Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储。
多维数据:数据索引 超过一俩个 键。
Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据。
实践中,更直观的形式是通过 层级索引(Hierarchical indexing, 多级索引 = 》 muti-indexing)
配合 多个不同 等级的一级索引 一起使用。
本节介绍 MultiIndex对象的使用,以及 普通索引 与 层级索引的转换
多级索引Series
- 笨方法

- 好方法: MultiIndex
上面的笨方法 是用元组来表示索引 就是 多级索引的基础。
可以用元组创建一个多级索引

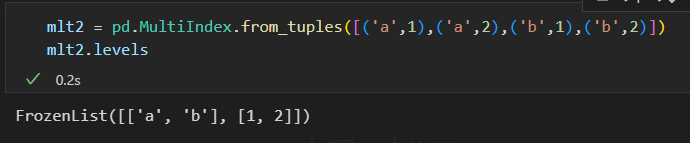
levels 属性表示索引的等级 。
前面的 Series对象 使用索引重置(reindex)就转换为MultiIndex

切片获取 2010 年的数据

- 高维数据的多级索引
可以使用一个带行 列 索引的 简单DataFrame 代替前面的多级索引。
unstack()方法可以快速将一个多级索引的Series 转换为普通索引的DataFrame.

stack()方法 反过来

why:
可以使用含多级索引的一维Series 表示 二维数据,
就可以使用
Series 或DataFrame 表示 三维 甚至更高维度的数据。
多级索引 每 增加 以及,就表示数据增加一维。
比如:增加一列显示每一年 各州的人口统计指标。
对于带有MultiIndex的对象。增加一列,就和DataFrame一样简单。

多级索引创建方法
为Series 和 DataFrame 创建多级索引 最 直接 的办法就是将index参数设置为至少 二维的索引数组。
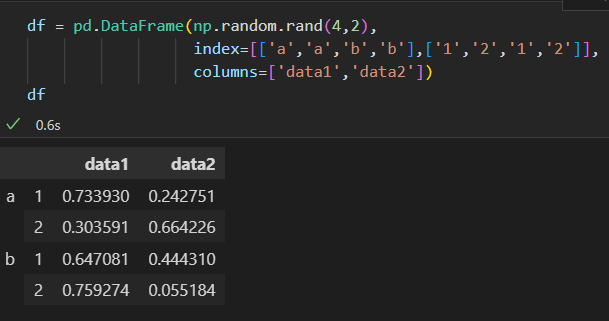
同理,将元组作为键的字典传递给Pandas, Pandas也会默认转换为MultiIndex
显示的创建多级索引
- 一个不同等级的若干简单数组组成的列表来构见MultiIndex

2) 包含多个索引值得元组构成的列表
3) 俩个索引的笛卡尔积
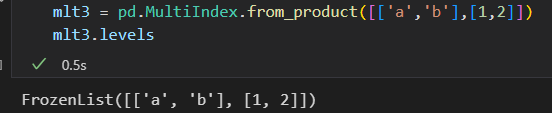
4)直接提供levels ,注意老版本是labels,新版本是code了。

在创建Series 或 DataFrame时,可以将这些对象作为index参数。 或者通过reindex方法更新Series/DataFrame.
多级索引的等级名称

多级列索引
行与列是对称的。

多级索引的取值与切片
1)Series多级索引
单个元素

局部取值
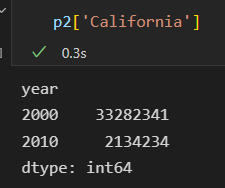
局部切片

较低层级的索引

布尔掩码

花哨索引

2)DataFrame多级索引
DataFrame的基本索引是列索引。

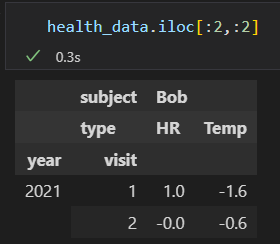

传递多个层级的索引元组


2022年5月31日23:18:51
多级索引行列转换
1) 有序的索引和无序的索引
如果MultiIndex不是有序的索引,那么大多数切片操作都会失败。
局部切片要求MultiIndex各级索引 有序。 按照字典序。


索引排序。 sort_index() sortlevel()


- 索引stack与unstack
unstack 将一个多级的索引数据 转为 简单的二维形式, level 设置转换的索引层级。

levle=1

stack是unstack的逆操作。
3)索引的设置 与 重置
层级数据维度转换的另一种方法是 行列标签转换。
可以通过reset_index方法实现。
Series中使用该方法, 会生成一个列标签中包含之前行索引 标签的state 和 year的 DataFrame.

set_index 逆操作。

多级索引的数据累计方法
可以设置参数 level实现对数据子集的累计操作。

增加axis参数。就可以累计了

Python数据科学手册-Pandas:层级索引的更多相关文章
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
随机推荐
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 9.4 苹果macOS电脑如何安装Android开发环境(Android Studio)
下载 来到官方下载界面(需要 科 学 上 网),下载最新版本,点击Download,然后同意协议,在点击下载:如果平常看文档,可以点击Google中国Android开发者官网(部分用户可能也需要科 学 ...
- charles(CA证书)的app端安装
在使用charles进行的app抓包的时候势必需要对他进行配置: 1. pc端: 第一步: http请求接收charles > proxy > proxy setting > por ...
- P2599 [ZJOI2009]取石子游戏 做题感想
题目链接 前言 发现自己三岁时的题目都不会做. 我发现我真的是菜得真实. 正文 神仙构造,分讨题. 不敢说有构造,但是分讨我只服这道题. 看上去像是一个类似 \(Nim\) 游戏的变种,经过不断猜测结 ...
- 基于MATLAB静态目标分割的药板胶囊检测
一.目标 1 将药板从黑色背景中分离(药板部分显示为白色,背景显示为黑色): 2 根据分割结果将药板旋转至水平: 3 提取药板中的药丸的位置信息: 二.方法描述 处理图像如下: (1)首先将图像转为灰 ...
- 函数式(Functional)接口
public class LambdaTest2 { @Test public void test1(){ happyTime(500, new Consumer<Double>() { ...
- Python 内置logging 使用详细讲
logging 的主要作用 提供日志记录的接口和众多处理模块,供用户存储各种格式的日志,帮助调试程序或者记录程序运行过程中的输出信息. logging 日志等级 logging 日志等级分为五个等级, ...
- Hbuilderx Eslint配置
[参照链接]https://blog.csdn.net/m0_67394002/article/details/123346267 安装插件 eslint-js eslint-plugin-vue 复 ...
- jdbc 01: 连接mysql,并实现数据插入
jdbc连接mysql,并实现数据插入 package com.examples.jdbc.o1_连接与插入; import java.sql.*; /* jdbc数据库连接六步 */ public ...
- 【New】Code Insertion
#include <bits/stdc++.h> using namespace std; #define Multicase() for(int T = read() ; T ; T-- ...