新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
(一)Hive 概述

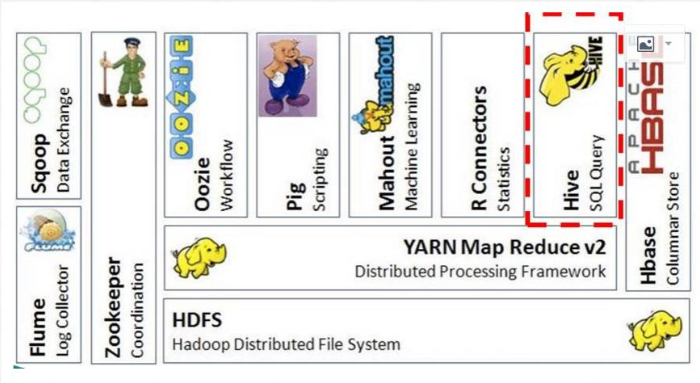
(二)Hive在Hadoop生态圈中的位置
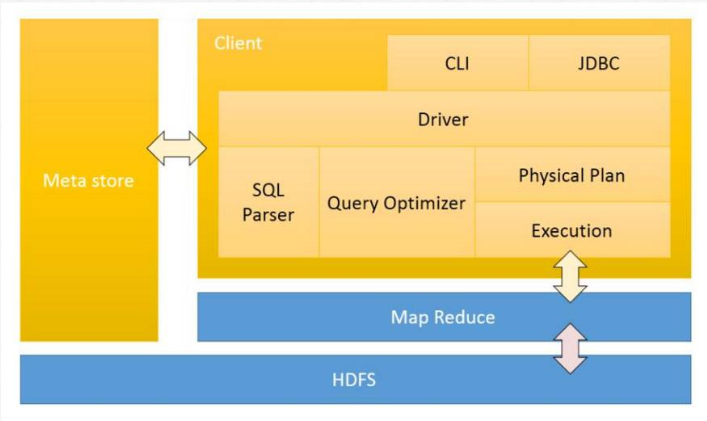
(三)Hive 架构设计

(四)Hive 的优点及应用场景

(五)Hive 的下载和安装部署
1.Hive 下载
Apache版本的Hive。
Cloudera版本的Hive。
这里选择下载Apache稳定版本apache-hive-0.13.1-bin.tar.gz,并上传至bigdata-pro03.kfk.com节点的/opt/softwares/目录下。
2.解压安装hive
tar -zxf apache-hive-0.13.1-bin.tar.gz -C /opt/modules/
3.修改hive-log4j.properties配置文件
cd /opt/modules/hive-0.13.1-bin/conf
mv hive-log4j.properties.template hive-log4j.properties
vi hive-log4j.properties
#日志目录需要提前创建
hive.log.dir=/opt/modules/hive-0.13.1-bin/logs
4.修改hive-env.sh配置文件
mv hive-env.sh.template hive-env.sh
vi hive-env.sh
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
export HIVE_CONF_DIR=/opt/modules/hive-0.13.1-bin/conf
5.首先启动HDFS,然后创建Hive的目录
bin/hdfs dfs -mkdir -p /user/hive/warehouse
bin/hdfs dfs -chmod g+w /user/hive/warehouse
6.启动hive
./hive
#查看数据库
show databases;
#使用默认数据库
use default;
#查看表
show tables;
(六)Hive 与MySQL集成
1.在/opt/modules/hive-0.13.1-bin/conf目录下创建hive-site.xml文件,配置mysql元数据库。
vi hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata-pro01.kfk.com/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
2.设置用户连接
1)查看用户信息
mysql -uroot -p123456
show databases;
use mysql;
show tables;
select User,Host,Password from user;
2)更新用户信息
update user set Host='%' where User = 'root' and Host='localhost'
3)删除用户信息
delete from user where user='root' and host='127.0.0.1'
select User,Host,Password from user;
delete from user where host='localhost'
4)刷新信息
flush privileges;
3.拷贝mysql驱动包到hive的lib目录下
cp mysql-connector-java-5.1.27.jar /opt/modules/hive-0.13.1/lib/
4.保证第三台集群到其他节点无秘钥登录
(七)Hive 服务启动与测试
1.启动HDFS和YARN服务
2.启动hive
./hive
3.通过hive服务创建表
CREATE TABLE stu(id INT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
4.创建数据文件
vi /opt/datas/stu.txt
00001 zhangsan
00002 lisi
00003 wangwu
00004 zhaoliu
5.加载数据到hive表中
load data local inpath '/opt/datas/stu.txt' into table stu;
(八)Hive与HBase集成
1.在hive-site.xml文件中配置Zookeeper,hive通过这个参数去连接HBase集群。
<property>
<name>hbase.zookeeper.quorum</name> <value>bigdata-pro01.kfk.com,bigdata-pro02.kfk.com,bigdata-pro03.kfk.com</value>
</property>
2.将hbase的9个包拷贝到hive/lib目录下。如果是CDH版本,已经集成好不需要导包。

3.创建与HBase集成的Hive的外部表
create external table weblogs(id string,datatime string,userid string,searchname string,retorder string,cliorder string,cliurl string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,info:datatime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl") TBLPROPERTIES("hbase.table.name" = "weblogs");
#查看hbase数据记录
select count(*) from weblogs;
4.hive 中beeline和hiveserver2的使用
1)启动hiveserver2
bin/hiveserver2
2)启动beeline
bin/beeline
#连接hive2服务
!connect jdbc:hive2//bigdata-pro03.kfk.com:10000
#查看表
show tables;
#查看前10条数据
select * from weblogs limit 10;
新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析的更多相关文章
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——9、Flume+HBase+Kafka集成与开发
1.下载Flume源码并导入Idea开发工具 1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压 2)通过idea导入flume源码 打开idea开发工具,选择File ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
随机推荐
- ASA-有关AAA用户登录的问题
问题示例:I have created a test user that is set to privilege 15 in the config: When I log in to the ASA ...
- ECMAScript 6 和数组的新功能
Array. @@iterator 返回一个包含数组键值对的迭代器对象,可以通过同步调用得到数组元素的键值对 copyWithin 复制数组中一系列元素到同一数组指定的起始位置 entries 返回包 ...
- 【原】rsync使用
在使用jenkins当跳板机的场景下,有使用git pull 代码到jenkins机器后,需要将代码复制到另一台机器上,常用的复制命令有scp和rsync:现就使用到了rsync进行详解: rsync ...
- Update(Stage4):sparksql:第1节 SparkSQL_使用场景_优化器_Dataset & 第2节 SparkSQL读写_hive_mysql_案例
目标 SparkSQL 是什么 SparkSQL 如何使用 Table of Contents 1. SparkSQL 是什么 1.1. SparkSQL 的出现契机 1.2. SparkSQL 的适 ...
- PhpStorm For Mac 安装使用及 Php 开发的 ‘Hello World’
PHP全称为:Hypertext Preprocessor,中文名为:『超文本预处理 器』是一种通用开源脚本语言,主要用于Web应用开发(俗称做网站或 者做后台!) 编译软件:PHPStorm for ...
- 线程池三种队列使用,SynchronousQueue,LinkedBlockingQueue,ArrayBlockingQueue
使用方法: private static ExecutorService cachedThreadPool = new ThreadPoolExecutor(4, Runtime.getRuntime ...
- 解决 Anaconda 3.7更新出现CondaHTTPError与SSLError
1.问题描述: An HTTP error occurred when trying to retrieve this URL. HTTP errors are often intermittent, ...
- letter-spacing 与 word-spacing 结合使用,造成文字反转
文字未反转时,如图: 文字反转时,如图: 以上效果只是因为发现记录下来,目前并无实用,也许未来用得着它.
- 女神说拍了一套写真集想弄成素描画?很简单,用Python就行了!
素描作为一种近乎完美的表现手法有其独特的魅力,随着数字技术的发展,素描早已不再是专业绘画师的专利,今天这篇文章就来讲一讲如何使用python批量获取小姐姐素描画像.文章共分两部分: 第一部分介绍两种使 ...
- 操作系统OS - fork bomb(Windows)
1. Type %0|%0 2. Save the file to your desktop as anything.bat