大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建。
对应4个IP为192.168.1.60、61、62、63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即可。
软件版本选择:
虚拟机:VMware Workstation 12 Pro 版本:12.5.9 build-7535481
Linux:CentOS-7-x86_64-DVD-1804
FTP工具:FileZilla-3.37.4
安装CentOS虚拟机
首先安装虚拟机,成功后重启电脑
新建虚拟机, 配置直接用推荐的经典
选择CentOS的IOS光盘映像
剩下用默认设置,20G硬盘,1G内存,1核CPU
等待加载虚拟机,安装Linxu
语言选择中文
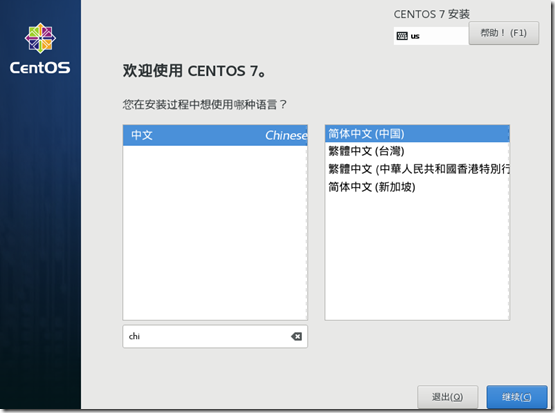
系统安装位置需要进入一次,可以自己分区,不过这里是测试,默认一个区,点击完成
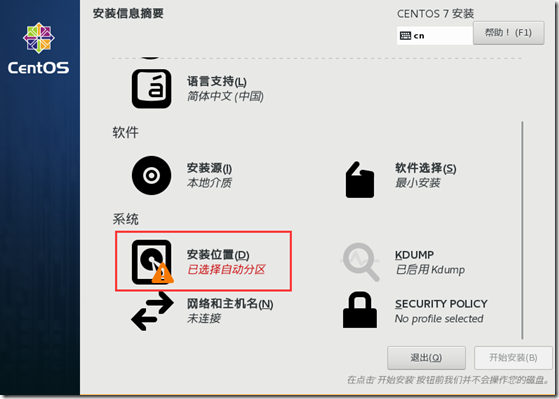
打开自动获取IP
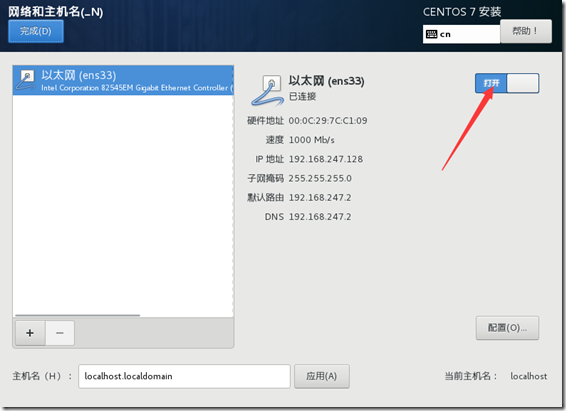
可以在软件选择中指定默认要安装的内容,不过这里因测试,且知道具体安装了什么软件,我这里选择最小安装
设置root账号的密码,输入完毕点击两次完成键,完成配置开始安装,安装完毕重置
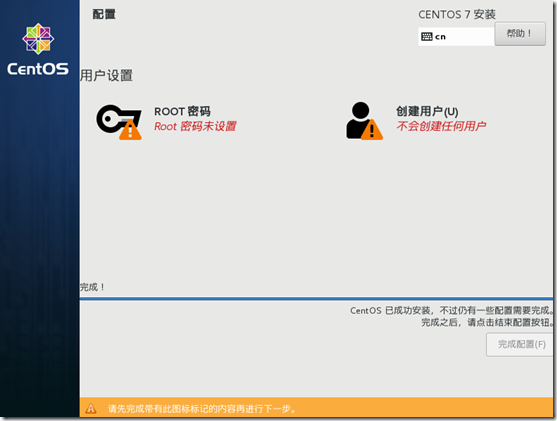
配置Linux环境
输入用户名root,输入密码,登录系统
vm上右键虚拟机,设置,修改网络适配器从NAT模式改为桥接模式
安装网络工具,用于配置IP,若报错无法访问,可能是windows服务没启动,启用VMware DHCP Service,VMware NAT Service两个服务
yum install net-tools -y
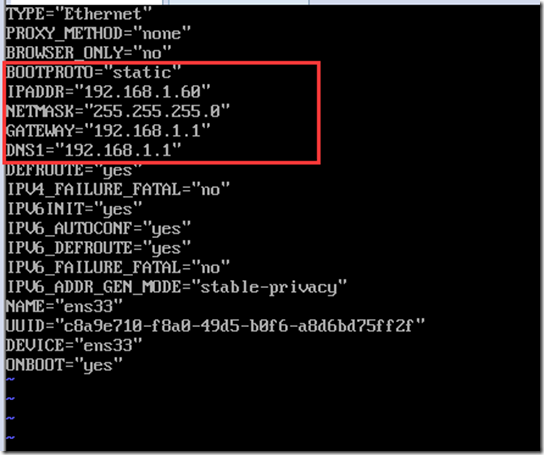
配置静态IP,最后ens33根据各自具体网卡名字来设置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
按i切换到INSERT模式,修改配置文件如下,将BOOTPROTO的值从dhcp改为static,并且增加ip配置,修改完毕按esc,输入:wq保存退出
启用配置,重启网络服务
systemctl restart network
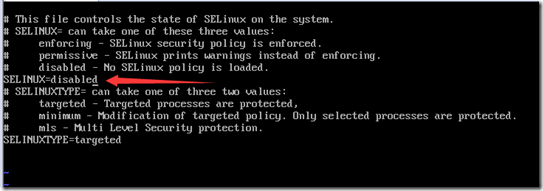
关闭selinux,打开selinux配置文件
vi /etc/selinux/config
修改SELINUX的值为disabled
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
安装vsftp用于上传各种文件
yum install vsftpd –y
启用ftp并添加ftp用户
systemctl enable vsftpd
systemctl start vsftpd
useradd ftpuser -s /sbin/nologin
passwd ftpuser
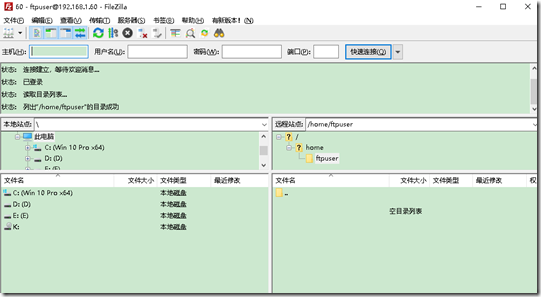
用FileZilla连接,使用普通FTP连接,输入刚创建的ftp用户名密码
配置ssh免密登录
ssh-keygen -t rsa -P ""
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 0600 authorized_keys
ssh localhost #首次需输入yes,退出登录logoutlogout至此Linux基础环境搭建完毕。
大数据中Linux集群搭建与配置的更多相关文章
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据-spark HA集群搭建
一.安装scala 我们安装的是scala-2.11.8 5台机器全部安装 下载需要的安装包,放到特定的目录下/opt/workspace/并进行解压 1.解压缩 [root@master1 ~]# ...
随机推荐
- November 6th 2016 Week 46th Sunday
The starting point of all achievements is desire. 成功的第一步是渴望. Those who make great achievements are o ...
- 题解 P1894 【[USACO4.2]完美的牛栏The Perfect Stall】
题面 农夫约翰上个星期刚刚建好了他的新牛棚,他使用了最新的挤奶技术.不幸的是,由于工程问题,每个牛栏都不一样.第一个星期,农夫约翰随便地让奶牛们进入牛栏,但是问题很快地显露出来:每头奶牛都只愿意在她们 ...
- 学习博客之Java继承多态接口
这一篇博客主要是对软工前一阶段学习的总结,主要是对Java的学习总结,包括三部分:Java的继承.多态和接口 Java的继承 继承是面向对象的三大特性之一,能够实现软件的复用. Java子类继承父类的 ...
- JVM虚拟机20:内存区域详解(Eden Space、Survivor Space、Old Gen、Code Cache和Perm Gen)
1.内存区域划分 根据我们之前介绍的垃圾收集算法,限定商用虚拟机基本都采用分代收集算法进行垃圾回收.根据对象的生命周期的不同将内存划分为几块,然后根据各块的特点采用最适当的收集算法.大批对象死去.少量 ...
- 通过golang 查询impala
cloudera官方没有提供impala基于golang的驱动,github有github.com/bippio/go-impala package main import ( "conte ...
- chrome的uget扩展程序红色 Unable to connect with uget-integrator问题
我们根据网上的教程在ubuntu16.04中安装下载工具uget+aria2并配置chrome时,最后重新打开chrome浏览器,发现uget扩展程序是红色的,点开看到”Unable to conne ...
- Discuz!教程之删除注释云平台JS,加快DISCUZ访问
很多站长反应打开网站的时候有个http://discuz.gtimg.cn/cloud/scripts/discuz_tips.js?v=1一直在加载中,导致网页打开速度很慢,这个时候你可以按本文教程 ...
- 插件式程序开发及其应用(C#)
1. 定义 所谓“插件模型”,指应用程序由一些动态的独立模块构成,每个模块均具有一个或多个服务,并满足一定的插件协议,能够借助主程序实现主程序-插件:插件-插件之间的通讯. 应用该模型的系统,具有以 ...
- unittest中setUp与setUpClass执行顺序
最基础的概念 1.setUP(self)看下面的执行顺序 import unittest class TestGo(unittest.TestCase): def setUp(self): print ...
- ZOJ 2017 Quoit Design 经典分治!!! 最近点对问题
Quoit Design Time Limit: 5 Seconds Memory Limit: 32768 KB Have you ever played quoit in a playg ...