第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['hao.360.cn']
start_urls = ['https://hao.360.cn/'] def parse(self, response): #这里做页面的各种获取以及处理 #递归查找url循环执行
hq_url = Selector(response=response).xpath('//a/@href') #查找到当前页面的所有a标签的href,也就是url
for url in hq_url: #循环url
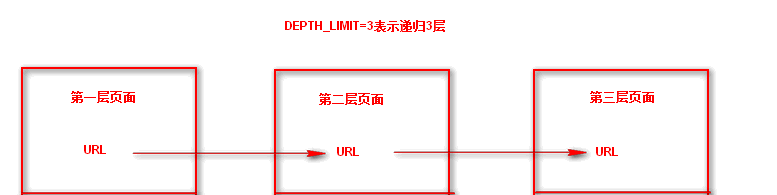
yield scrapy.Request(url=url, callback=self.parse) #每次循环将url传入Request方法进行继续抓取,callback执行parse回调函数,递归循环 #这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url的更多相关文章
- 五 web爬虫,scrapy模块,解决重复ur——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 记录url可以是缓存,或者数据库,如果保存数据库按照以下方式: id URL加密 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第一百二十六节,JavaScript,XPath操作xml节点
第一百二十六节,JavaScript,XPath操作xml节点 学习要点: 1.IE中的XPath 2.W3C中的XPath 3.XPath跨浏览器兼容 XPath是一种节点查找手段,对比之前使用标准 ...
- 第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承
第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承 母板-子板-母板继承 母板继承就是访问的页面继承一个母板,将访问页面的内容引入到母板里指定的地方,组合成一个新页 ...
- 第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表、课程评论表、用户收藏表、用户消息表、用户学习表
第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表.课程评论表.用户收藏表.用户消息表.用户学习表 创建名称为ap ...
随机推荐
- (原创)c++11改进我们的模式之改进观察者模式
和单例模式面临的是同样的问题,主题更新的接口难以统一,很难做出一个通用的观察者模式,还是用到可变模板参数解决这个问题,其次还用到了右值引用,避免多余的内存移动.c++11版本的观察者模式支持注册的观察 ...
- ny24 素数距离的问题 筛选法求素数
素数距离问题时间限制:3000 ms | 内存限制:65535 KB难度:2 描述 现在给出你一些数,要求你写出一个程序,输出这些整数相邻最近的素数,并输出其相距长度.如果左右有等距离长度素 ...
- iOS开发如何学习前端(2)
iOS开发如何学习前端(2) 上一篇成果如下. 实现的效果如下. 实现了一个横放的<ul>,也既iOS中的UITableView. 实现了当鼠标移动到列表中的某一个<li>,也 ...
- Vue2键盘事件
这两天学习了Vue.js 感觉组件这个地方知识点挺多的,而且很重要,所以,今天添加一点小笔记,学习一下Vue键盘事件 键盘事件 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 ...
- Python3在指定路径下递归定位文件中出现的字符串
[本文出自天外归云的博客园] 脚本功能:在指定的路径下递归搜索,找出指定字符串在文件中出现的位置(行信息). 用到的python特性: 1. PEP 318 -- Decorators for Fun ...
- Inner Functions - What Are They Good For?
Referece: https://realpython.com/blog/python/inner-functions-what-are-they-good-for/ Let’s look at t ...
- delphi判断线程是否正在运行
相关资料:http://www.delphitop.com/html/xiancheng/376.html unit Unit1; interface uses Winapi.Windows, Win ...
- Sqlserver 2008 error 40出现连接错误的解决方法
说明(2017-5-25 15:00:16): 核心:把端口号改成1433 Sqlserver 2008 error 40出现连接错误的解决方法
- J.U.C--locks--AQS分析
看一下AbstractQueuedSynchronizer(下面简称AQS)的子类就行知道,J.U.C中宣传的封装良好的同步工具类Semaphore.CountDownLatch.ReentrantL ...
- 腾讯云安装Hadoop遇到的问题
1.能正常访问bincoding.cn:50030,不能连接到9000端口 Call to bincoding.cn/123.206.212.115:9000 failed on connection ...