用Python爬取文章,并转PDF格式电子书
wkhtmltopdf [软件],这个是必学准备好的,不然这个案例是实现不出来的
获取文章内容代码 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
发送请求, 对于url地址发送请求
解析数据, 提取内容
保存数据, 先保存成html文件
再把html文件转成PDF
代码实现 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
请求数据
python学习交流群:660193417###
import requests # 数据请求模块
url = f'https://blog.csdn.net/fei347795790/article/list/1' # 确定请求网址
# headers 请求头, 主要用于伪装python, 防止程序被服务器识别出来
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'
}
# 用requests模块里面get方式发送请求
response = requests.get(url=url, headers=headers)
print(response.text)
<Response [200]> 响应对象 200 表示请求成功
解析数据, 提取内容 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
python学习交流群:660193417###
for index in href:
html_data = requests.get(url=index, headers=headers).text
selector_1 = parsel.Selector(html_data)
title = selector_1.css('#articleContentId::text').get()
content = selector_1.css('#content_views').get()
article_content = html_str.format(article=content)
print(title)
print(article_content)
break
保存数据 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
python学习交流群:660193417###
html_path = 'html\\' + title +'.html'
with open(html_path, mode='w', encoding=' utf-8') as f:
f.write(article_content)
print(title,'保存成功')

转制为pdf文件 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF)
html_path = 'html\\ + title + '.html'
pdf_path = 'pdf\\' + title + '.pdf'
with open(html_path, mode='w', encoding='utf-8') as f:
f.write(article_content)
config = pdfkit.configuration(wkhtmltopdf=r'C:\01-Software-installation\wkhtmltopdf\bin\wkhtmltopdf.exe')
ppdfkit.from_file(html_path,pdf_path,configuration=config)
print(title,'保存成功')
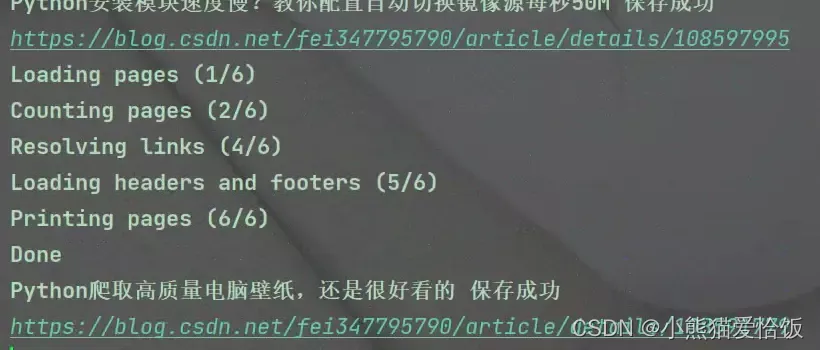
来!试试看!
用Python爬取文章,并转PDF格式电子书的更多相关文章
- python 爬取文章
这里我们利用强大的python爬虫来爬取一篇文章.仅仅做一个示范,更高级的用法还要大家自己实践. 好了,这里就不啰嗦了,找到一篇文章的url地址:http://www.duanwenxue.com/a ...
- 假期学习【十一】Python爬取百度词条写入csv格式 python 2020.2.10
今天主要完成了根据爬取的txt文档,从百度分类从信息科学类爬取百度词条信息,并写入CSV格式文件. txt格式文件如图: 为自己爬取内容分词后的结果. 代码如下: import requests fr ...
- 用Python抓取漫画并制作mobi格式电子书
想看某一部漫画,但是用手机看感觉屏幕太小,用电脑看吧有太不方面.正好有一部Kindle,决定写一个爬虫把漫画爬取下来,然后制作成 mobi 格式的电子书放到kindle里面看. 一.编写爬虫程序 用C ...
- python 爬取文章后存储excel 以及csv
import requests from bs4 import BeautifulSoup import random import openpyxl xls=openpyxl.Workbook() ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- python爬取微信公众号
爬取策略 1.需要安装python selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法.来达到登录的效果 pip3 install selenium c ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- Codeforces Round #671 (Div. 2) B. Stairs 难度1200
题目链接: Problem - 1419B - Codeforces 题目 题意 给x个格子,你可以用这x个格子去拼成楼梯 好的楼梯的要求如下: 1. 第n列有n个格子 2. 这个楼梯的所有格子可以被 ...
- redis在物理机部署模式下如何进行资源[cpu、网卡]隔离
上周末晚上运营做直播,业务代码不规范,访问1个redis竟然把1台服务器的网卡打满了,这台服务器上的其他redis服务都受到了影响.之前没有做这方面的预案,当时又没有空闲的机器可以迁移,在当时一点办法 ...
- 轻量迅捷时代,Vite 与Webpack 谁赢谁输
你知道Vite和Webpack吗?也许有不少"程序猿"对它们十分熟悉. Webpack Webpack是一个JavaScript应用程序的静态模块打包工具,它会对整个应用程序进行依 ...
- Java SE 01
强类型语言 要求变量的使用要严格符合规定,所有变量都必须先定义后使用 Java的数据类型分为两大类 基本类型(promitive type) 数值类型 ① 整数类型 byte 占1个字节范围:-128 ...
- MybatisCodeHelperPro简单使用
1.idea安装 2.连接mysql 3.创建实体等关联类 ,选择数据库表右键选择如图 4配置 生成后的 5简单应用 可以直接生成xml 总结:非常的方便快捷.
- 详谈:pNFS增强文件系统架构
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 通过 NFS(由服务器.客户机软件和两者之间的协议组成) ...
- CentOS 下 MySQL 8.0 安装部署,超详细!
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! Mysql8.0安装 (YUM方式) 首先删除系统默认或 ...
- vue实例vm的方法
import wbMessage from './wb-message' let Constructor = Vue.extend(wbMessage) let vm = new Constructo ...
- linux篇-图解cacti监控安装
1登录 admin admin 2点击devices localhost 3进入配置保存 4保存 http服务要启动哦 5一步步做 6graph tree 7执行/usr/bin/php /var/w ...
- CefSharp 白屏问题
原文 现象 我正在使用 cefsharp + winform 建立一个桌面程序用于显示网页.使用过程中程序会突然白屏,经过观察发现,在网页显示GIF动图时,浏览器子程序会突然占用较高内存(从80M上升 ...