SparkStreaming和Kafka的整合
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。需要满足以下几个先决条件:
1、输入的数据来自可靠的数据源和可靠的接收器;
2、应用程序的metadata被application的driver持久化了(checkpointed );
3、启用了WAL特性(Write ahead log)。
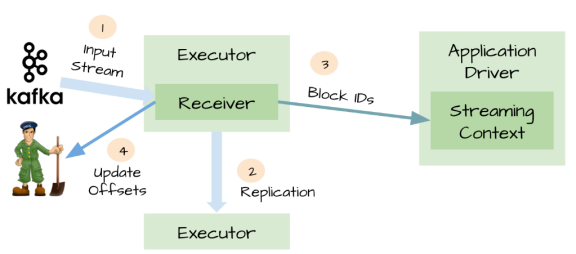
1. 可靠的数据源和可靠的接收器
可以从接收器挂掉的情况下恢复(或者是接收器运行的Exectuor和服务器挂掉都可以)
对于一些输入数据源(比如Kafka),Spark Streaming可以对已经接收的数据进行确认。输入的数据首先被接收器(receivers )所接收,
然后存储到Spark中(默认情况下,数据保存到2个执行器中以便进行容错)。数据一旦存储到Spark中,接收器可以对它进行确认
(比如,如果消费Kafka里面的数据时可以更新Zookeeper里面的偏移量)。
这种机制保证了在接收器突然挂掉的情况下也不会丢失数据:
因为数据虽然被接收,但是没有被持久化的情况下是不会发送确认消息的。所以在接收器恢复的时候,数据可以被原端重新发送。
2. 元数据持久化(Metadata checkpointing)
对应用程序的元数据进行Checkpint,Driver可以将应用程序的重要元数据持久化到可靠的存储中(如HDFS)
然后Driver可以利用这些持久化的数据进行恢复。元数据包括:
1、配置;
2、代码;
3、那些在队列中还没有处理的batch(仅仅保存元数据,而不是这些batch中的数据)
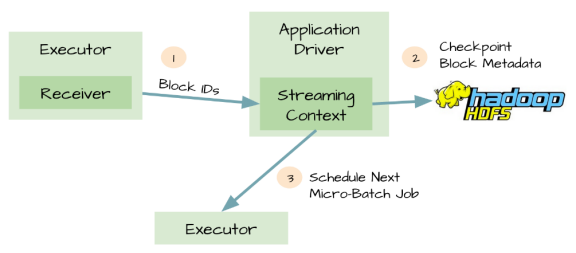
由于有了元数据的Checkpint,所以Driver可以利用他们重构应用程序,而且可以计算出Driver挂掉的时候应用程序执行到什么位置。
3. 可能存在数据丢失的场景
1、两个Exectuor已经从接收器中接收到输入数据,并将它缓存到Exectuor的内存中;
2、接收器通知输入源数据已经接收;
3、Exectuor根据应用程序的代码开始处理已经缓存的数据;
4、这时候Driver突然挂掉了;
5、从设计的角度看,一旦Driver挂掉之后,它维护的Exectuor也将全部被kill;
6、既然所有的Exectuor被kill了,所以缓存到它们内存中的数据也将被丢失。结果,这些已经通知数据源但是还没有处理的缓存数据就丢失了;
7、缓存的时候不可能恢复,因为它们是缓存在Exectuor的内存中,所以数据被丢失了。
4.WAL(Write ahead log)
针对上面情况,Spark Streaming 1.2开始引入了WAL机制。
启用了WAL机制,所以已经接收的数据被接收器写入到容错存储中(如HDFS),Driver可以从失败的点重新读取数据,即使Exectuor中内存的数据已经丢失了
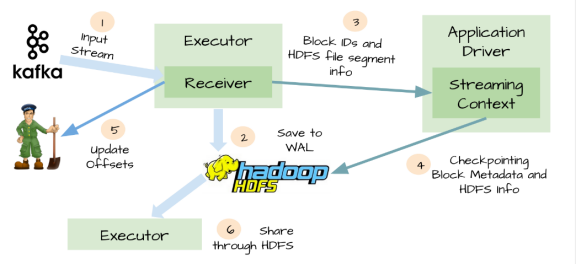
WAL虽然可以办证数据不丢失,但不能保证对数据源exactly-once语义,只读一次数据:
接收器接收数据并存储在WAL中,开始消费数据,在接收器向zookeeper更新偏移量之前,Executor挂掉了,
等Executor恢复会重新读取那些保存到WAL中但未被消费的数据,当从WAL读取完数据后,又开始消费数据,
因为接收器是采用Kafka的High-Level Consumer API实现的,它开始从Zookeeper当前记录的偏移量开始读取数据,
由于Zookeeper的偏移量没有更新,所以有些数据回被重复消费
WAL的缺点:
1、WAL减少了接收器的吞吐量,因为接受到的数据必须保存到可靠的分布式文件系统中。
2、对于一些输入源来说,它会重复相同的数据。比如当从Kafka中读取数据,你需要在Kafka的brokers中保存一份数据,而且你还得在Spark Streaming中保存一份。
5. Kafka direct API
为了解决由WAL引入的性能损失,并且保证 exactly-once 语义,Spark Streaming 1.3中引入了名为Kafka direct API。
Spark driver只需要简单地计算下一个batch需要处理Kafka中偏移量的范围,然后命令Spark Exectuor直接从Kafka相应Topic的分区中消费数据。
换句话说,这种方法把Kafka当作成一个文件系统,然后像读文件一样来消费Topic中的数据。
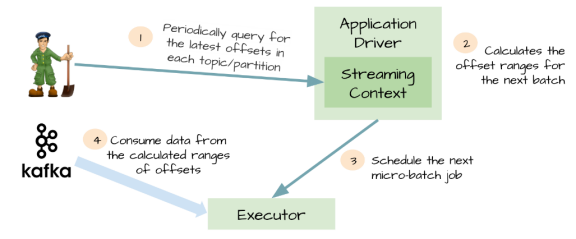
优点:
1、不再需要Kafka接收器,Exectuor直接采用Simple Consumer API从Kafka中消费数据。
2、不再需要WAL机制,我们仍然可以从失败恢复之后从Kafka中重新消费数据;
3、exactly-once语义得以保存,我们不再从WAL中读取重复的数据。
SparkStreaming和Kafka的整合的更多相关文章
- 图解SparkStreaming与Kafka的整合,这些细节大家要注意!
前言 老刘是一名即将找工作的研二学生,写博客一方面是复习总结大数据开发的知识点,一方面是希望帮助更多自学的小伙伴.由于老刘是自学大数据开发,肯定会存在一些不足,还希望大家能够批评指正,让我们一起进步! ...
- 【Spark】SparkStreaming和Kafka的整合
文章目录 Streaming和Kafka整合 概述 使用0.8版本下Receiver DStream接收数据进行消费 步骤 一.启动Kafka集群 二.创建maven工程,导入jar包 三.创建一个k ...
- SparkStreaming和Kafka基于Direct Approach如何管理offset实现exactly once
在之前的文章<解析SparkStreaming和Kafka集成的两种方式>中已详细介绍SparkStreaming和Kafka集成主要有Receiver based Approach和Di ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- Flume+Kafka+Storm整合
Flume+Kafka+Storm整合 1. 需求: 有一个客户端Client可以产生日志信息,我们需要通过Flume获取日志信息,再把该日志信息放入到Kafka的一个Topic:flume-to-k ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- sparkStreaming 读kafka的数据
目标:sparkStreaming每2s中读取一次kafka中的数据,进行单词计数. topic:topic1 broker list:192.168.1.126:9092,192.168.1.127 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- 第1节 kafka消息队列:10、flume与kafka的整合使用
11.flume与kafka的整合 实现flume监控某个目录下面的所有文件,然后将文件收集发送到kafka消息系统中 第一步:flume下载地址 http://archive.cloudera.co ...
随机推荐
- MySQL JOIN | 联结
联结是利用SQL的SELECT能执行的最重要的操作.为了提高存储的有效性和避免数据冗余,往往会将有关联的数据存储在好几张表中,那么怎样用一条SELECT语句就能检索出这些数据呢? 答案是JOIN(联结 ...
- C# Dictionary的遍历
foreach (KeyValuePair<string, string> kvp in dic) { Console.WriteLine("key:{0},value:{1}& ...
- Android应用瘦身
转:https://zhuanlan.zhihu.com/p/25465537 瘦身的目的 从目的导向来看,我们是不会无缘无故去做一件事情的,那我们对应用瘦身的目的是为了什么?答案是:提高下载转化率. ...
- ionic 2 起航 控件的使用 客户列表场景(三)
我们来看看客户列表的搜索控件是怎么工作的吧. 1.打开customer.html <ion-content> <ion-searchbar [(ngModel)]="sea ...
- amap -bq 192.168.5.9 80 3306
amap -bq 192.168.5.9 80 3306 查看运行在指定端口上运行的服务
- 解决“SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' 的 STATEMENT 'OpenRowset/OpenDatasource' 的访问……”【转】
SQL Server 阻止了对组件 /'Ad Hoc Distributed Queries/' 的访问 在Sql Server中查询一下Excel文件的时候出现问题: SELECT * FROM ...
- WIN7 64位对Excel操作异常
在本地做Excel导出功能的测试时,报出“检索COM 类工厂中CLSID 为 {00024500-0000-0000-C000-000000000046}的组件时失败”的异常,知道要对Excel进行D ...
- Codeforces 744A. Hongcow Builds A Nation
A. Hongcow Builds A Nation 题意: 现在有 n 个点 ,m 条边组成了一个无向图 , 其中有 k 个特殊点, 这些特殊点之间不能连通 ,问可以再多加几条边? 因为$x^2+y ...
- SVN和Git的区别
这个地方就简单介绍一下 svn 的模式是: 1.写代码. 2.从服务器拉回服务器的当前版本库,并解决服务器版本库与本地代码的冲突. 3.将本地代码提交到服务器. Git分布式版本管理的模式是: 1.写 ...
- 手把手教你用Docker部署一个MongoDB集群
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中最像关系数据库的.支持类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引 ...