使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class RddFile {
def readFileToRdd(path: String): RDD[String] = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
//使用这种方法能够避免中文乱码
sc.hadoopFile("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced",classOf[TextInputFormat], classOf[LongWritable], classOf[Text]).map{
pair => new String(pair._2.getBytes, 0, pair._2.getLength, "GBK")}
}
}
package sogolog import org.apache.spark.rdd.RDD /**
* 列出搜索不同关键词超过3个的用户及其搜索的关键词
*/
object userSearchKeyWordLT3 {
def main(args: Array[String]): Unit = {
//1、读入文件
val textFile = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced") //2、map操作,将每行的用户、关键词读入新的RDD中
val userKeyWordTuple:RDD[(String,String)] = textFile.map(line=>{
val arr = line.split("\t")
(arr(1),arr(2))
}) //3、reduce操作,将相同用户的关键词进行合并
val userKeyWordReduced = userKeyWordTuple.reduceByKey((x,y)=>{
//去重
if(x.contains(y)){
x
}else{
x+","+y
}
}) //4、使用filter进行最终过滤
val finalResult = userKeyWordReduced.filter(x=>{
//过滤小于10个关键词的用户
x._2.split(",").length>=10
}) //5、打印出结果
finalResult.collect().foreach(println)
}
}
运行结果:
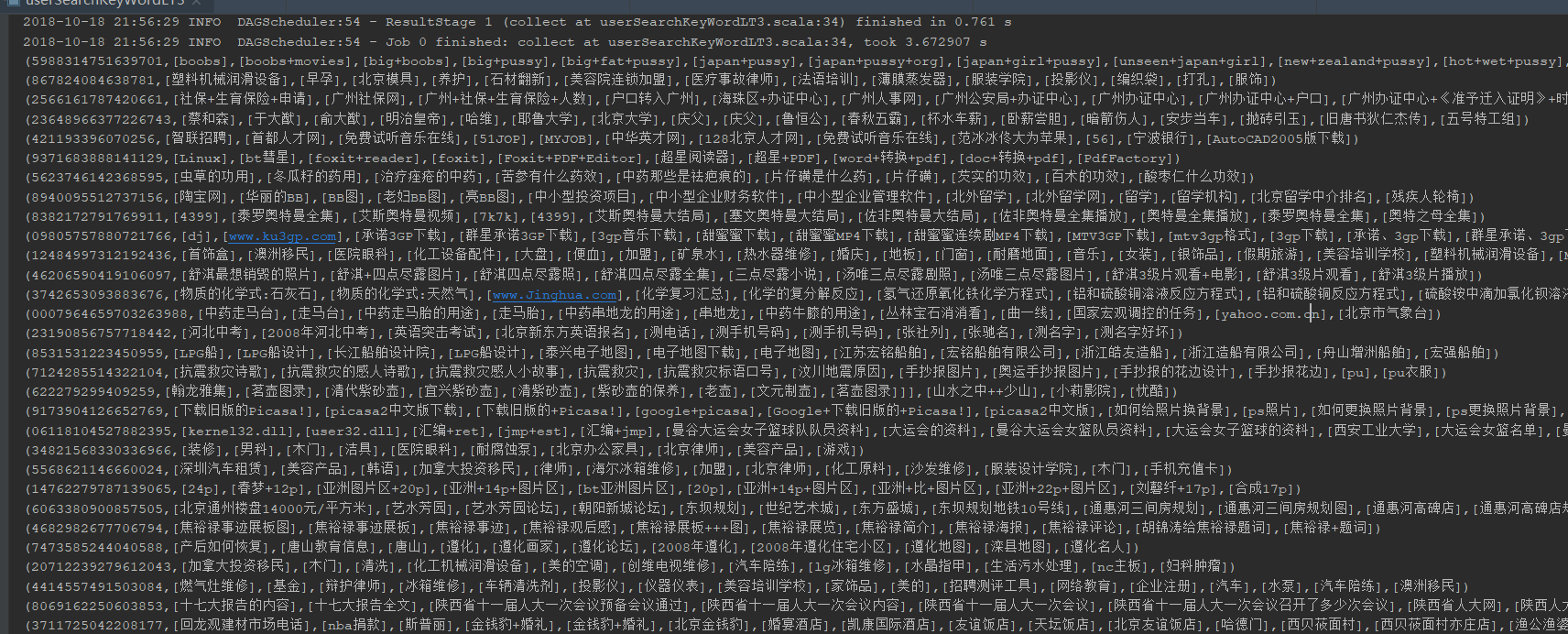
使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词的更多相关文章
- 使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- 使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用 pa ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- Spark之搜狗日志查询实战
1.下载搜狗日志文件: 地址:http://www.sogou.com/labs/resource/chkreg.php 2.利用WinSCP等工具将文件上传至集群. 3.创建文件夹,存放数据: mk ...
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- spark提交异常日志分析
java.lang.NoSuchMethodError: org.apache.spark.sql.SQLContext.sql(Ljava/lang/String;)Lorg/apache/spar ...
- (转载)shell日志分析常用命令
shell日志分析常用命令总结 时间:2016-03-09 15:55:29来源:网络 导读:shell日志分析的常用命令,用于日志分析的shell脚本,统计日志中百度蜘蛛的抓取量.抓取最多的页面.抓 ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- [spark案例学习] WEB日志分析
数据准备 数据下载:美国宇航局肯尼迪航天中心WEB日志 我们先来看看数据:首先将日志加载到RDD,并显示出前20行(默认). import sys import os log_file_path =' ...
随机推荐
- 2019-4-21 - plan
设计模式 idea中demo 在test1中使用单例测试ok
- vue-cli3.0 笔记
vue-cli 3.0 npm install -g @vue/cli # OR yarn global add @vue/cli ui 界面创建项目 vue ui 命令行创建项目 步骤 vu ...
- jQuery初识、函数、对象
初识jQuery 官方地址:http://jquery.com/ what:一个优秀的JS函数库(封装了BOM.DOM(主要)) why: HTML元素选取(选择器) HTML元素操作 CSS操作 H ...
- Maven构建 SpringMVC+Spring+MyBatis 环境整合
目录 1. Maven 项目搭建 2. Maven 插件生成 MyBatis 代码 3. 待续 ... 开发环境 开发环境请尽量保持一致,不一致的情况可能存在问题. JDK 1.7 MyEclipse ...
- python对Excel表格操作
操作场景,给一个Excel表格随机生成10万个手机号码 python中常见的对Excel操作模块 xlwt module 将数据写入Excel表 xlrd module 读取Excel表格 xlsxw ...
- 支付宝支付之App支付
与微信支付对比,支付宝支付就没有那么多坑了,毕竟支付宝开放平台的文档还是描述的很详细的. 支付宝开放平台地址:https://docs.open.alipay.com/204/105297/ 支付宝支 ...
- 出错:(unicode error) 'unicodeescape' codec can't decode bytes in position 8-9: malformed \N character escape
报错原因:python 中 \N 是换行的意思.这里要把 N 前面的 \ 转义一下.用 \\ 代替即可. Nokia_mac = np.loadtxt('data\oui\\NokiaMac201 ...
- HDU - 3652
#include<stdio.h> #include<string.h> #include<math.h> #include<time.h> #incl ...
- pycharm安装配置
激活 教程https://blog.csdn.net/u014044812/article/details/78727496 推荐修改host文件的方法 配置 https://blog.csdn.ne ...
- 《SQL 基础教程》第八章:SQL 高级处理
本章分为两个部分: 窗口函数 GROUPING 运算符 它们用于以「窗口」为单位的排序.计算总和等任务. OLAP 函数 OLAP 定义:OLAP 是 OnLIne Analytical Proces ...