爬取博主所有文章并保存到本地(.txt版)--python3.6
闲话:
一位前辈告诉我大学期间要好好维护自己的博客,在博客园发布很好,但是自己最好也保留一个备份。
正好最近在学习python,刚刚从py2转到py3,还有点不是很习惯,正想着多练习,于是萌生了这个想法——用爬虫保存自己的所有文章
在查了一些资料后,慢慢的有了思路。
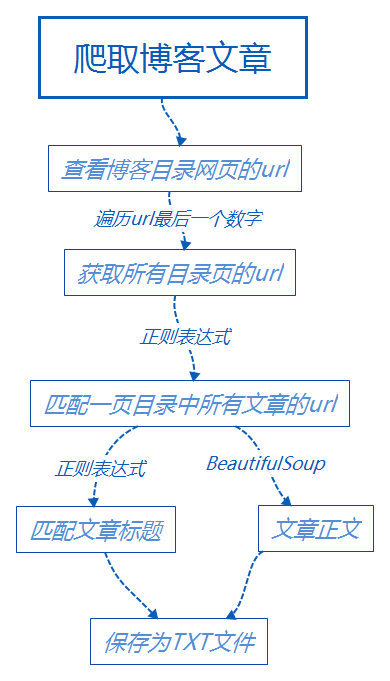
正文:
有了上面的思路后,编程就不是问题了,就像师傅说的,任何语言,语法只是很小的一部分,主要还是编程思想。于是边看语法,边写程序,照葫芦画瓢,也算实现了既定的功能:
1、现在py文件同目录下创建一个以博主名字为名的文件夹,用来存放爬取的所有文章。
2、暂时先保存成TXT文件,这个比较容易。但是缺点是无法保存图片。后面在学习直接转成PDF。
3、爬取完成后提醒我你爬取了多少片文章。
要懒就懒到位,最好不要让我动一下手就自动爬取所有文章,但是。。。。还是要看一下自己的文章目录的url吧、看一下自己有多少页目录吧,然后这两个参数填进去之后,就完美了。
提示:使用chrome浏览器,在chrome下:先按F12进入开发者模式,在网页上右键选中一块区域,然后选择【检查】,在右侧即可查看对应的HTML程序。
主要函数的实现:
1、获取所有文章的url:
def get_urls(url,pages):
"""
获取所有目录下的所有文章url
:param url: 某一页目录的url,去掉最后的数字
:param pages: 一共需要爬取的页数
:return: 返回所有文章url的列表
"""
total_urls = [] for i in range(1,pages+1): #根据一个目录的url找到所有目录 url_temp = url + str(i) html = get_html(url_temp) #获取网页源码 title_pattern = re.compile(r'<a.*?class="postTitle2".*?href="(.*?)">',re.S) #文章url正则表达式 url_temp2 = re.findall(title_pattern,html) #找到一个目录中所有文章的网址 for _url in url_temp2:
total_urls.append(_url) #所有文章url放在一起
return total_urls
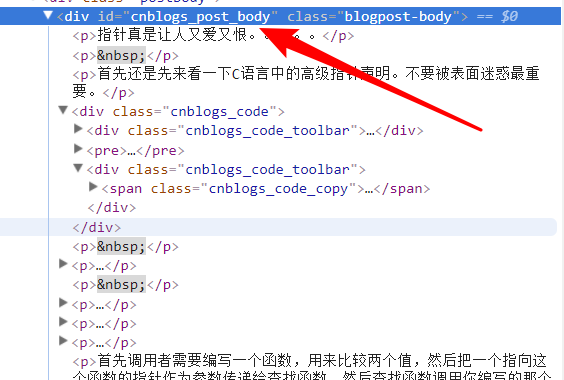
关于正则表达式的选择:这是我目录中的两篇文章标题的HTML程序:


可以发现,都在一对a标签下,class属性为:"postTitle n",其href属性就是文章的url网址。
所以正则表达式可以写为:re.compile(r'<a.*?class="postTitle2".*?href="(.*?)">',re.S)
最后调用append方法,将所有文章的url放在一个list列表里面。
2、获取文章标题:
def get_title(url):
"""
获取对应url下文章的标题,返回标题
:param url:
:return:
"""
html_page = get_html(url)
title_pattern = re.compile(r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)')
title_match = re.search(title_pattern,html_page)
title = title_match.group(2)
return title
这个也很简单,检查元素我们可以发现:

与上面一样,这个正则表达式可以选择:re.compile(r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)')
然后保留其第二个分组就是文章标题。
3、获取正文:
def get_body(url):
"""
获取url下文章的正文内容
:param url:
:return:
"""
html_page = get_html(url)
soup = BeautifulSoup(html_page,'html.parser') #HTML文档解析器
div = soup.find(id = "cnblogs_post_body")
return div.get_text()
使用BeautifulSoup模块,创建一个对象,然后使用 soup.find()方法,搜索ID为 "cnblogs_post_body" 的标签,返回标签内的文档内容。
4、下载单个文件:
def save_single_file(url):
"""
首先在py文件同目录下创建一个以博主名字为名的文件,用来存放爬取的所有文章
将文章正文保存在txt文件中,名字为文章标题
有些文章的标题可能不适合直接作为txt文件名,我们可以忽略这些文章
:param url:
:return:
"""
global article_count #使用全局变量,需要在函数中进行标识
title = get_title(url)
body = get_body(url) #获取当前目录文件,截取目录后,并自动创建文件
FILE_PATH = os.getcwd()[:-0]+author+'_''text\\'
if not os.path.exists(FILE_PATH):
os.makedirs(FILE_PATH) try:
filename = title + '.txt'
with open('D:\learning python\coding_python3.6\cnblog\\Andrew_text\\'+filename,'w',encoding='utf-8') as f:
f.write(body) #正文写入文件
article_count+= 1 #计数变量加1,统计总的下载文件数
except:
pass print(title+" file have saved...") #提示文章下载完毕
对于 os.getcwd()方法,
如果a.py文件存放的路径下为:D:\Auto\eclipse\workspace\Testhtml\Test
通过os.getcwd()获取的路径为:D:\Auto\eclipse\workspace\Testhtml\Test
使用os.getcwd()[:-4]截取到的路径为:D:\Auto\eclipse\workspace\Testhtml\ ,注意这个-4是在当前目录字符串下,向前截取4个字符后的目录。不想截取的话,直接省略数字,但是要有 [:]
使用下面的命令则在3步骤下新建文件夹,名为:变量author_text:
#获取当前目录文件,截取目录后,并自动创建文件
FILE_PATH = os.getcwd()[:-0]+author+'_''text\\'
if not os.path.exists(FILE_PATH):
os.makedirs(FILE_PATH)
5、最终下载:
def save_files(url,pages):
"""
调用单个文件保存函数,循环保存所有文件
:param url:传入任意一个目录的url,但是要注意去掉最后的数字。
:return:
"""
total_urls = get_urls(url,pages)
print("get all the urls..."+'\n')
print(total_urls) #获取的文章url正确 for urls in total_urls:
save_single_file(urls) #输出下载的总文章数
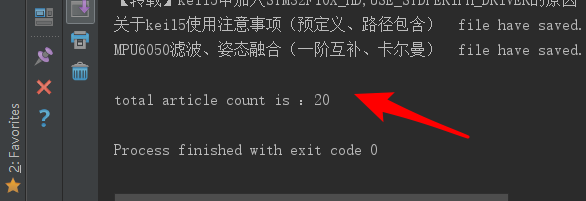
print('\n' + "total article count is :%d"%article_count)
运行结果:
参考资料:
项目启发:http://www.cnblogs.com/xingzhui/p/7881905.html
正则表达式:https://blog.csdn.net/qq_878799579/article/details/72887612
爬取博主所有文章并保存到本地(.txt版)--python3.6的更多相关文章
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 爬取博主的所有文章并保存为PDF文件
继续改进上一个项目,上次我们爬取了所有文章,但是保存为TXT文件,查看不方便,而且还无法保存文章中的代码和图片. 所以这次保存为PDF文件,方便查看. 需要的工具: 1.wkhtmltopdf安装包, ...
- python:爬取博主的所有文章的链接、标题和内容
以爬取我自己的博客为例:https://www.cnblogs.com/Mr-choa/ 1.获取所有的文章的链接: 博客文章总共占两页,比如打开第一页:https://www.cnblogs.com ...
- 如何优雅的爬取 gzip 格式的页面并保存在本地(java实现)
1. 引言 在爬取汽车销量数据时需要爬取 html 保存在本地后再做分析,由于一些页面的 gzip 编码格式, 获取后要先解压缩,否则看到的是一片乱码.在网络上仔细搜索了下,终于在这里找到了一个优雅的 ...
- 记一次 爬取LOL全皮肤原画保存到本地的实例
#爬取lol全英雄皮肤 import re import traceback # 异常跟踪 import requests from bs4 import BeautifulSoup #获取html ...
- 使用JAVA爬取博客里面的所有文章
主要思路: 1.找到列表页. 2.找到文章页. 3.用一个队列来保存将要爬取的网页,爬取队头的url,如果队列非空,则一直爬取. 4.如果是列表页,则抽取里面所有的文章url进队:如果是文章页,则直接 ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- 爬虫---lxml爬取博客文章
上一篇大概写了下lxml的用法,今天我们通过案例来实践,爬取我的博客博客并保存在本地 爬取博客园博客 爬取思路: 1.首先找到需要爬取的博客园地址 2.解析博客园地址 # coding:utf-8 i ...
随机推荐
- Scheme change not implemented
1.错误描述 2.错误原因 由于在改变Java代码中的方法或运行代码出现,导致Tomcat编译的代码不能替换工作空间的代码,即不能及时同步,出现错误 3.解决办法 (1)关闭Tomcat,clean一 ...
- hdu5904 LCIS
这题惩罚我这种经常不管常数的懒人 直接 1e6 TLE 如果1e5对数组枚举过 诶其实很想吐槽些伤心事,但是还是不想在博客上吐口水 不管今年比赛结果如何 请享受比赛 #include<bits/ ...
- 优先队列运用 TOJ 4123 Job Scheduling
链接:http://acm.tju.edu.cn/toj/showp4123.html 4123. Job Scheduling Time Limit: 1.0 Seconds Memory ...
- Html行内元素和块级元素
1.关于行内元素和块状元素的说明 根据CSS规范的规定,每一个网页元素都有一个display属性,用于确定该元素的类型,每一个元素都有默认的display属性值,比如div元素,它的默认display ...
- 对于Hibernate和MyBatis的区别与利弊,谈谈你的看法
Hibernate与MyBatis的对比: 1.MyBatis非常简单易学,与Hibernate相对复杂,门槛较高: 2.两者都是比较优秀的开源产品: 3.当系统属于二次开发,无法对于数据库结构做到控 ...
- 【BZOJ4816】数字表格(莫比乌斯反演)
[BZOJ4816]数字表格(莫比乌斯反演) 题面 BZOJ 求 \[\prod_{i=1}^n\prod_{j=1}^mf[gcd(i,j)]\] 题解 忽然不知道这个要怎么表示... 就写成这样吧 ...
- CDQ 分治算法模板
CDQ分治 1.三维偏序问题:三维偏序(陌上花开) #include<bits/stdc++.h> #define RG register #define IL inline #defin ...
- CodeIgniter怎么引入公共的头部或者尾部文件(实现随意引入或分区域创建header.html,bodyer.html,footer.html)
除非你天赋异禀,凡事基本对任何人来说都是开头难的,且开头的事情如果没有做好 往往会打掉一个人对于某件事的希望及其激情,所以咱们先从容易的事情开始慢慢建立自己 信心.后面的事情咱们再慢慢推进. 如果你是 ...
- vmstat结果在不同操作系统上的解释
vmstat是各种unix上的通用工具,但在不同系统上,结果的解释却不同,最容易混淆的是结果的memory部分: 1.linux: vmstat输出结果中: memory: swapd:已用swap区 ...
- SpringCache @Cacheable 在同一个类中调用方法,导致缓存不生效的问题及解决办法
由于项目需要使用SpringCache来做一点缓存,但自己之前没有使用过(其实是没有听过)SpringCache,于是,必须先学习之. 在网上找到一篇文章,比较好,就先学习了,地址是: https:/ ...