Python爬虫从入门到放弃(十)之 关于深度优先和广度优先
- 网站的树结构
- 深度优先算法和实现
- 广度优先算法和实现
网站的树结构
通过伯乐在线网站为例子:
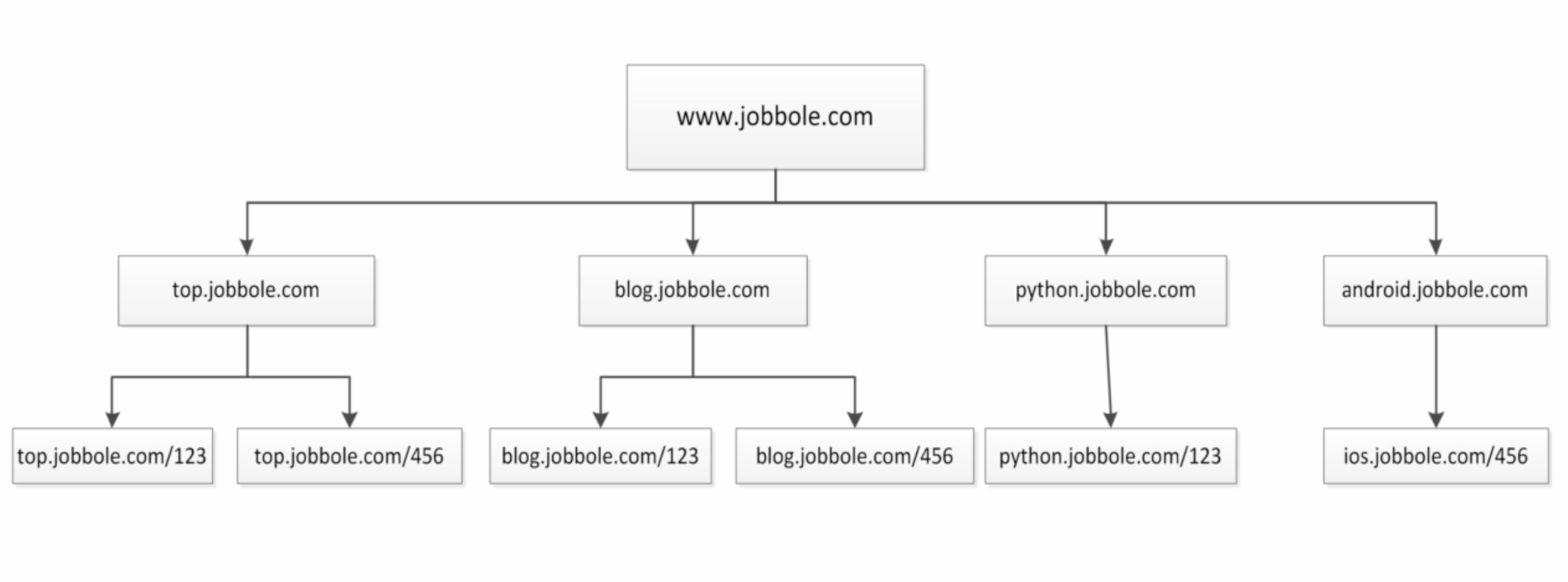
并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据的时候就会涉及到去重的问题,我们需要将爬过的url记录下来,我们将上图进行更改

在爬虫系统中,待抓取URL队列是很重要的一部分,待抓取URL队列中的URL以什么样的顺序排队列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面是常用的两种策略:深度优先、广度优先
深度优先
深度优先是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接,通过下图进行理解:
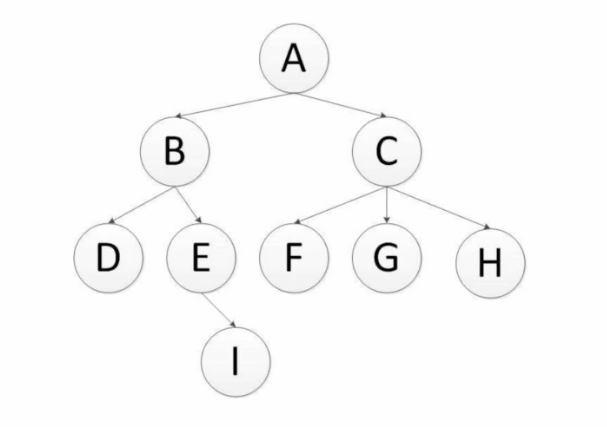
这里是深度优先,所以这里的爬取的顺序式:
A-B-D-E-I-C-F-G-H (递归实现)
深度优先算法的实现(伪代码):

广度优先
广度优先,有人也叫宽度优先,是指将新下载网页发现的链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续抓取在此网页中链接的所有网页,通过下图进行理解:

还是以这个图为例子,广度优先的爬取顺序为:
A-B-C-D-E-F-G-H-I (队列实现)
广度优先代码的实现(伪代码):

Python爬虫从入门到放弃(十)之 关于深度优先和广度优先的更多相关文章
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
随机推荐
- 四、I/O
九.什么是I/O: 9.1.在Windows程序中,基础的运行单位为线程,为每一个线程分配一个处理器,可以让系统执行多个操作, 9.2.当线程进行一个I/O操作时,会被挂起,从而影响性能,为了解决这类 ...
- PHP获得上(两)周时间
就不手写了
- 智能指针剖析(上)std::auto_ptr与boost::scoped_ptr
1. 引入 C++语言中的动态内存分配没有自动回收机制,动态开辟的空间需要用户自己来维护,在出函数作用域或者程序正常退出前必须释放掉. 即程序员每次 new 出来的内存都要手动 delete,否则会造 ...
- eclipse中集成hadoop插件
1.下载并安装eclipse2.https://github.com/winghc/hadoop2x-eclipse-plugin3.下载插件到eclipse的插件目录 4.配置hadoop安装目录 ...
- Centos7通过Docker安装Sentry(哨兵)
Docker介绍 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制, ...
- [刷题]算法竞赛入门经典(第2版) 4-4/UVa253 - Cube painting
书上具体所有题目:http://pan.baidu.com/s/1hssH0KO 代码:(Accepted,0 ms) #include<iostream> char str[15]; v ...
- 基于express+mongodb+pug的博客系统——pug篇
很久之前就想自己搭一个博客了,最开始用hexo+github,但是换电脑后总是有些麻烦.后来使用WordPress,但是用WordPress总觉得没什么技术含量,前后端都是人家写好的,而且买的垃圾虚拟 ...
- SpringAOP原理
原理 AOP(Aspect Oriented Programming),也就是面向方面编程的技术.AOP基于IoC基础,是对OOP的有益补充.AOP将应用系统分为两部分,核心业务逻辑(Core bus ...
- java关键字transient与volatile小结
本文转自:http://heaven-arch.iteye.com/blog/1160693 transient和volatile两个关键字一个用于对象序列化,一个用于线程同步,都是Java中比较高阶 ...
- 分布式Java应用与实践 (一)
一) 分布式Java应用 1.1 基于消息方式实现系统间的通信 数据传输 TCP/IP 可靠的网络传输协议,首先给通信双方建立链接之后再进行数据传输,保证链接及数据传输的可靠,因此会牺牲一些性能 UD ...