HDFS 读写流程-译
HDFS 文件读取流程
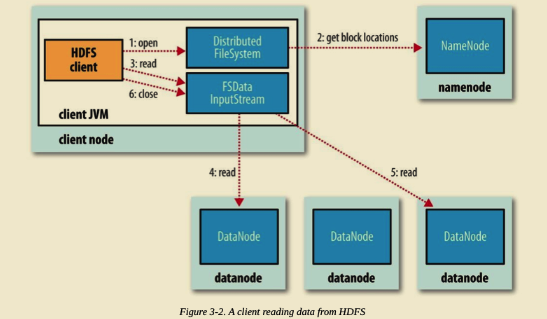
Client 端调用 DistributedFileSystem 对象的 open() 方法。
由 DistributedFileSystem 通过 RPC 向 NameNode 请求返回文件的 Block 块所在的 DataNode 的地址。(我们知道 HDFS 默认策略对某个 Block 会保存三份副本到不同的 DataNode,那么 NameNode 应该返回那个 DataNode?答案是根据 DataNode 到 Client 端的距离。假设请求的 Block 块刚好就落在 Client 端所在机器上,即 Client 端本身也是 DataNode,那么毫无疑问 DataNode 将会返回 Client 端所在机器地址。这也验证了 Hadoop 的一个设计特性,移动计算而不是移动数据,极大了减小了带宽。)
Client 端调用 FSDataInputStream 对象的 read() 方法,通过 FSDataInputStream 向 DataNode 获取 Block 数据。之后数据流源源不断地从 DataNode 返回至 Client。当最后一个 Block 返回至 Client 端后, DFSInputStream 会关闭与 DataNode 连接。上述过程对 Client 端都是透明的,从 Client 来看,它只是在不停的读取数据流。
如果 DFSInputStream 在读取的过程中发生了错误,将会尝试与存有该 Block 副本且距离最近的 DataNode 通信。同时,它会记录下出问题的 DataNode,在之后的数据请求过程中不再与之通信。并报告给 NameNode。DFSInputStream 具备检查数据校验和的功能。
HDFS 文件写入流程
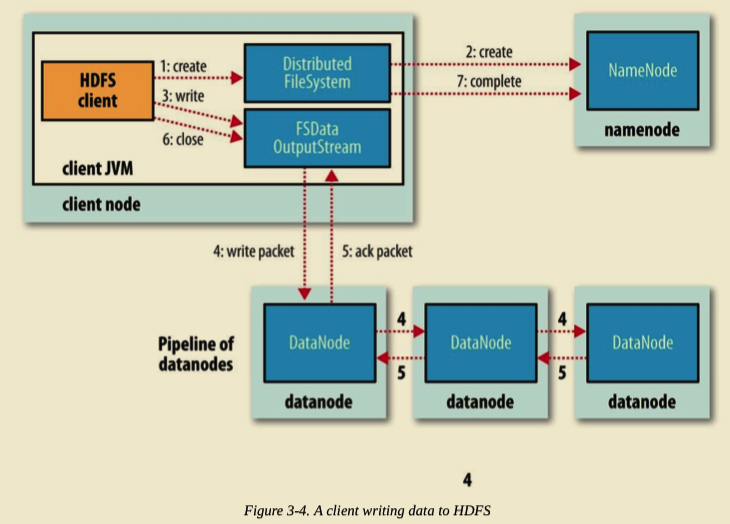
Client 写入文件时,调用 DistributedFileSystem 对象的 create() 方法。
DistributedFileSystem 通过 RPC 请求 NameNode 向其 NameSpace 写入文件元数据信息。NameNode 会做多种检查,如判断文件是否存在,是否有相应的写权限等等。如果检查通过,NameNode 会将文件元数据写入 NameSpace。DistributedFileSystem 将会返回 FSDataOutputStream 用于 Client 端直接向 DataNode 写入数据。
DFSOutputStream 将 Client 要写入的数据分割成 Packets。Packets 会被保存到 Data Queue 队列中,并由 DataStreamer 消费处理。DataStreamer 请求 NameNode 分配 DataNode 列表,将 Packets 写入到 DataNode 中。假设放置副本的默认策略是 3,那么 NameNode 将返回 3 个 DataNode,并串联起来组成一条 Pipeline。 DataStreamer 将 Packets 写入到第一个 DataNode1,DataNode1 存储完后直接转发至 DataNode2,DataNode2 存储完后再直接转发至 DataNode3。(注意,这里直接是 DataNode1 直接将 Packet 转发至 DataNode2。)
DFSOutputStream 为了防止出问题时数据的丢失,维持了一个等待 DataNode 成功写入的 ACK Queue。只有当 Packet 被成功写入 Pipeline 中的每个 DataNode 时,此 Packet 才会从 ACK Queue 中移除。
在 Pipeline 写入的过程中,如果某个 DataNode 出现问题,Pipeline 首先将会被关闭,随后在 ACK Queue 中的 Packets 会被添加到 Data Queue 的最前面,用来防止位于问题节点下游的 DataNode 写入时的数据丢失。出问题的 DataNode 会被从 Pipeline 中移除。NameNode 会重新分配一个健康的 DataNode 构成新的 Pipeline。
当 Client 端写完数据,调用 DFSOutputStream 对象的 close() 方法。该操作将会将所有剩余的 Packets 刷写到 DataNode Pipeline 并等待返回确认,之后向 NameNode 发送文件写入完成信号。
HDFS 读写流程-译的更多相关文章
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- HDFS读写流程(转载)
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现.特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性 ...
- 超详细的HDFS读写流程详解(最容易理解的方式)
HDFS采用的是master/slaves这种主从的结构模型管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端).Namenode(名称节点).Datanode(数据节点)和Seco ...
- Hadoop之HDFS读写流程
hadoophdfs 1. HDFS写流程 2. HDFS写流程 1. HDFS写流程 HDFS写流程 副本存放策略: 上传的数据块后,触发一个新的线程,进行存放. 第一个副本:与client最近的机 ...
- HDFS 读写流程-英
HDFS 文件读取流程 The client opens the file it wishes to read by calling open() on the FileSystem object, ...
- HDFS读写流程(重点)
@ 目录 一.写数据流程 举例: 二.异常写流程 读数据流程 一.写数据流程 ①服务端启动HDFS中的NN和DN进程 ②客户端创建一个分布式文件系统客户端,由客户端向NN发送请求,请求上传文件 ③NN ...
- HDFS读写流程learning
有许多对流程进行描述的博客,但是感觉还是应当学习一遍代码,不然总感觉怪怪的,https://blog.csdn.net/popsuper1982/article/details/51615285,首先 ...
- HDFS读写流程
01.并行读取 02.逐个节点写入
随机推荐
- 转载 vue-awesome-swiper - 基于vue实现h5滑动翻页效果
说到h5的翻页,很定第一时间想到的是swiper.但是我当时想到的却是,vue里边怎么用swiper?! 中国有句古话叫:天塌下来有个高的顶着. 在前端圈里,总有前仆后继的仁人志士相继挥洒着热汗(这里 ...
- CentOS 7.3下使用YUM 安装MySQL5.6
1.检查Linux系统中是否已安装 MySQL rpm -qa | grep mysql 返回空值的话,就说明没有安装 MySQL 注意:在新版本的CentOS7中,默认的数据库已更新为了Mariad ...
- 【JDK】JDK源码分析-ReentrantLock
概述 在 JDK 1.5 以前,锁的实现只能用 synchronized 关键字:1.5 开始提供了 ReentrantLock,它是 API 层面的锁.先看下 ReentrantLock 的类签名以 ...
- PythonDay04
## 第四章 ### 今日内容 - 列表- 元组- range ### 列表 列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据,是一种可变的数据类型 64位python的限制是 11 ...
- 【C++】string::substr函数
形式:s.substr(p, n) 返回一个string,包含字符串s中从p开始的n个字符的拷贝(p的默认值是0,n的默认值是s.size() - p,即不加参数会默认拷贝整个s) int main( ...
- 一文速览Vue全栈
一文速览Vue全栈 原创: 新哥Lewis 天道酬勤Lewis 7月7日 Vue 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用,专注于声明式渲染视图 ...
- if else 深度优化
一. if else表达式过于复杂 if ((condition1 && condition2 ) || ((condition2 || condition3) && ...
- Unity进阶之ET网络游戏开发框架 01-下载、运行
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- springboot+支付宝条码支付开发详解
背景:项目原有乐刷聚合支付,无法参加支付宝.微信等支付机构的官方活动 需求:增加原生支付(支付宝条码支付) 方法: 一.官方文档:https://docs.open.alipay.com/194/10 ...
- Django Mysql数据库-聚合查询与分组查询
一.聚合查询与分组查询(很重要!!!) 聚合查询:aggregate(*args, **kwargs),只对一个组进行聚合 from django.db.models import Avg,Sum,C ...