使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面
查看源代码你会发现

全是js代码,说明今日头条的内容是通过js动态生成的。
用火狐浏览器F12查看得知
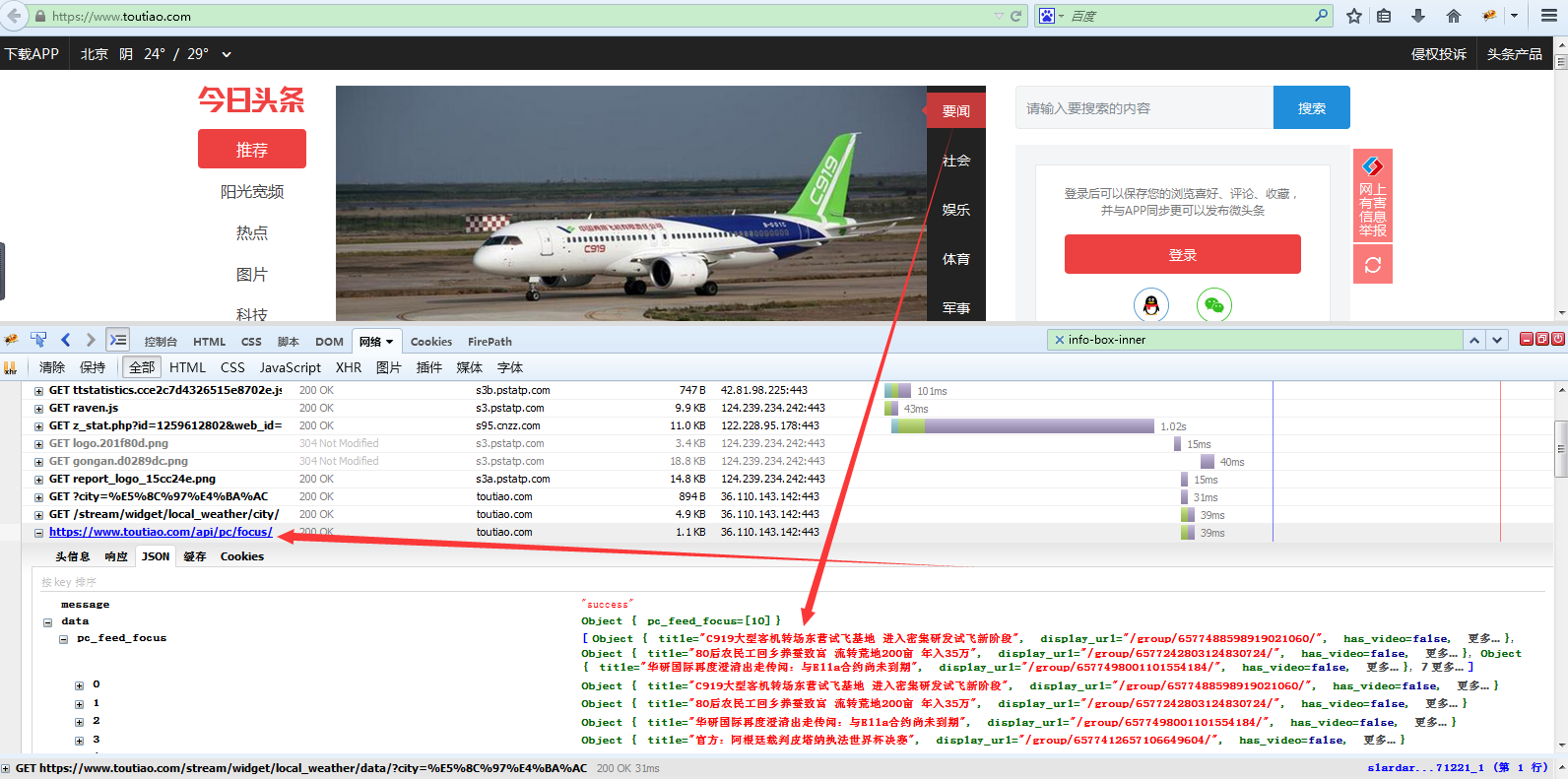
得到了今日头条的推荐新闻的接口地址:https://www.toutiao.com/api/pc/focus/
单独访问这个地址得到
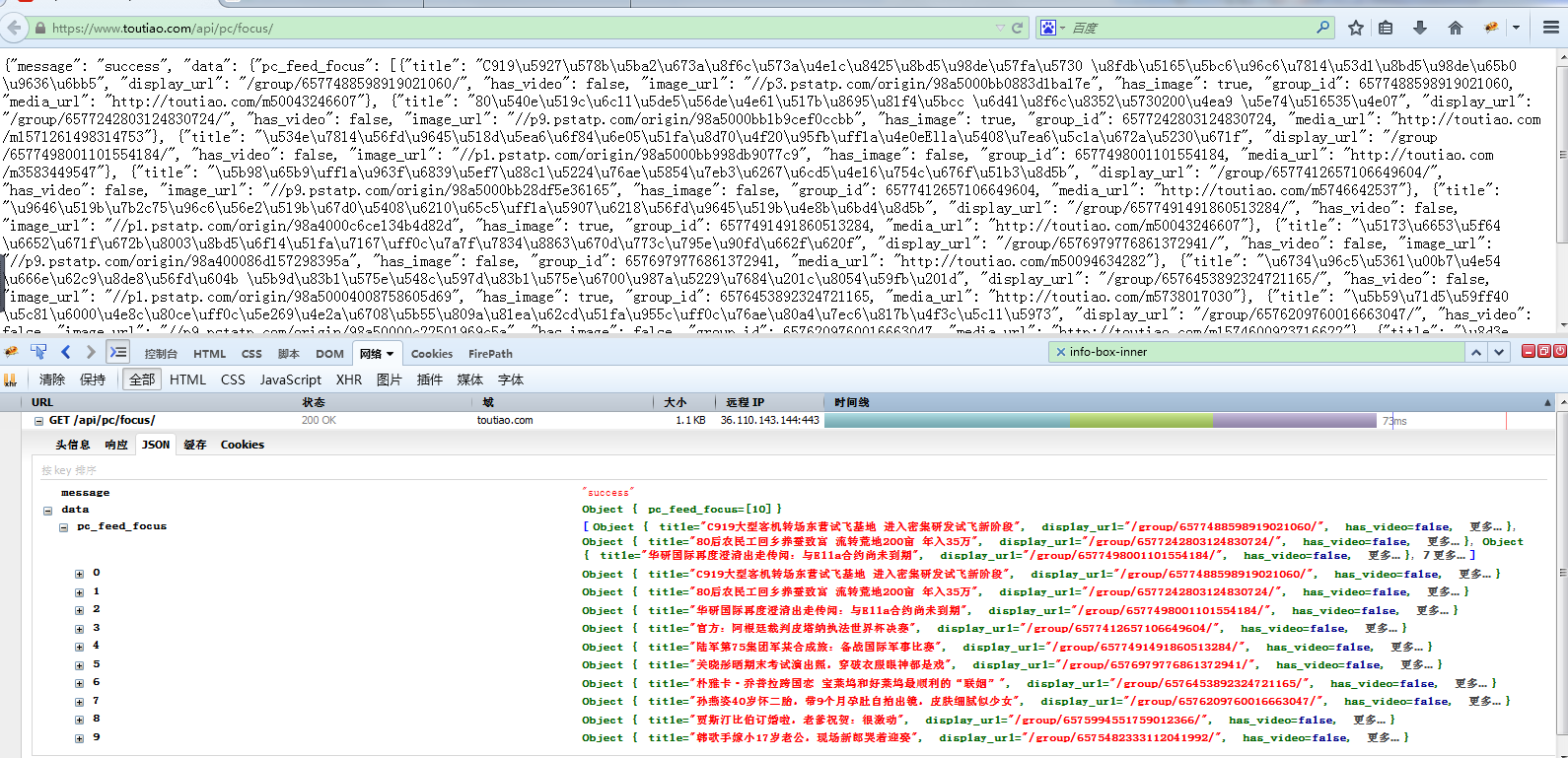
此接口得到的数据格式为json数据
我们用scrapy+selenium+PhantomJS的方式获取今日头条推荐的内容
下面是是scrapy中最核心的代码,位于spiders中的toutiao_example.py
# -*- coding: utf-8 -*-
import scrapy
import json
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import re class ToutiaoExampleSpider(scrapy.Spider):
name = 'toutiao_example'
allowed_domains = ['toutiao.com']
start_urls = ['https://www.toutiao.com/api/pc/focus/'] ###今日头条焦点的api接口
def parse(self, response):
conten_json=json.loads(response.text)
conten_news=conten_json['data'] ###从json数据中抽取data字段数据,其中data字段数据里面包含了pc_feed_focus这个字段,其中这个字段包含了:新闻的标题title,链接url等信息
for aa in conten_news['pc_feed_focus']:
title=aa['title']
link_url='https://www.toutiao.com'+aa['display_url'] ###如果写(www.toutiao.com'+aa['display_url'])会报错,加上https://,(https://www.toutiao.com'+aa['display_url'])则不会报错!
link_url_new=link_url.replace('group/','a')###把链接https://www.toutiao.com/group/6574248586484122126/,放到浏览器中,地址会自动变成https://www.toutiao.com/a6574248586484122126/这个。所以我们需要把group/ 替换成a yield scrapy.Request(link_url_new, callback=self.next_parse) def next_parse(self, response): dcap = dict(DesiredCapabilities.PHANTOMJS) # 设置useragent信息
dcap['phantomjs.page.settings.userAgent'] = (
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0 ') # 根据需要设置具体的浏览器信息
driver = webdriver.PhantomJS(desired_capabilities=dcap) #封装浏览器信息) # 指定使用的浏览器, #driver.set_page_load_timeout(5) # 设置超时时间
driver.get(response.url)##使用浏览器请求页面 time.sleep(3)#加载3秒,等待所有数据加载完毕 title=driver.find_element_by_class_name('title').text ###.text获取元素的文本数据
content1=driver.find_element_by_class_name('abstract-index').text###.text获取元素的文本数据
content2=driver.find_element_by_class_name('abstract').text###.text获取元素的文本数据 content=content1+content2 print(title,content,6666666666666666)
driver.close() #data = driver.page_source# 获取网页文本
#driver.save_screenshot('1.jpg') # 系统截图保存
运行代码我们得到结果为标题加内容呈现方式如下

使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)的更多相关文章
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- 使用python-aiohttp爬取今日头条
http://blog.csdn.net/u011475134/article/details/70198533 原出处 在上一篇文章<使用python-aiohttp爬取网易云音乐>中, ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- 爬虫七之分析Ajax请求并爬取今日头条
爬取今日头条图片 这里只讨论出现的一些问题,代码在最下面github链接里. 首先,今日头条取消了"图集"这一选项,因此对于爬虫来说效率降低了很多: 在所有代码都完成后,也许是爬取 ...
- Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
随机推荐
- PyCharm选中文件夹新建时Directory与Python package的区别
pycharm创建普通的directory和package时都是在硬盘上建立一个文件夹.但是建package时会在这个文件夹中自动地生成一个空的__init__.py文件.python的一个包是一个带 ...
- Unity TimeLine 资源结构
---恢复内容开始--- 先看一个TimeLine,如图 再来看看在Inspector中的PlayableDirector 其他参数字面意思很清楚了不再赘述,着重讲一下一个TimeLine绑定的资源. ...
- jquery中关键字写错导致的错误——dataType写成dateType(data写成date)
由于不会报错,会导致原本servlet后端传回的json字符串不能被正确解析为json格式,而只是显示为字符串. 具体错误表现为:在浏览器Console中显示为字符串,但是在json.cn中可以被正常 ...
- mysql join用法简介
为什么需要join 为什么需要join?join中文意思为连接,连接意味着关联即将一个表和多个表之间关联起来.在处理数据库表的时候,我们经常会发现,需要从多个表中获取信息,将多个表的多个字段数据组装起 ...
- Spring MVC 使用介绍(十五)数据验证 (二)依赖注入与方法级别验证
一.概述 JSR-349 (Bean Validation 1.1)对数据验证进一步进行的规范,主要内容如下: 1.依赖注入验证 2.方法级别验证 二.依赖注入验证 spring提供BeanValid ...
- WC2019游记
本来不打算写游记的,但后来想了想这么一次难忘的经历总该留下点痕迹吧...... DAY-1 走之前的最后一天,因为前一天晚上打了CF,所以早上9点才到机房.写了一道圆方树深深地体会到了来自仙人掌的恶意 ...
- 【THUSC2017】【LOJ2982】宇宙广播 计算几何 高斯消元
题目大意 有 \(n\) 个 \(n\) 维空间中的球,求这些球的所有公切面. 保证不会无解或有无穷多组解. \(n\leq 10\) 题解 你可以认为这是一道传统题. 记公切面为 \(a_1x_1+ ...
- 【CSA72G】【XSY3316】rectangle 线段树 最小生成树
题目大意 有一个 \(n\times n\) 的矩阵 \(A\).最开始 \(A\) 中每个元素的值都为 \(0\). 有 \(m\) 次操作,每次给你 \(x_1,x_2,y_1,y_2,w\),对 ...
- You Are the One HDU - 4283 (区间DP)
Problem Description The TV shows such as You Are the One has been very popular. In order to meet the ...
- 【redis】redis5.0的一些新特性
redis5.0总共增加了12项新特性,如下: 1.新增加的Stream(流)数据类型,这样redis就有了6大数据类型,另外五种是String(字符串),Hash(哈希),List(列表),Set( ...