使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用
package sogolog
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class RddFile {
def readFileToRdd(path: String): RDD[String] = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
//使用这种方法能够避免中文乱码
readFileToRdd(path,sc)
}
def readFileToRdd(path: String,sc :SparkContext): RDD[String] = {
//使用这种方法能够避免中文乱码
sc.hadoopFile(path,classOf[TextInputFormat], classOf[LongWritable], classOf[Text]).map{
pair => new String(pair._2.getBytes, 0, pair._2.getLength, "GBK")}
}
}
package sogolog
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ArrayBuffer
object MapSideJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
val userRdd = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\user",sc)
//解析用户信息
val userMapRDD:RDD[(String,String)] = userRdd.map(line=>(line.split("\t")(0),line.split("\t")(1)))
//将用户信息设置为广播变量,方便各个任务引用
val userMapBroadCast =sc.broadcast(userMapRDD.collectAsMap())
val searchLogRdd = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced",sc)
val joinResult = searchLogRdd.mapPartitionsWithIndex((index,f)=>{
val userMap = userMapBroadCast.value
var result = ArrayBuffer[String]()
var count = 0
//搜索日志表join用户表
//原来日志列为:时间 用户ID 关键词 排名 URL
//新的日志列为:时间 用户ID 用户名 关键词 排名 URL
f.foreach( log=>{
count=count+1;
val lineArrs = log.split("\t")
val uid = lineArrs(1)
val newLine:StringBuilder = new StringBuilder()
if(userMap.contains(uid)){
newLine.append(lineArrs(0)).append("\t")
newLine.append(lineArrs(1)).append("\t")
newLine.append(userMap.get(uid).get).append("\t") //从广播变量中根据用户ID获取用户名
for (i<- 2 to lineArrs.length-1){
newLine.append(lineArrs(i)).append("\t")
}
result .+= (newLine.toString())
}
})
println("partition_"+index+"处理的行数为:"+count)
result.iterator
})
//打印结果
joinResult.collect().foreach(println)
}
}
结果展示:
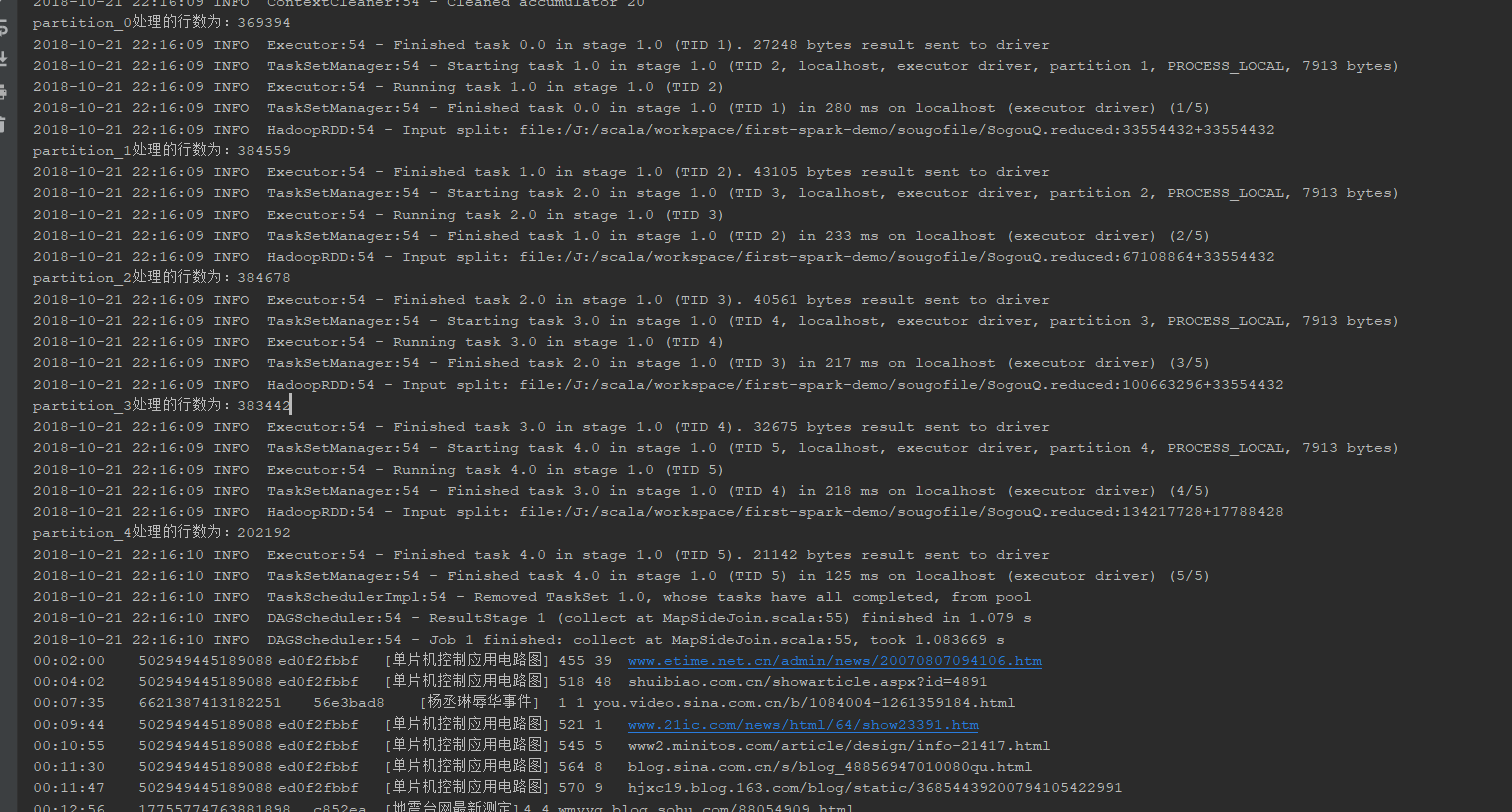
使用Spark进行搜狗日志分析实例——map join的使用的更多相关文章
- 使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- 使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog import org.apache.hadoop.io.{LongWritable, Text} import org.apache.hadoop.mapred.Tex ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- Spark之搜狗日志查询实战
1.下载搜狗日志文件: 地址:http://www.sogou.com/labs/resource/chkreg.php 2.利用WinSCP等工具将文件上传至集群. 3.创建文件夹,存放数据: mk ...
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- spark提交异常日志分析
java.lang.NoSuchMethodError: org.apache.spark.sql.SQLContext.sql(Ljava/lang/String;)Lorg/apache/spar ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- 024 关于spark中日志分析案例
1.四个需求 需求一:求contentsize的平均值.最小值.最大值 需求二:请各个不同返回值的出现的数据 ===> wordCount程序 需求三:获取访问次数超过N次的IP地址 需求四:获 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
随机推荐
- 浏览器解析JavaScript的原理
JavaScript的特点一般都知道的就是解释执行,逐行执行,就是从上到下依次执行. JavaScript的执行之前,其实还是有一些操作的,只是没有表现出来 JavaScript的执行过程: 1.语法 ...
- SQL 删除数据 的所有用法
https://blog.51cto.com/13588598/2066335 1.使用 delete 语句删除表中的数据:语法:delete from <表名> [where <删 ...
- .NET Core Agent
.NET Core Agent 熟悉java的朋友肯定知道java agent,当我看到java agent时我很是羡慕,我当时就想.net是否也有类似的功能,于是就搜索各种资料,结果让人很失望.当时 ...
- foreach循环里不能remove/add元素的原理
foreach循环 foreach循环(Foreach loop)是计算机编程语言中的一种控制流程语句,通常用来循环遍历数组或集合中的元素.Java语言从JDK 1.5.0开始引入forea ...
- IOS runtime运行机制详解(一)
OC运行机制是指,可以运行的时候动态调用函数.因为C语言必须在编译的时候就决定调用哪个函数. 我们平时写的OC代码,它在运行的时候也是转换成了runtime的方式运行的.任何方法调用本质:就是发送一个 ...
- 给web请求加遮罩动画
效果预览: css: /*#fountainG{ position:relative; margin:10% auto; width:240px; height:29px }*/ #fountainG ...
- [Web Service] Tutorial Basic Concepts
WSDL是网络服务描述语言,是一个包含关于web service信息(如方法名,方法参数)以及如何访问它. WSDL是UDDI的一部分. 作为web service 应用程序之间的接口,发音为wiz- ...
- 【Code Tools】Java微基准测试工具JMH之中级篇
一.JMH中的基本概念 1)Mode Mode 表示 JMH 进行 Benchmark 时所使用的模式.通常是测量的维度不同,或是测量的方式不同.目前 JMH 共有四种模式: 1.Throughput ...
- vue eventBus使用
类似于iframe之间的possMessage方式传参 1.eventBus.js文件 //用于兄弟组件通信 import Vue from 'vue'; export default new Vue ...
- Django的form表单
html的form表单 django中,前端如果要提交一些数据到views里面去,需要用到 html里面的form表单. 例如: # form2/urls.py from django.contrib ...