吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习随机森林RandomForestClassifier分类模型
def test_RandomForestClassifier(*data):
X_train,X_test,y_train,y_test=data
clf=ensemble.RandomForestClassifier()
clf.fit(X_train,y_train)
print("Traing Score:%f"%clf.score(X_train,y_train))
print("Testing Score:%f"%clf.score(X_test,y_test)) # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_RandomForestClassifier
test_RandomForestClassifier(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_num(*data):
'''
测试 RandomForestClassifier 的预测性能随 n_estimators 参数的影响
'''
X_train,X_test,y_train,y_test=data
nums=np.arange(1,100,step=2)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
clf=ensemble.RandomForestClassifier(n_estimators=num)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score")
ax.plot(nums,testing_scores,label="Testing Score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_num
test_RandomForestClassifier_num(X_train,X_test,y_train,y_test)

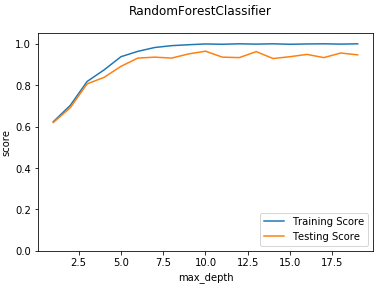
def test_RandomForestClassifier_max_depth(*data):
'''
测试 RandomForestClassifier 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
maxdepths=range(1,20)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_depth in maxdepths:
clf=ensemble.RandomForestClassifier(max_depth=max_depth)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(maxdepths,training_scores,label="Training Score")
ax.plot(maxdepths,testing_scores,label="Testing Score")
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_max_depth
test_RandomForestClassifier_max_depth(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_max_features(*data):
'''
测试 RandomForestClassifier 的预测性能随 max_features 参数的影响
'''
X_train,X_test,y_train,y_test=data
max_features=np.linspace(0.01,1.0)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_feature in max_features:
clf=ensemble.RandomForestClassifier(max_features=max_feature)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(max_features,training_scores,label="Training Score")
ax.plot(max_features,testing_scores,label="Testing Score")
ax.set_xlabel("max_feature")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_max_features
test_RandomForestClassifier_max_features(X_train,X_test,y_train,y_test)

吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 吴裕雄 python 机器学习——伯努利贝叶斯BernoulliNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
随机推荐
- 51Nod 1344 走格子 (贪心)
有编号1-n的n个格子,机器人从1号格子顺序向后走,一直走到n号格子,并需要从n号格子走出去.机器人有一个初始能量,每个格子对应一个整数A[i],表示这个格子的能量值.如果A[i] > 0,机器 ...
- 题解【AcWing91】最短Hamilton路径
题面 看到数据范围这么小,第一眼想到爆搜. 然而这样做的复杂度是 \(\mathcal{O}(n! \times n)\) 的,明显会 TLE. 于是考虑状压 DP. 我们设 \(dp_{i,j}\) ...
- 杭电oj_2035——人见人爱A^B(java实现)
原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=2035 思路:(网上学来的,偏向数学的不咋懂/捂脸)每次乘法的时候都取后三位(可能有些含糊,直接看代码吧 ...
- C++——模板、数组类
1.函数模板:可以用来创建一个通用功能的函数,以支持多种不同形参,进一步简化重载函数的函数体设计. 声明方法:template<typename 标识符> 函数声明 求绝对值的模板 #in ...
- Linux安装Tomcat,解决不能访问Manager App
在Windows环境中安装Tomcat时,只需要在Tomcat目录下/conf/tomcat-user.xml文件增加用户就可以了.在Linux系统中添加了username还是不能访问. 一.Li ...
- 查询linux版本信息
uname -a (Linux查看版本当前操作系统内核信息) cat /proc/version (Linux查看当前操作系统版本信息) cat /etc/redhat-release (Linux查 ...
- 后端——框架——缓存框架——memcached——《Memcached教程》阅读笔记
Memcached的知识点大致可以分为三个部分. 服务器部分:环境搭建. 概念:存储的数据类型,指令,内存的替换策略. 集成:与Java语言的集成. 1.搭建环境 1.1 Linux环境 在Linux ...
- Atcoder Beginner Contest 156E(隔板法,组合数学)
#define HAVE_STRUCT_TIMESPEC #include<bits/stdc++.h> using namespace std; ; ; long long fac[N] ...
- linux下部署Mono oracle配置,oracle客户端安装
一.Mono,apache安装,配置网站(以 centos 7 +apache 2为例): 安装教程以官网的教程为追,百度来的多少有版本问题. mono官网连接: 1. Mono的安装:https:/ ...
- linux 中对 mysql 数据库的基本命令
显示数据库列表 show databases; 显示库中的数据表 use mysql: // 打开库 show tables; 建库 create database 库名; 建库是设置好字符编码: c ...