吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习AdaBoost算法回归模型
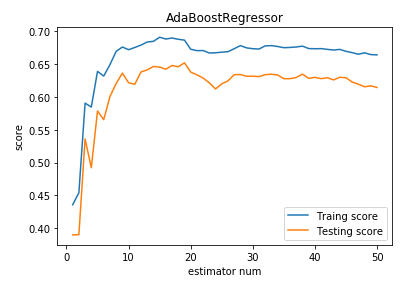
def test_AdaBoostRegressor(*data):
'''
测试 AdaBoostRegressor 的用法,绘制 AdaBoostRegressor 的预测性能随基础回归器数量的影响
'''
X_train,X_test,y_train,y_test=data
regr=ensemble.AdaBoostRegressor()
regr.fit(X_train,y_train)
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
estimators_num=len(regr.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(regr.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostRegressor")
plt.show() # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_AdaBoostRegressor
test_AdaBoostRegressor(X_train,X_test,y_train,y_test)
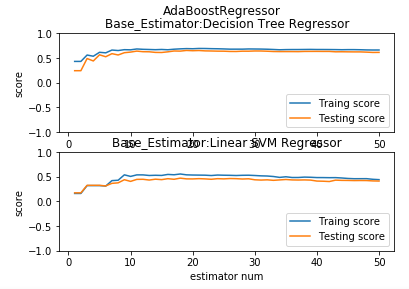
def test_AdaBoostRegressor_base_regr(*data):
'''
测试 AdaBoostRegressor 的预测性能随基础回归器数量的和基础回归器类型的影响
'''
from sklearn.svm import LinearSVR X_train,X_test,y_train,y_test=data
fig=plt.figure()
regrs=[ensemble.AdaBoostRegressor(), # 基础回归器为默认类型
ensemble.AdaBoostRegressor(base_estimator=LinearSVR(epsilon=0.01,C=100))] # 基础回归器为 LinearSVR
labels=["Decision Tree Regressor","Linear SVM Regressor"]
for i ,regr in enumerate(regrs):
ax=fig.add_subplot(2,1,i+1)
regr.fit(X_train,y_train)
## 绘图
estimators_num=len(regr.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(regr.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1)
ax.set_title("Base_Estimator:%s"%labels[i])
plt.suptitle("AdaBoostRegressor")
plt.show() # 调用 test_AdaBoostRegressor_base_regr
test_AdaBoostRegressor_base_regr(X_train,X_test,y_train,y_test)
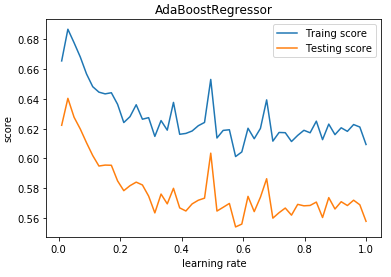
def test_AdaBoostRegressor_learning_rate(*data):
'''
测试 AdaBoostRegressor 的预测性能随学习率的影响
'''
X_train,X_test,y_train,y_test=data
learning_rates=np.linspace(0.01,1)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
traing_scores=[]
testing_scores=[]
for learning_rate in learning_rates:
regr=ensemble.AdaBoostRegressor(learning_rate=learning_rate,n_estimators=500)
regr.fit(X_train,y_train)
traing_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(learning_rates,traing_scores,label="Traing score")
ax.plot(learning_rates,testing_scores,label="Testing score")
ax.set_xlabel("learning rate")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostRegressor")
plt.show() # 调用 test_AdaBoostRegressor_learning_rate
test_AdaBoostRegressor_learning_rate(X_train,X_test,y_train,y_test)
def test_AdaBoostRegressor_loss(*data):
'''
测试 AdaBoostRegressor 的预测性能随损失函数类型的影响
'''
X_train,X_test,y_train,y_test=data
losses=['linear','square','exponential']
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
for i ,loss in enumerate(losses):
regr=ensemble.AdaBoostRegressor(loss=loss,n_estimators=30)
regr.fit(X_train,y_train)
## 绘图
estimators_num=len(regr.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label="Traing score:loss=%s"%loss)
ax.plot(list(X),list(regr.staged_score(X_test,y_test)),label="Testing score:loss=%s"%loss)
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1)
plt.suptitle("AdaBoostRegressor")
plt.show() # 调用 test_AdaBoostRegressor_loss
test_AdaBoostRegressor_loss(X_train,X_test,y_train,y_test)

吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
随机推荐
- Dijkstra算法依据项目改进版,输出路径
package dijkstra; import java.util.ArrayList; public class Dijkstra { ; /*private static int[][] Gra ...
- 简单的登录验证小程序_python
一.要求 输入用户名密码,验证成功之后显示欢迎信息,输错三次后锁定. 程序: #!/usr/bin/env python# _*_ coding:utf-8 _*_#Author:chenxz #将黑 ...
- [CF859C] Pie Rules - dp,博弈论
有一个长度为n的序列,Alice和Bob在玩游戏.Bob先手掌握决策权. 他们从左向右扫整个序列,在任意时刻,拥有决策权的人有如下两个选择: 将当前的数加到自己的得分中,并将决策权给对方,对方将获得下 ...
- Wannafly Camp 2020 Day 5A Alternative Accounts
There are n different accounts on the website, and some of them competed in the recent k contests. H ...
- nginx 启动报错找不到nginx.pid文件
这个问题的出现应该是系统找不到nginx的配置文件nginx.conf,所以,我们要告诉系统配置文件的位置:' --- 使用nginx -c /usr/local/nginx/conf/nginx.c ...
- python面试的100题(19)
61.如何在function里面设置一个全局变量 Python中有局部变量和全局变量,当局部变量名字和全局变量名字重复时,局部变量会覆盖掉全局变量. 如果要给全局变量在一个函数里赋值,必须使用glob ...
- 835. 字符串统计(Trie树模板题)
维护一个字符串集合,支持两种操作: “I x”向集合中插入一个字符串x: “Q x”询问一个字符串在集合中出现了多少次. 共有N个操作,输入的字符串总长度不超过 105105,字符串仅包含小写英文字母 ...
- day01_2spring3
Bean基于XML和基于注解的装配 一.Bean基于XML的装配 1.生命周期接着day01_1来讲(了解) Bean生命周期的如图所示:用红色框起来的都是我们要研究的! 如图Bean is Read ...
- os.getcwd()和os.path.realpath(__file__)的区别
https://blog.csdn.net/xiaminli/article/details/74944580 python中split().os.path.split()函数用法
- 部署prerender服务器
// 安装 git sudo apt-get install git sudo apt-get install curl // 请先确认服务器是否安装了curl 如果已经安装跳过即可 // 安装 no ...