scrapy-splash抓取动态数据例子九
一、介绍
本例子用scrapy-splash抓取众视网网站给定关键字抓取咨询信息。
给定关键字:个性化;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
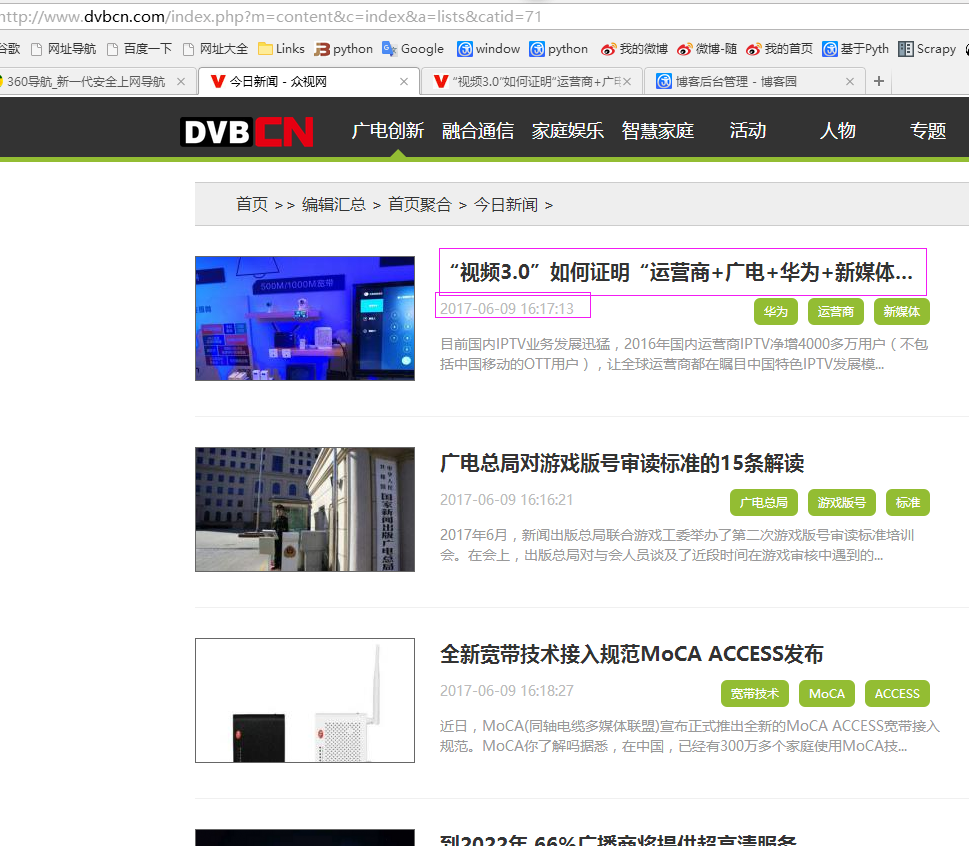


三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:sels = site.xpath('//div[@class="topic overfl"]')
2、抓取标题
抓取代码:title = sel.xpath('.//div[@class="info"]/h3/a/text()')[0].extract()
3、抓取链接
抓取代码:url = 'http://www.dvbcn.com' + str(sel.xpath('.//div[@class="info"]/h3/a/@href')[0].extract())
4、抓取日期
抓取代码:strdate = sel.xpath('.//span[@class="time"]/text()')[0].extract()
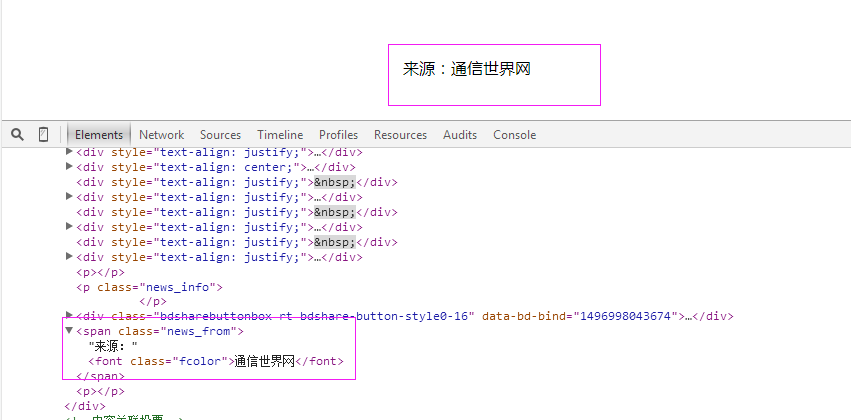
5、抓取来源
抓取代码:sources = site.xpath('//span[@class="news_from"]/font/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class dvbcnSpider(Spider):
name = 'dvbcn' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_wordlist = cf.GetValue("section", "information_keywords").split(';')
websearch_urls = cf.GetValue("dvbcn", "websearchurl").split(';')
start_urls = []
for url in websearch_urls:
print url
start_urls.append(url) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url
, self.parse
, args={'wait': ''}
) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate,strDate[0])==0:
return True,currentDate
return False, ''
def parse(self, response): site = Selector(response)
sels = site.xpath('//div[@class="topic overfl"]')
for sel in sels:
strdate = sel.xpath('.//span[@class="time"]/text()')[0].extract()
flag, date = self.date_isValid(strdate)
if flag:
title = sel.xpath('.//div[@class="info"]/h3/a/text()')[0].extract()
url = 'http://www.dvbcn.com' + str(sel.xpath('.//div[@class="info"]/h3/a/@href')[0].extract()) for keyword in self.information_wordlist:
if title.find(keyword) > -1:
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword, 'title': title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//span[@class="news_from"]/font/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
return it
scrapy-splash抓取动态数据例子九的更多相关文章
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
随机推荐
- 网络知识===cookie 、session、JSESSIONID的区别
cookie .session ? 让我们用几个例子来描述一下cookie和session机制之间的区别与联系.笔者曾经常去的一家咖啡店有喝5杯咖啡免费赠一杯咖啡的优惠,然而一次性消费5杯咖啡的机会微 ...
- 肢解 HTTP 服务器构建
更好阅读请戳 这里 1. 最简单的 http 服务器 // server.js var http = require("http"); http.createServer(func ...
- jQuery中操作事件
JavaScript中操作事件的方式是这样的: 元素.on事件名=function(){ //事件执行的代码 } 但是jQuery有点不同,他的格式是这样的: 元素.on("事件名" ...
- redis发布订阅、HyperLogLog与GEO功能的介绍
一.发布订阅 1.模型 发布者发布消息,订阅者接收消息 2.API 2.1.publish 2.2.订阅 2.3.取消订阅 unsubsribe 2.4.其他api 二.HyperLogLog 极小空 ...
- 超越IEtab、网银支付助手,无需再次登陆的Firefox的IE插件
强烈推荐! fire-ie最大亮点就是:可以传递firefox下的cookie,从而避免了再次登陆或打开支付页面的繁琐. 在线安装:https://addons.mozilla.org/zh-CN/f ...
- [orangehrm] 安装问题集合
Web server allows .htaccess files # 这一项检查不通过 解决: In conf/extra/httpd-vhosts.conf, add the line Allow ...
- POJ 1321 棋盘问题【DFS/回溯/放与不放/类似n皇后】
棋盘问题 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 62164 Accepted: 29754 Description 在一 ...
- ZCMU新人训练赛-B
Tom's Meadow Tom has a meadow in his garden. He divides it into N * M squares. Initially all the sq ...
- Codeforces #447 Div2 D
#447 Div2 D 题意 给一棵完全二叉树,每条边有权值为两点间的距离,每次询问 \(x, h\) ,从结点 \(x\) 出发到某一结点的最短路的距离 \(d\) 如果小于 \(h\) ,则答案加 ...
- Codeforces #430 Div2 C
#430 Div2 C 题意 给出一棵带点权的树,每一个节点的答案为从当前节点到根节点路径上所有节点权值的最大公因子(在求最大共因子的时候可以选择把这条路径上的任意一点的权值置为0).对于每一个节点单 ...