HUE配置文件hue.ini 的filebrowser模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货!
我的集群机器情况是 bigdatamaster(192.168.80.10)、bigdataslave1(192.168.80.11)和bigdataslave2(192.168.80.12)
然后,安装目录是在/home/hadoop/app下。
官方建议在master机器上安装Hue,我这里也不例外。安装在bigdatamaster机器上。
Hue版本:hue-3.9.0-cdh5.5.4
需要编译才能使用(联网) 说给大家的话:大家电脑的配置好的话,一定要安装cloudera manager。毕竟是一家人的。
同时,我也亲身经历过,会有部分组件版本出现问题安装起来要个大半天时间去排除,做好心里准备。废话不多说,因为我目前读研,自己笔记本电脑最大8G,只能玩手动来练手。
纯粹是为了给身边没高配且条件有限的学生党看的! 但我已经在实验室机器群里搭建好cloudera manager 以及 ambari都有。
大数据领域两大最主流集群管理工具Ambari和Cloudera Manger
Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
Hue提供了图形化截面管理HDFS数据,可谓之非常方便,但是在配置上,还是有点麻烦的。
说明:对于这个filebrowser模块啊,网上有些资料是对pseudo-distributed.ini进行配置,也有些资料对hue.ini进行配置。其实本质都是一样哈!
有些Hue的版本里是没有前者。比如我的版本是直接下载hue-3.9.0-cdh5.5.4.tar.gz,然后进行编译得到。
这个问题没事。只需要对其中一个配置文件进行修改即可。
一、以下是默认的配置文件
二、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的filebrowser模块)
也就说,非HA集群的话,仅需要配置WebHdfs
即,即要在$HADOOP_HOME/etc/hadoop下,配置好hdfs-site.xml 和 core-site.xml
在core-site.xml 和 hdfs-site.xml下,添加如下

core-site.xml下

<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
hdfs-site.xml下
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
[filebrowser]模块总的是如下
###########################################################################
# Settings to configure the Filebrowser app
########################################################################### [filebrowser]
# Location on local filesystem where the uploaded archives are temporary stored.
archive_upload_tempdir=/tmp # Show Download Button for HDFS file browser.
## show_download_button=false # Show Upload Button for HDFS file browser.
## show_upload_button=false
三、以下是跟我机器集群匹配的配置文件(HA集群下怎么配置Hue的filebrowser模块)
也就说,HA集群的话,不仅需要配置WebHdfs,还要配置httpfs。
即,即要在$HADOOP_HOME/etc/hadoop下,配置好hdfs-site.xml 和 core-site.xml,还要配置好 httpfs-site.xml 。
注意,在hdfs_clusters模块里,若要配置HA的话,则必须是要用到HttpFs。请看Hue的官网配置例子
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.4/manual.html#_install_hue
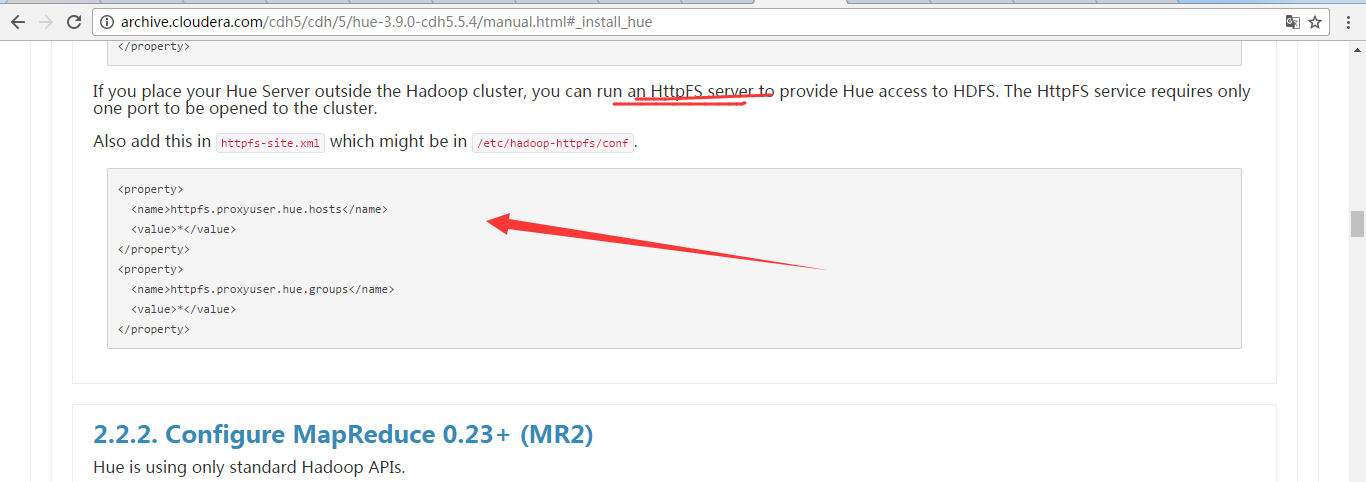
注意: 在$HADOOP_HOME/etc/hadoop/下的httpfs-site.xml。(djt11、djt12、djt12、djt14和djt15都需要配置)
先配置好如下
<property>
<name>httpfs.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>httpfs.proxyuser.hue.groups</name>
<value>*</value>
</property>
同时,还要配置WebHdfs,别忘记啦!
在core-site.xml 和 hdfs-site.xml下,添加如下
core-site.xml下
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
hdfs-site.xml下
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
然后,配置
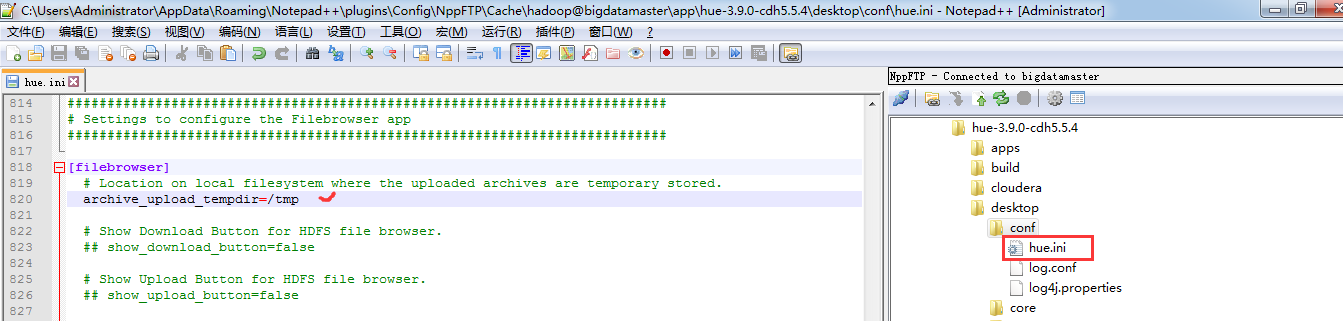
[filebrowser]模块总的是如下
###########################################################################
# Settings to configure the Filebrowser app
########################################################################### [filebrowser]
# Location on local filesystem where the uploaded archives are temporary stored.
archive_upload_tempdir=/tmp # Show Download Button for HDFS file browser.
## show_download_button=false # Show Upload Button for HDFS file browser.
## show_upload_button=false
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



HUE配置文件hue.ini 的filebrowser模块详解(图文详解)(分HA集群和非HA集群)的更多相关文章
- HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的yarn_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hbase模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的impala模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hive和beeswax模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的zookeeper模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的pig模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 一.默认的pig配置文件 ########################################################################### ...
- HUE配置文件hue.ini 的liboozie和oozie模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
随机推荐
- keepalive安装配置
安装 Centos7.4 yum install keepalived 配置 Master服务器配置 [root@wsjy-proxy01 keepalived]# cat keepalived.co ...
- mven系列问题
1.前言 Maven,发音是[`meivin],"专家"的意思.它是一个很好的项目管理工具,很早就进入了我的必备工具行列,但是这次为了把 project1项目完全迁移并应用mave ...
- 关于Jwt的一些思考
在使用jwt的过程中发现了两个问题续期和退出的问题. 续期 因为jwt的token在签发之后是有过期时间的,所以就存在管理这个过期时间的问题.我看网上有提出解决方案的大致有下面几个 每次更新过期时间, ...
- vue项目打包后想发布在apache www/vue 目录下
使用的是vue-element-admin做示例,可以参考Vue项目根据不同运行环境打包项目,其他项目应该大同小异. 使用vue-router的browserHistory模式,配置mode: 'hi ...
- bzoj 1040 1040: [ZJOI2008]骑士
1040: [ZJOI2008]骑士 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 5210 Solved: 1987[Submit][Status ...
- IOS开发的哪些异常之异常断点
从Android开发的异常报错到IOS的异常闪退,经历了不一样的处理过程.对于IOS的异常报错刚開始总是非常茫然,永远仅仅告诉你有异常.然后就跳到main.m文件,却不曾我告诉她在那出现.真是吊人胃口 ...
- QUERY_REWRITE_ENABLED
官方文档中: QUERY_REWRITE_ENABLED Property Description Parameter type String Syntax QUERY_REWRITE_ENABLED ...
- Linux安装PHP MongoDB扩展
本文将讲述一下本人安装MongoDB扩展的过程,大家可以略作参考 安装环境 Linux环境:CentOS 6.5 Apache版本:2.4 PHP版本:5.4.3 MongoDB版本:2.6.5 一. ...
- The evolution of cluster scheduler architectures--转
原文地址:http://www.firmament.io/blog/scheduler-architectures.html cluster schedulers are an important c ...
- Nordic Collegiate Programming Contest 2015(第七场)
A:Adjoin the Networks One day your boss explains to you that he has a bunch of computer networks tha ...