损失函数 hinge loss vs softmax loss
1. 损失函数
损失函数(Loss function)是用来估量你模型的预测值 f(x) 与真实值 Y 的不一致程度,它是一个非负实值函数,通常用 L(Y,f(x)) 来表示。
损失函数越小,模型的鲁棒性就越好。
损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。模型的风险结构包括了风险项和正则项,通常如下所示:

其中,前面的均值函数表示的是经验风险函数,L代表的是损失函数,后面的 Φ 是正则化项(regularizer)或者叫惩罚项(penalty term),
它可以是L1,也可以是L2,或者其他的正则函数。整个式子表示的意思是找到使目标函数最小时的θ值。
2. 常用损失函数
常见的损失误差有五种:
1. 铰链损失(Hinge Loss):主要用于支持向量机(SVM) 中;
2. 互熵损失 (Cross Entropy Loss,Softmax Loss ):用于Logistic 回归与Softmax 分类中;
3. 平方损失(Square Loss):主要是最小二乘法(OLS)中;
4. 指数损失(Exponential Loss) :主要用于Adaboost 集成学习算法中;
5. 其他损失(如0-1损失,绝对值损失)
2.1 Hinge loss
Hinge loss 的叫法来源于其损失函数的图形,为一个折线,通用的函数表达式为:
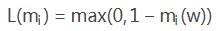
表示如果被正确分类,损失是0,否则损失就是 1−mi(w) 。

在机器学习中,Hing 可以用来解 间距最大化 的问题,最有代表性的就是SVM 问题,最初的SVM 优化函数如下:
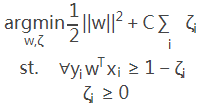
将约束项进行变形,则为:
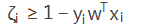
则损失函数可以进一步写为:
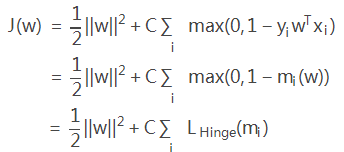
因此, SVM 的损失函数可以看作是 L2-norm 和 Hinge loss 之和。
2.2 Softmax Loss
有些人可能觉得逻辑回归的损失函数就是平方损失,其实并不是。平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到,
而逻辑回归得到的并不是平方损失。在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着
取对数求极值等等。而逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似
然函数(即maxF(y,f(x))→min−F(y,f(x)))。从损失函数的视角来看,它就成了Softmax 损失函数了。
log损失函数的标准形式:
刚刚说到,取对数是为了方便计算极大似然估计,因为在MLE中,直接求导比较困难,所以通常都是先取对数再求导找极值点。损失函数
L(Y,P(Y|X)) 表达的是样本X 在分类Y的情况下,使概率P(Y|X) 达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)
导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。
因为log函数是单调递增的,所以logP(Y|X) 也会达到最大值,因此在前面加上负号之后,最大化P(Y|X) 就等价于最小化L 了。
逻辑回归的P(Y=y|x) 表达式如下(为了将类别标签y统一为1 和0 ):

其中
2.3 Squared Loss
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(中心极限定理),
最后通过极大似然估计(MLE)可以推导出最小二乘式子。
最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。
平方损失(Square loss)的标准形式如下:
当样本个数为n时,此时的损失函数为:
Y−f(X) 表示残差,整个式子表示的是残差平方和 ,我们的目标就是最小化这个目标函数值,即最小化残差的平方和。
在实际应用中,我们使用均方差(MSE)作为一项衡量指标,公式如下:
2.4 Exponentially Loss
损失函数的标准形式是:
exp-loss,主要应用于 Boosting 算法中,在Adaboost 算法中,经过 m 次迭代后,可以得到 fm(x) :
Adaboost 每次迭代时的目的都是找到最小化下列式子的参数α 和G:
易知,Adabooost 的目标式子就是指数损失,在给定n个样本的情况下,Adaboost 的损失函数为:
关于Adaboost的详细推导介绍,可以参考Wikipedia:AdaBoost或者李航《统计学习方法》P145。
2.5 其他损失
0-1 损失函数
绝对值损失函数
上述几种损失函数比较的可视化图像如下:

3. Hinge loss 与 Softmax loss
SVM和Softmax分类器是最常用的两个分类器。
- SVM将输出 f(xi,W) 作为每个分类的评分(没有规定的标准,难以直接解释);
- 与SVM 不同,Softmax 分类器可以理解为逻辑回归分类器面对多个分类的一般话归纳,其输出(归一化的分类概率)更加直观,且可以从概率上解释。
在Softmax分类器中, 函数映射f(xi,W) 保持不变,但将这些评分值看做每个分类未归一化的对数概率,且将折叶损失替换为交叉熵损失(cross-entropy loss),公式如下:
或等价的
fj 表示分类评分向量f 中的第i 个元素,和SVM一样,整个数据集的损失值是数据集中所有样本数据的损失值Li的均值和正则化损失之和。
概率论解释:
解释为给定数据xi , W 参数,分配给正确分类标签yi 的归一化概率。
实际操作注意事项——数值稳定: 编程实现softmax函数计算的时候,中间项efyi 和 ∑jefj 因为存在指数函数,所以数值可能非常大,
除以大数值可能导致数值计算的不稳定,所以得学会归一化技巧.若在公式的分子和分母同时乘以一个常数C ,并把它变换到求和之中,就能得到一个等价公式:
C的值可自由选择,不会影响计算结果,通过这个技巧可以提高计算中的数值稳定性.通常将C设为:
该技巧就是将向量f中的数值进行平移,使得最大值为0。
准确地说,SVM分类器使用的是铰链损失(hinge loss),有时候又被称为最大边界损失(max-margin loss)。
Softmax分类器使用的是交叉熵损失(corss-entropy loss)。
Softmax分类器的命名是从softmax函数那里得来的,softmax函数将原始分类评分变成正的归一化数值,所有数值和为1,这样处理后交叉熵损失才能应用。
Example:图像识别

针对给出的图像,SVM分类器可能给你的是一个[−2.85,0.86,0.28] 对应分类“猫”,“狗”,“船”,
而softmax分类器可以计算出这三个标签的”可能性“是[0.,0160.631,0.353] ,这就让你能看出对于不同分类准确性的把握。
这里Hinge Loss计算公式为:
这里 Δ 是一个阈值,表示即使误分类,但是没有达到阈值,也不存在损失 。上面的公式把错误类别 (j≠yi) 都遍历一遍,求值加和。
设 xi 的正确类别是”船”,阈值 Δ=1 ,则对应的Hinge loss 为:
下图是对Δ 的理解,蓝色表示正确的类别,Δ 表示一个安全范围,就算是有其他的得分,只要没有到达红色的Δ 范围内,
对损失函数都没有影响。这就保证了SVM 算法的解的稀疏性。

而Softmax 损失则是对向量 fyi 指数正规化得到概率,再求对数即可。
4.总结
机器学习作为一种优化方法,学习目标就是找到优化的目标函数——损失函数和正则项的组合;有了目标函数的“正确的打开方式”,才能通过合适的机器学习算法求解优化。
不同机器学习方法的损失函数有差异,合理理解各种损失优化函数的的特点更有利于我们对相关算法的理解。
损失函数 hinge loss vs softmax loss的更多相关文章
- 机器学习中的损失函数 (着重比较:hinge loss vs softmax loss)
https://blog.csdn.net/u010976453/article/details/78488279 1. 损失函数 损失函数(Loss function)是用来估量你模型的预测值 f( ...
- caffe中softmax loss源码阅读
(1) softmax loss <1> softmax loss的函数形式为: (1) zi为softmax的输入,f(zi)为softmax的输出. <2> sof ...
- Large Margin Softmax Loss for Speaker Verification
[INTERSPEECH 2019接收] 链接:https://arxiv.org/pdf/1904.03479.pdf 这篇文章在会议的speaker session中.本文主要讨论了说话人验证中的 ...
- softmax、cross entropy和softmax loss学习笔记
之前做手写数字识别时,接触到softmax网络,知道其是全连接层,但没有搞清楚它的实现方式,今天学习Alexnet网络,又接触到了softmax,果断仔细研究研究,有了softmax,损失函数自然不可 ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- Large-Margin Softmax Loss for Convolutional Neural Networks
paper url: https://arxiv.org/pdf/1612.02295 year:2017 Introduction 交叉熵损失与softmax一起使用可以说是CNN中最常用的监督组件 ...
- Derivative of Softmax Loss Function
Derivative of Softmax Loss Function A softmax classifier: \[ p_j = \frac{\exp{o_j}}{\sum_{k}\exp{o_k ...
- 卷积神经网络系列之softmax,softmax loss和cross entropy的讲解
我们知道卷积神经网络(CNN)在图像领域的应用已经非常广泛了,一般一个CNN网络主要包含卷积层,池化层(pooling),全连接层,损失层等.虽然现在已经开源了很多深度学习框架(比如MxNet,Caf ...
随机推荐
- angular 表达式与指令
angular表达式的一些特点 属性表达式: 属性表达式是对应于当前作用域,Javascript对应的是全局window对象. AngularJS要使用window作用域的话得用$window来指向全 ...
- MLlib--SVD算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/4db529fa9f4c042673c6dc8218251f6c.html SVD算法 1.1什么是SVD? ...
- vue2.0集成百度UE编辑器,上传图片报错!!!
我这边配置进去之后,界面加载,文本输入都没有问题,就是上传图片会有问题 这张图, 左边红色框框 就是目录结构咯, 右边红色框框 就是各种网上教程给出的第一个路径配置对吧, 下面的就是绿色 服务器接口配 ...
- CSS学习笔记day1
1.css的简介 css:层叠样式表 (层叠:一层一层的:样式表:很多的属性和属性值) 使页面显示效果更好 将页面内容和显示样式进行分离,提高了显示功能. 2.css和html的结合方式(4种) 在 ...
- NV12格式转RGB的CUDA实现
NV12格式是yuv420格式的一种,NV12格式的u,v排布顺序为交错排布,假如一幅图像尺寸为W*H,则先Y分量有W*H个,然后U分量和V分量交错排布,U分量和V分量各有W*H/4个,U,V加起来总 ...
- bootstrap 响应式图片自适应图片大小
<img src="..." class="img-responsive center-block" > 或者 $(window).load(fun ...
- Java中的对象Object方法之---wait()和notifiy()
这一篇咋们继续,接着来介绍wait()和notify()方法,我们都知道这两个方法和之前介绍的方法不太一样,那就是这两个方法是对象Object上的,不属于Thread类上的.我们也知道这两个方法是实现 ...
- javascript之this
全局作用域的this this == window //true this.a = 8 window.a 一般函数的this function thisTest(){ return this; } t ...
- [转]sysctl -P 报错解决办法
问题症状 修改 linux 内核文件 #vi /etc/sysctl.conf后执行sysctl -P 报错 error: "net.bridge.bridge-nf-call-ip6ta ...
- ZooKeeper对比Eureka
刚开始看到Eureka这个单词的时候真心不会念,查了后发现他有一个好听的名字,来,大家一起念 [ jʊ'rikə ] 简介 Eureka本身是Netflix开源的一款提供服务注册和发现的产品,并且提供 ...