GBDT算法原理及Python实现
一、概述
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)是集成学习中提升(Boosting)方法的典型代表。它以决策树(通常是 CART 树,即分类回归树)作为弱学习器,通过迭代的方式,不断拟合残差(回归任务)或负梯度(分类任务),逐步构建一系列决策树,最终将这些树的预测结果进行累加,得到最终的预测值。
二、算法原理
1. 梯度下降思想
梯度下降是一种常用的优化算法,用于寻找函数的最小值。在 GBDT 中,它扮演着至关重要的角色。假设我们有一个损失函数\(L\left( y,\hat{y} \right)\),其中\(y\)是真实值,\(\hat y\)是预测值。梯度下降的目标就是通过不断调整模型参数,使得损失函数的值最小化。具体来说,每次迭代时,沿着损失函数关于参数的负梯度方向更新参数,以逐步接近最优解。在 GBDT 中,虽然没有显式地更新参数(通过构建多颗决策树来拟合目标),但拟合的目标是损失函数的负梯度,本质上也是利用了梯度下降的思想。
2. 决策树的构建
GBDT 使用决策树作为弱学习器。决策树是一种基于树结构的预测模型,它通过对数据特征的不断分裂,将数据划分成不同的子集,每个子集对应树的一个节点。在每个节点上,通过某种准则(如回归任务中的平方误差最小化,分类任务中的基尼指数最小化)选择最优的特征和分裂点,使得划分后的子集在目标变量上更加 “纯净” 或具有更好的区分度。通过递归地进行特征分裂,直到满足停止条件(如达到最大树深度、节点样本数小于阈值等),从而构建出一棵完整的决策树。
3. 迭代拟合的过程
(1) 初始化模型
首先,初始化一个简单的模型,通常是一个常数模型,记为\(f_0(X)\) ,其预测值为所有样本真实值的均值(回归任务)或多数类(分类任务),记为\(\hat y_0\)。此时,模型的预测结果与真实值之间存在误差。
(2) 计算残差或负梯度
在回归任务中,计算每个样本的残差,即真实值\(y_i\)与当前模型预测值\(\hat y_{i,t-1}\)的差值\(r_{i,t}=y_i-\hat y_{i,t-1}\),其中表示迭代的轮数。在分类任务中,计算损失函数关于当前模型预测值的负梯度$$g_{i,t}=-\frac{\vartheta L(y_i,\hat y_{i,t-1})}{\vartheta \hat y_{i,t-1}}$$
(3) 拟合决策树
使用计算得到的残差(回归任务)或负梯度(分类任务)作为新的目标值,训练一棵新的决策树\(f_t(X)\)。这棵树旨在拟合当前模型的误差,从而弥补当前模型的不足。
(4) 更新模型
根据新训练的决策树,更新当前模型。更新公式为\(\hat y_{i,t}=\hat y_{i,t-1}+\alpha f_t(x_i)\),其中是学习率(也称为步长),用于控制每棵树对模型更新的贡献程度。学习率较小可以使模型训练更加稳定,但需要更多的迭代次数;学习率较大则可能导致模型收敛过快,甚至无法收敛。
(5) 重复迭代
重复步骤 (2)–(4)步,不断训练新的决策树并更新模型,直到达到预设的迭代次数、损失函数收敛到一定程度或满足其他停止条件为止。最终,GBDT 模型由多棵决策树组成,其预测结果是所有决策树预测结果的累加。
算法过程图示
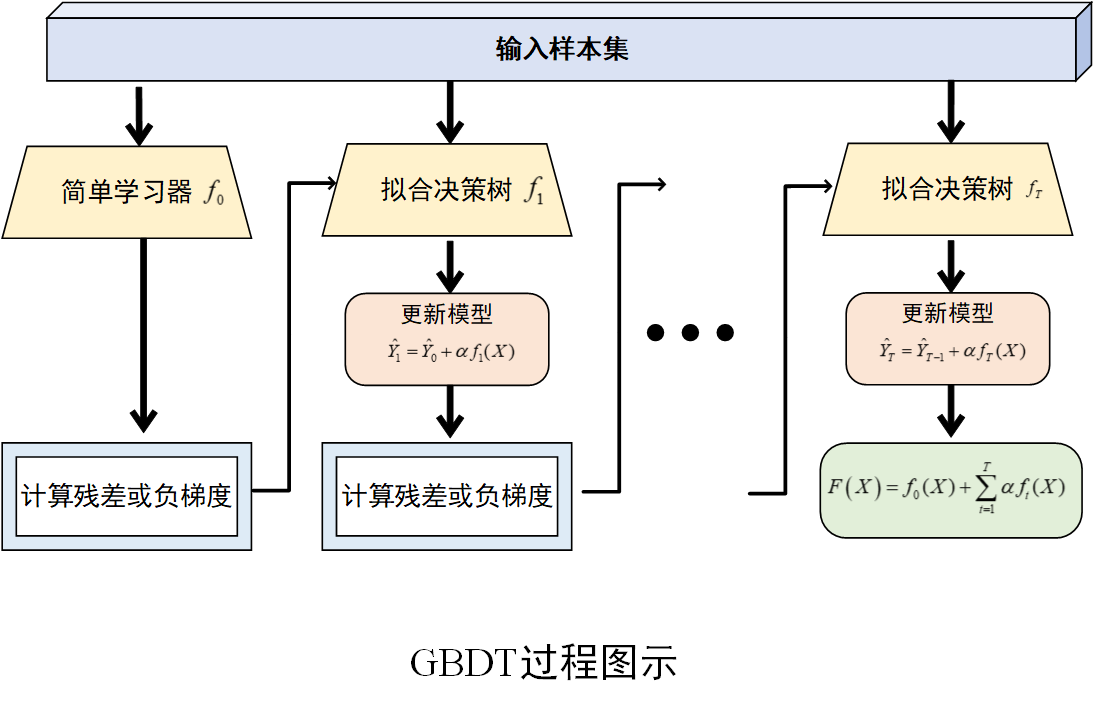
GBDT 算法将梯度下降思想与决策树相结合,通过迭代拟合残差或负梯度,逐步构建一个强大的集成模型。它在处理复杂数据和非线性关系时表现较为出色,在数据挖掘、机器学习等领域得到了广泛的应用。然而,GBDT 也存在一些缺点,如训练时间较长、对异常值较为敏感等,在实际应用中需要根据具体情况进行优化和调整 。
三、Python实现
(环境:Python 3.11,scikit-learn 1.5.1)
分类情形
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import metrics
# 生成样本数据
X, y = make_classification(n_samples=1000, n_features=50, n_informative=10, n_redundant=5, random_state=1)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 创建GDBT分类模型
gbc = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=1)
# 训练模型
gbc.fit(X_train, y_train)
# 进行预测
y_pred = gbc.predict(X_test)
# 计算准确率
accuracy = metrics.accuracy_score(y_test,y_pred)
print('准确率为:',accuracy)

回归情形
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 生成样本数据
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, noise=0.1, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建GDBT回归模型
model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse}")

End.
GBDT算法原理及Python实现的更多相关文章
- GBDT算法原理深入解析
GBDT算法原理深入解析 标签: 机器学习 集成学习 GBM GBDT XGBoost 梯度提升(Gradient boosting)是一种用于回归.分类和排序任务的机器学习技术,属于Boosting ...
- 深入学习主成分分析(PCA)算法原理(Python实现)
一:引入问题 首先看一个表格,下表是某些学生的语文,数学,物理,化学成绩统计: 首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系,那么如何判断三个学生的优秀程度呢?首先我们一眼 ...
- softmax分类算法原理(用python实现)
逻辑回归神经网络实现手写数字识别 如果更习惯看Jupyter的形式,请戳Gitthub_逻辑回归softmax神经网络实现手写数字识别.ipynb 1 - 导入模块 import numpy as n ...
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- PageRank算法原理与Python实现
一.什么是pagerank PageRank的Page可是认为是网页,表示网页排名,也可以认为是Larry Page(google 产品经理),因为他是这个算法的发明者之一,还是google CEO( ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- 【机器学习实战学习笔记(1-1)】k-近邻算法原理及python实现
笔者本人是个初入机器学习的小白,主要是想把学习过程中的大概知识和自己的一些经验写下来跟大家分享,也可以加强自己的记忆,有不足的地方还望小伙伴们批评指正,点赞评论走起来~ 文章目录 1.k-近邻算法概述 ...
- GBDT 算法:原理篇
本文由云+社区发表 GBDT 是常用的机器学习算法之一,因其出色的特征自动组合能力和高效的运算大受欢迎. 这里简单介绍一下 GBDT 算法的原理,后续再写一个实战篇. 1.决策树的分类 决策树分为两大 ...
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
随机推荐
- Luogu P3059 Concurrently Balanced Strings G 题解 [ 紫 ] [ 线性 dp ] [ 哈希 ] [ 括号序列 ]
模拟赛搬的题,dp 思路很明显,但难点就在于找到要转移的点在哪. 暴力 首先我们可以先考虑 \(k=1\) 的情况,这应该很好想,就是对于每一个右括号,找到其匹配的左括号,然后进行转移即可,这个过程可 ...
- 小程序开发实战案例五 | 小程序如何嵌入H5页面
在接入小程序过程中会遇到需要将 H5 页面集成到小程序中情况,今天我们就来聊一聊怎么把 H5 页面塞到小程序中. 本篇文章将会从下面这几个方面来介绍: 小程序承载页面的前期准备 小程序如何承载 H5 ...
- mongoDb 的启动方式
参考地址:https://www.cnblogs.com/LLBFWH/articles/11013791.html 一. 启动 1. 最简单的启动方式,前台启动,仅指定数据目录,并且使用默认的271 ...
- js中的模糊搜索( 正则表达式)
此案例在vue中实现 搜索设备ID示例 <input type="text" name="" placeholder="搜索设备ID" ...
- QT5笔记:36. QGraphicsView 综合示例 (完结撒花!)
通过此示例可以比较熟悉QGraphincsView的流程以及操作 坐标关系以及获取: View坐标:左上角为原点,通过鼠标移动事件获取 Scene坐标:中心为原点,横竖为X,Y轴.通过View.map ...
- 给大模型添加联网功能的免费方案,以langchain为例
langchain介绍 LangChain 是一个用于开发由大型语言模型 (LLM) 驱动的应用程序的框架. 简单来说,它可以帮助你更轻松地构建利用 LLM(例如 OpenAI 的 GPT 模型.Go ...
- 项目愿景 (Product Vision)、产品目标 (Product Goal) 、Sprint目标 (Sprint Goal) 及 示例
愿景(Vision) 是制定业务目标(Business Goal)的基础,后者为确定正确的产品目标 (Product Goal) 创造了环境.同样,每个产品目标作为识别有用的冲刺目标的基础.换句话说, ...
- Linux - vi & vim 编辑器
vim 具有程序编辑的能力,可以主动的以字体颜色辨别语法的正确性,方便程序设计. vim 是从vi发展出来的一个文本编辑器.代码补全.编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用. 使 ...
- Hadoop - 两个Namenode都是standby状态怎么处理
在任意一个standby的NN节点执行 再次访问 ctos01:9870页面
- Vue + Element 实现按钮指定间隔时间点击
1.业务需求 需要加一个按钮,调用第三方API,按钮十分钟之内只能点击一次,刷新页面也只能点击一次 2.思路 加一个本地缓存的时间戳,通过时间戳计算指定时间内不能点击按钮 3.实现 1)vue页面 & ...