Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上)
- 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cookie和session机制
Python爬虫爬取登录后的页面
所以怎样让爬虫使用验证用户身份信息的cookie呢,换句话说,怎样在使用爬虫的时候爬取已经登录的页面呢,这就是本篇的重点
cookie和session介绍
- cookie是发给用户的(即http浏览器)的一段信息
- session是保存在服务器上的对应的另一半信息,用来记录记录用户信息
- cookie和session区别和联系:
- 1.存放位置不同:cookie保存在本地,session保存在服务器
- 2.cookie不安全
- 为什么不安全,因为cookie是保存在本地的,也就是说用户可以就本地找到后进行修改
- 所以一般用来存放用户身份信息,常用来识别用户身份,比如用户名+登录密码(站点也就不怕被修改了)
- 当我们关闭浏览器后,再次打开一些网站,不用再次登录,也正是因为使用了保存在本地浏览器的cookie
- 3.session会保存在服务器上有过期时间,cookie也有
- 4.单个cookie保存数据不超过4k,部分浏览器会限制一个站点最多保存20个
- 5.session保存在服务器
- 一般情况下,session是放在内存中或者数据库中
使用cookie登录的网站
例如人人网:
第一步:Chrome打开登录
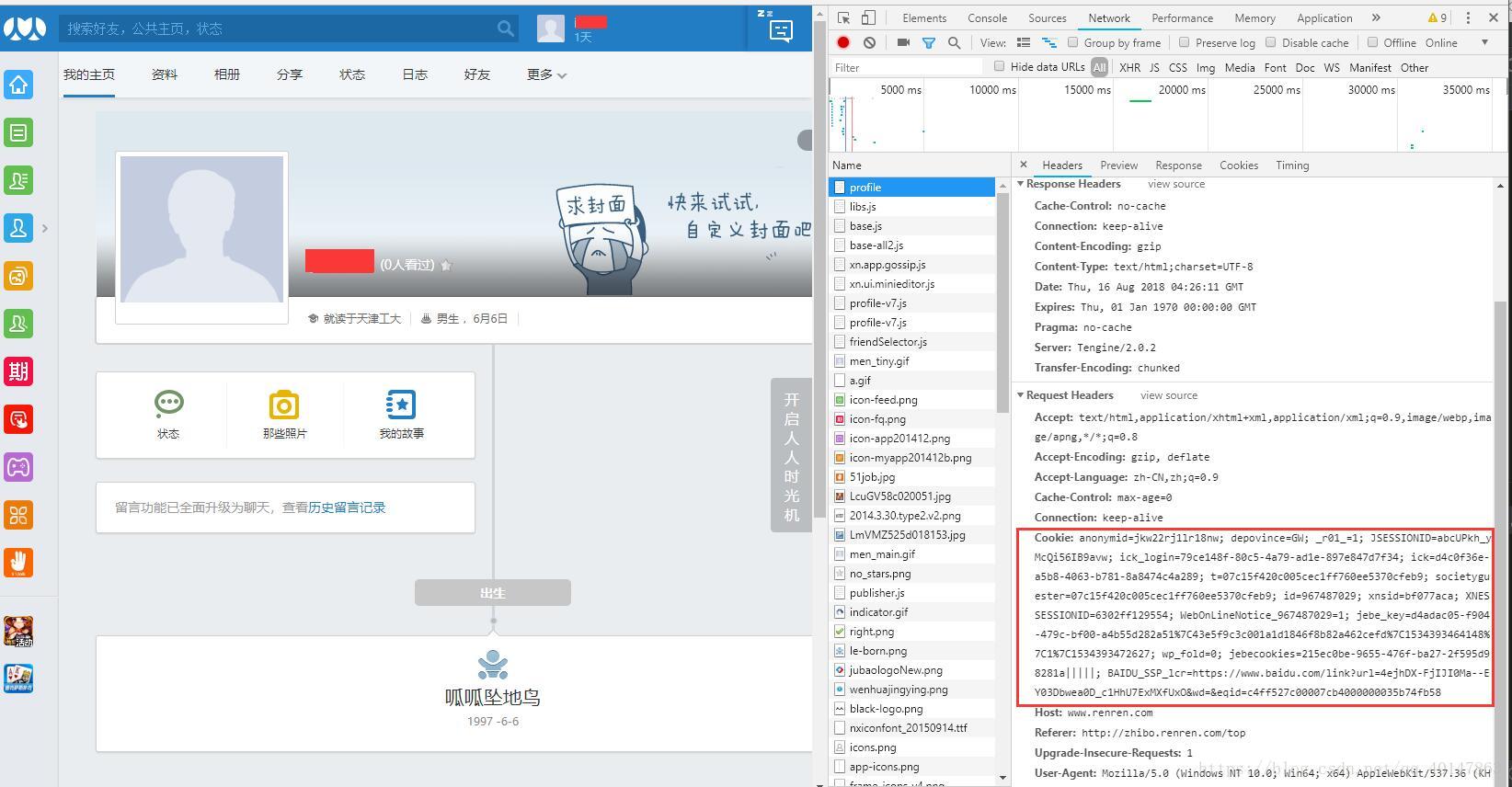
第二步:拷贝Chrome登录后的地址,使用火狐浏览器打开
这可以看到报错302
原因就是火狐浏览器的cookie和Chrome保存的cookie不一样,站点判断用户身份改变,所以不允许登录,另一方面,也就说明我们使用 cookie 验证身份是成功的
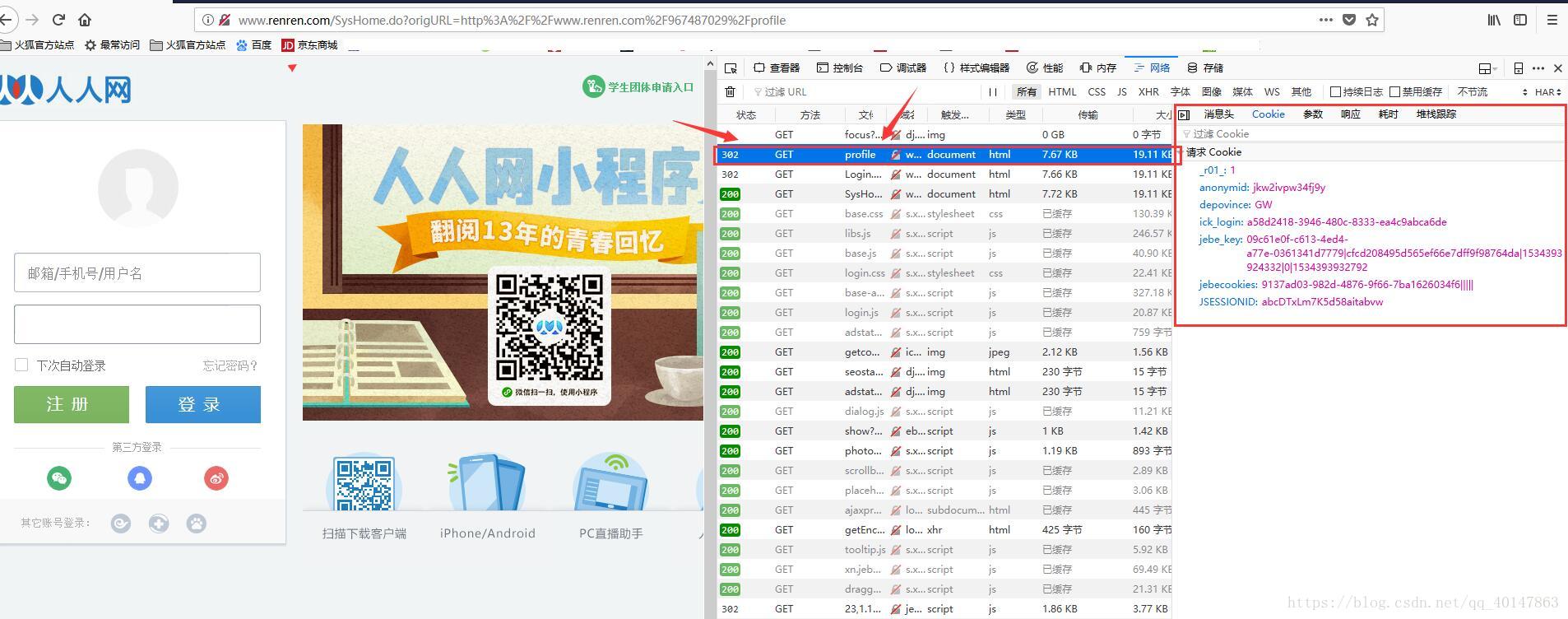
主角登场-爬虫使用cookie
既然其他浏览器不能直接访问网站,我们的爬虫就更不能了,所以怎样让爬虫使用验证用户身份信息的cookie呢?马上揭晓:
编写爬虫代码
- 案例v12cookie2文件:https://xpwi.github.io/py/py爬虫/py12cookie2.py
- 想要未使用cookie的对照案例,可以直接下载:
案例v12cookie1文件:https://xpwi.github.io/py/py爬虫/py12cookie1.py
# 爬虫使用cookie
from urllib import request
if __name__ == '__main__':
url = "http://www.renren.com/967487029/profile"
headers = {
# Cookie值从登录后的浏览器,拷贝,方法文章上面有介绍
"Cookie": "anonymid=jkw22rj1lr18nw; depovince=GW; _r01_=1; JSESSIONID=abcUPkh_yMcQi56IB9avw; ick_login=79ce148f-80c5-4a79-ad1e-897e847d7f34; ick=d4c0f36e-a5b8-4063-b781-8a8474c4a289; t=07c15f420c005cec1ff760ee5370cfeb9; societyguester=07c15f420c005cec1ff760ee5370cfeb9; id=967487029; xnsid=bf077aca; XNESSESSIONID=6302ff129554; BAIDU_SSP_lcr=https://www.baidu.com/link?url=4ejhDX-FjIJI0Ma--EY03Dbwea0D_c1HhU7ExMXfUxO&wd=&eqid=c4ff527c00007cb4000000035b74fb58; wp_fold=0; jebe_key=d4adac05-f904-479c-bf00-a4b55d282a51%7C43e5f9c3c001a1d1846f8b82a462cefd%7C1534398658919%7C1; jebecookies=6031f512-d289-4dff-b1d6-aaa7849bd1ff|||||"
}
req = request.Request(url=url,headers=headers)
rsp = request.urlopen(req)
html = rsp.read().decode()
with open("rsp.html","w",encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
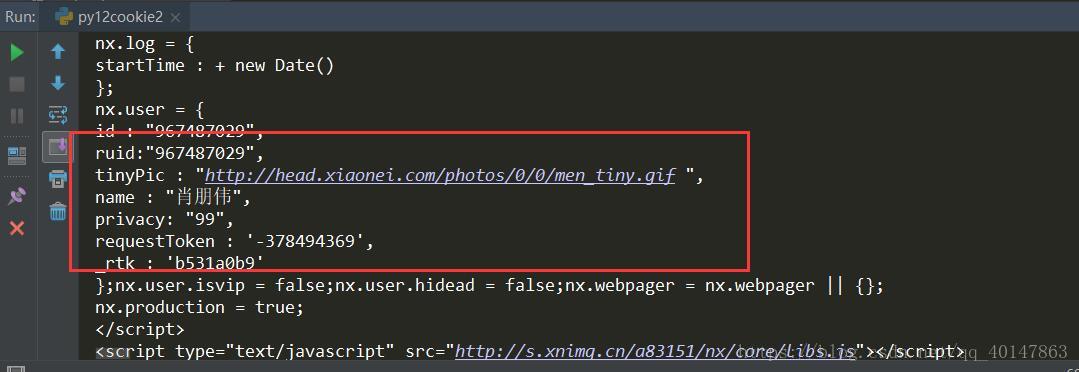
运行结果
现在我们可以在返回的html页面看到自己的登录信息了,也就说明cookie使用成功了
今天介绍的是手动拷贝cookie,后面会介绍如何自动的使用!
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)的更多相关文章
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
随机推荐
- hdu1466计算直线的交点数 非原创
原文链接 平面上有n条直线,且无三线共点,问这些直线能有多少种不同交点数. 比如,如果n=2,则可能的交点数量为0(平行)或者1(不平行). Input输入数据包含多个测试实例,每个测试实例占一行,每 ...
- [转] Gitlab 8.x runner安装与配置
[From]http://muchstudy.com/2018/07/13/Gitlab-8-x-runner%E5%AE%89%E8%A3%85%E4%B8%8E%E9%85%8D%E7%BD%AE ...
- confiparser模块
什么是confiparser confiparser,翻译为配置解析,很显然,他是用来解析配置文件的, 何为配置文件? 用于编写程序的配置信息的文件 何为配置信息? 为了提高程序的扩展性,我们会把一些 ...
- golang笔记
----------- golang打包和部署到centos7. 参考:https://blog.csdn.net/qq_33230584/article/details/81536572
- 【测试的艺术】+测试分析&测试计划+模板
一.项目概述 1.1.项目背景 #就是说一下为什么要做这个项目 1.2.项目目标 #这个项目最终要达到的目标是什么 二.项目整体分析 #项目分为哪些部分?各部分之间的关联是什么?各部分的目标是什么? ...
- HBase启动时IP地址解析不正确的问题及解决方法
HBase启动时遇到IP地址解析不正确,连不上Regionserver , 配置文件上写的 192.168.100.28, 错误信息 Problem binding to /202.102.110. ...
- js中报错"Maximum call stack size exceeded"解决方法
Uncaught RangeError: Maximum call stack size exceeded 错误直译过来就是“栈溢出”,出现这个错误的原因是因为我进行了递归运算,但是忘记添加判断条件, ...
- Android可见APP的不可见任务栈(TaskRecord)销毁分析
Android依托Java型虚拟机,OOM是经常遇到的问题,那么在快达到OOM的时候,系统难道不能回收部分界面来达到缩减开支的目的码?在系统内存不足的情况下,可以通过AMS及LowMemoryKill ...
- linux磁盘分区fdisk命令详解
1.什么是分区? 分区是将一个硬盘驱动器分成若干个逻辑驱动器,分区是把硬盘连续的区块当做一个独立的磁硬使用.分区表是一个硬盘分区的索引,分区的信息都会写进分区表.2.为什么要有多个分区? 防止数 ...
- Robot Framework(Collections 库)
Collections 库 Collections 库同样为Robot Framework 标准类库,它所提供的关键字主要用于列表.索引.字典的处理. 在使用之前需要在测试套件(项目)中添加: