sklearn交叉验证2-【老鱼学sklearn】
过拟合
过拟合相当于一个人只会读书,却不知如何利用知识进行变通。
相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨。
从图形上看,类似下图的最右图:
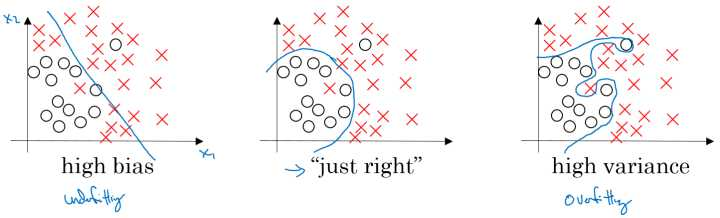
从数学公式上来看,这个曲线应该是阶数太高的函数,因为一般任意的曲线都能由高阶函数来拟合,它拟合得太好了,因此丧失了泛化的能力。
用Learning curve 检视过拟合
首先加载digits数据集,其包含的是手写体的数字,从0到9:
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
然后用SVC(支持向量机)对手写体数字进行分类,当然,这里要介绍的核心函数是learning_curve,先上代码看看:
# 导入支持向量机
from sklearn.svm import SVC
model = SVC(gamma=0.001)
train_sizes, train_loss, test_loss = learning_curve(model, X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
# 平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
在learning_curve中设置了十一法的数据,同时在打分时使用了neg_mean_squared_error方式,也就是方差值,因此这个最后的得分值是负数;train_sizes指定了5轮检视学习曲线(10%, 25%, 50%, 75%, 100%):
最后,我们把根据每轮的训练集大小对于最终得分的影响程度画个图,相当于做题数量的多少跟最终考试成绩的关系图:
# 可视化图形
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_loss_mean, label="Train")
plt.plot(train_sizes, test_loss_mean, label="Test")
plt.legend()
plt.show()
显示图形为:
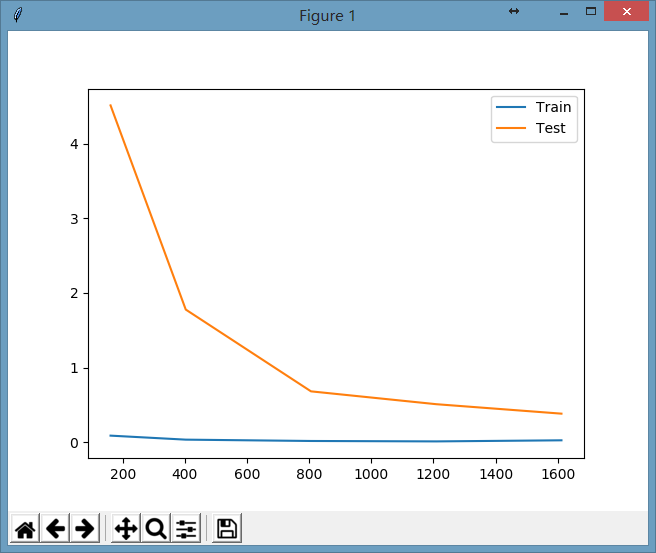
看起来随着做题数量的增加,考试成绩越来越好了(损失函数的值越来越小了),并且考试成绩在慢慢逼近平常的训练成绩。
完整的代码如下:
from sklearn.datasets import load_digits
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
# 加载学习曲线模块
from sklearn.model_selection import learning_curve
import numpy as np
# 导入支持向量机
from sklearn.svm import SVC
model = SVC(gamma=0.001)
train_sizes, train_loss, test_loss = learning_curve(model, X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
# 平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 可视化图形
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_loss_mean, label="Train")
plt.plot(train_sizes, test_loss_mean, label="Test")
plt.legend()
plt.show()
如果我们把上面代码中SVC参数的gamma值设置为0.1,显示出的图形为:
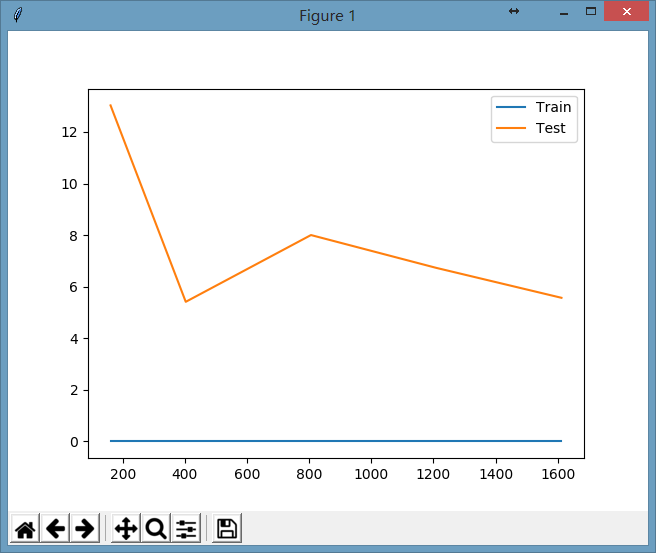
在上面的图形中,我们会发现再增加训练集的数据并没有使测试集的损失值下降,相当于一个人按照他的学习方式做训练题已经够多了,你做更多的训练题都无法提高你的考试成绩了,这时可能需要考虑的是稍微改变一下你的学习方法说不定就能提高考试成绩呢。
这也说明了,在某些情况下题海战术不一定奏效了。
在机器学习中表示为所学到的模型可能太复杂了,产生了过拟合(过拟合表现为训练集的损失函数在下降,但测试集的损失函数不降反升),不具备泛化能力,例如下图中绿色曲线就是一个过拟合的表现:
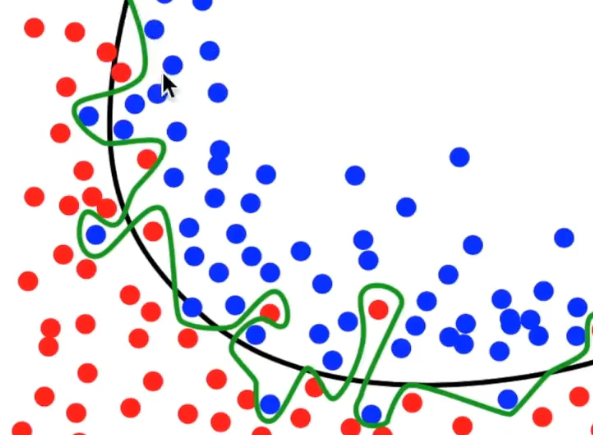
相应的损失函数曲线显示如下所示:
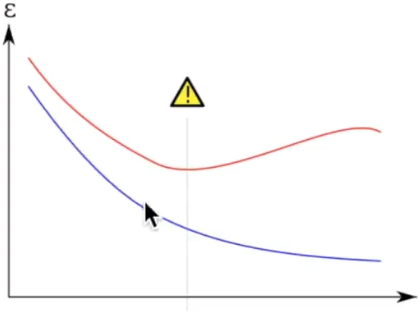
因此如果我们想要查看是否有过拟合,可以通过learning_curve函数来进行并以可视化的方式来查看结果。
sklearn交叉验证2-【老鱼学sklearn】的更多相关文章
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了. 本次我们来看下如何调整学习中的参数,类似一个 ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5. 标准化就是要把这两种参 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
随机推荐
- error: #error This file requires compiler and library support for the ISO C++ 2011 standard. This support is currently experimental, and must be enabled with the -std=c++11 or -std=gnu++11 compiler op
caffe c++11编译问题 问题:error: #error This file requires compiler and library support for the ISO C++ 201 ...
- [模板] 二分图博弈 && BZOJ2463:[中山市选2009]谁能赢呢?
二分图博弈 from BZOJ 1443 游戏(二分图博弈) - free-loop - 博客园 定义 1.博弈者人数为两人,双方轮流进行决策. 2.博弈状态(对应点)可分为两类(状态空间可分为两个集 ...
- 11.2 Flask 配置文件,路由系统
配置文件系统 构建 Flask 应用时指定 app = Flask( __name__, template_folder = '', # 指定存储模板文件夹名称 static_url_path = ' ...
- JMeter5.1开发TCP协议接口脚本
最简单的方法,就是找开发给报文,直接复制到tcp取样器中,将需要变化的值做参数化就可以了.(xml报文要去掉回车换行) 下面是一个通讯头定义 通讯头56个字节(1个字符一个字节) 3 + 9 + 9 ...
- 洛谷 P3380 【【模板】二逼平衡树(树套树)】
其实比想象中的好理解啊 所谓树套树,就是在一棵树的基础上,每一个节点再维护一棵树 说白了,就是为了实现自己想要的操作和优秀的时间复杂度,来人为的增加一些毒瘤数据结构来维护一些什么东西 比如说这道题 如 ...
- Django模板
Django模板系统 官方文档 常用语法 只需要记住两种特殊符号: {{ }}和 {% %} 变量相关的用{{}},逻辑相关的用{%%}. 变量 { 变量名 }} 变量名由字母数字和下划线组成. 点 ...
- plink合并文件并更新SNP位置(merge file, update SNP position)
一.合并文件 plink合并文件需要用到“merge”参数 如果是ped和map格式文件,则用以下命令: plink --file data1 --merge data2.ped data2.map ...
- 百度在职 iOS 架构师的成长笔记,送给还在迷茫的你!
前言 我们经常在网上会看到这样的文章,你的同龄人正在如何如何.......这是典型的贩卖焦虑的文章.的确,现阶段,刚毕业几年的年轻人,面临车,房子等,有时候压力挺大的. 但你过度焦虑的话,每天生活在恐 ...
- Numpy系列(二)- 数据类型
Numpy 中的数组比 Python 原生中的数组(只支持整数类型与浮点类型)强大的一点就是它支持更多的数据类型. 基本数据类型 numpy常见的数据类型 数据类型 描述 bool_ 布尔(True或 ...
- Numpy 系列(十一)- genfromtxt函数
定义输入 genfromtxt的唯一强制参数是数据的源.它可以是字符串,字符串列表或生成器.如果提供了单个字符串,则假定它是本地或远程文件或具有read方法的打开的类文件对象的名称,例如文件或Stri ...