 __next__() 下一个 生成器 本质就是迭代器 两种方式写生成器 1. 生成器函数 2. 生成器表达式 生成器函数 函数内部有yield. yield返 ...
- P4562 [JXOI2018]游戏
题面 题目描述 她长大以后创业了,开了一个公司. 但是管理公司是一个很累人的活,员工们经常背着可怜偷懒,可怜需要时不时对办公室进行检查. 可怜公司有 \(n\) 个办公室,办公室编号是 \(l\) 到 ...
- 机器学习算法 --- Decision Trees Algorithms
一.Decision Trees Agorithms的简介 决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习 ...
- Linux系统下安装jdk1.8
JDK安装分为两种方式 一种是解压tar.gz配置安装, 一种是rpm安装,我这里是tar.gz安装方式 一.首先在oracle官方网下载jdk,网址如下:http://www.oracle.com ...
- HDFS handler
http://docs.oracle.com/goldengate/bd1221/gg-bd/GADBD/GUID-85A82B2E-CD51-463A-8674-3D686C3C0EC0.htm#G ...