吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1、下载MongoDB
官网下载:https://www.mongodb.com/download-center#community
上面这张图选择第二个按钮
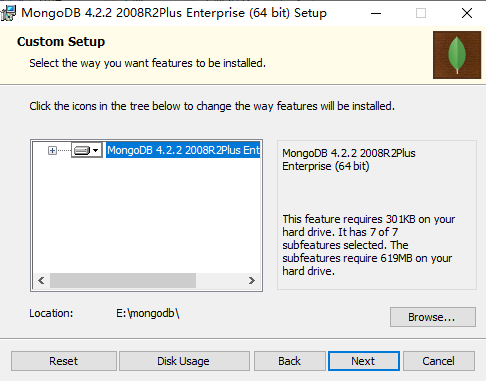
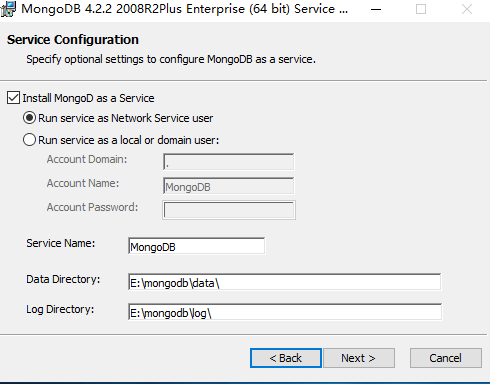
上面这张图直接Next
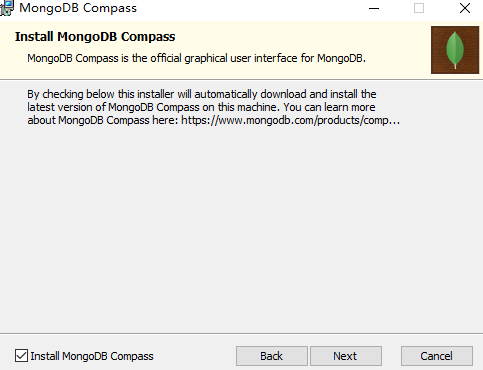
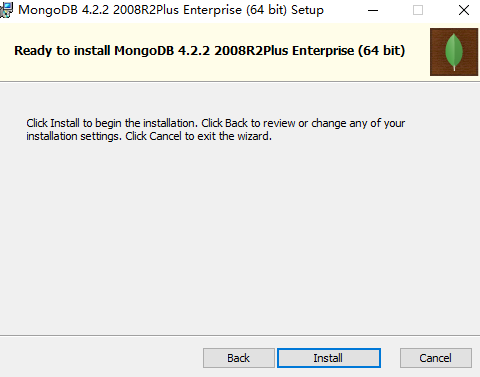
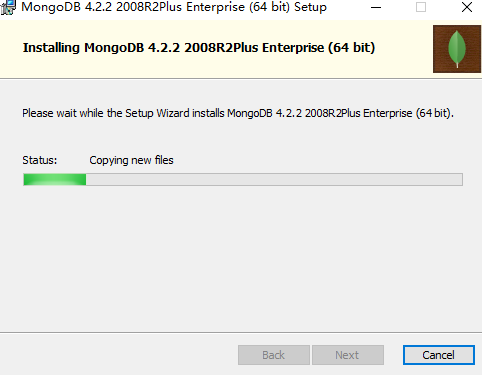

把bin路径添加到path中,如下图:
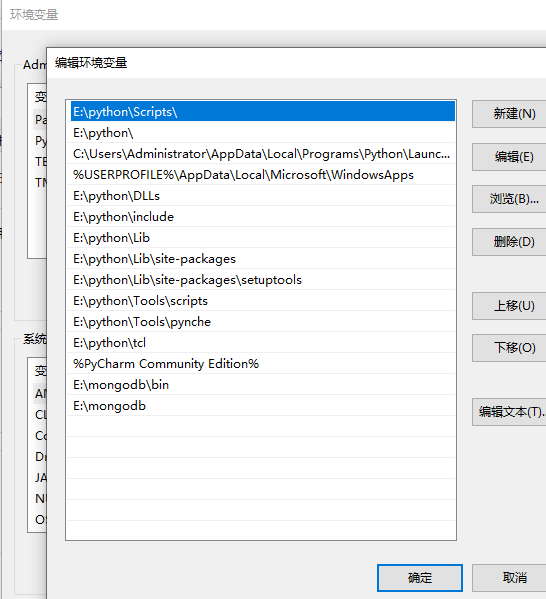
在安装路径下自己创建一个文件mongo.conf,配置内容如下:
#数据库路径
dbpath=E:\mongodb\data
#日志输出文件路径
logpath=E:\mongodb\log\mongo.log
#错误日志采用追加模式
logappend=true
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试请使用设置为false
quiet=true
#端口号默认为27017
port=27017

启动MongoDB服务
打开cmd命令行护着用Windows+R键打开,输入cmd
进入mongo安装路径的bin目录下
输入如下命令启动MongoDB:mongod --dbpath "E:\mongodb\data"
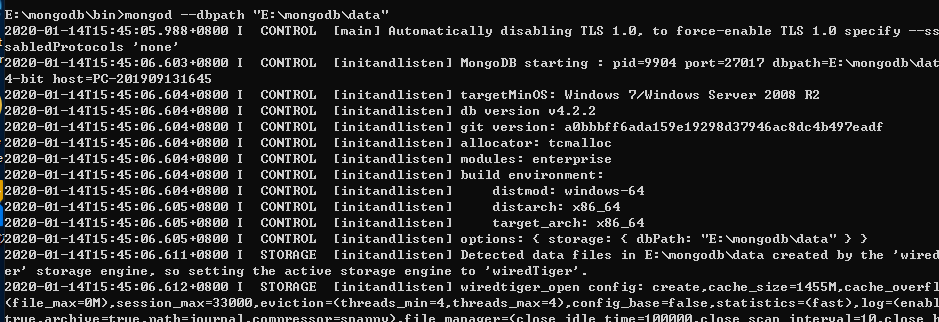
当你点击回车的时候,出现上面界面,说明已经成功了。
配置本地windows mongodb 服务
这样可设置为 开机自启动,可直接手动启动关闭,可通过命令行net start MongoDB 启动。该配置会大大方便。也不要在进入bin的目录下启动了
在mongodb新建配置文件mongo.config,这个是和bin目录同级的,该配置文件内容在上面可以找到。
用管理员身份打开cmd,左上角会出现管理员三个字,然后一次进入你的bin的目录下G:\mongodb\bin,这个一定要有管理员的身份去打开,否则执行下面命令会一直报错
输入:mongod --dbpath "E:\mongodb\data" --logpath "E:\mongodb\log\mongo.log" --install --serviceName "MongoDB"
如果输入次命令出现错误的话,先删除服务sc delete MongoDB,再次输入上个命令就好了
这样的话,mongodb服务Windows已经配置好了,我们可以不用进入bin的目录下启动MongoDB了

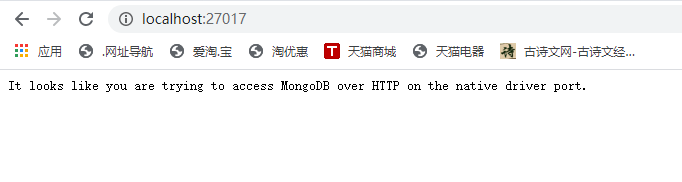
在浏览器输入http://localhost:27017,如果在浏览器中出现下面一段英文说明成功了
接下来在pycharm安装mongo plugo

安装好后重启IDE
重启后在右边能看到
创建一个mongo server
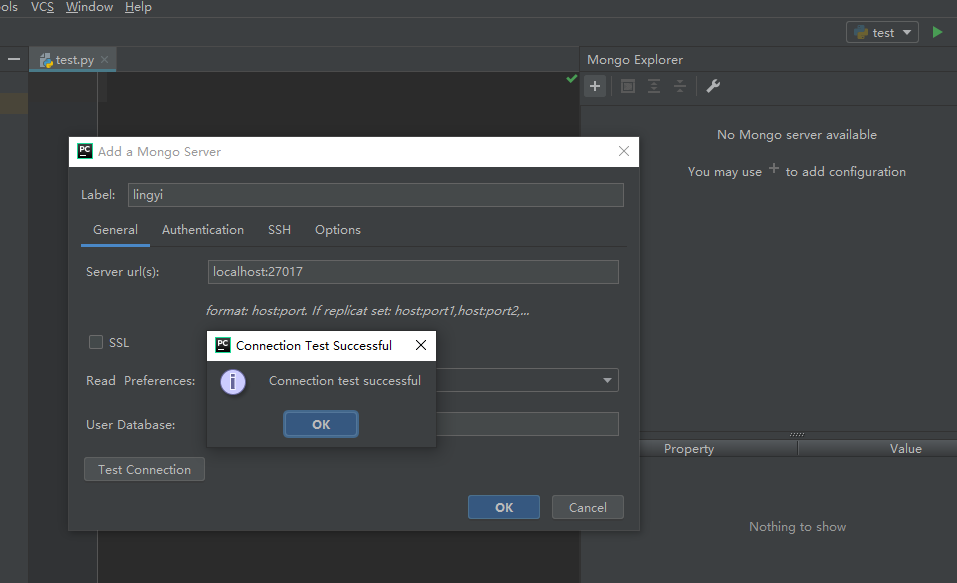
测试连接成功,点击OK保存设置就可以了。

下面这段代码将爬取到的天气数据放到MongoDB中。
import time
import pymongo
import requests client = pymongo.MongoClient('localhost',27017)
#在MongoDB中新建名为weather的数据库
book_weather = client['weather']
#在weather库中创建名为sheet_weather_3的表
sheet_weather = book_weather['sheet_weather_3'] #爬取天气数据
url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
response.encoding='utf8'
data = response.text
data_1 = data.split('\n')
#去除前三行不要的数据
for i in range(3):
data_1.remove(data_1[0]) temp = 1
for item in data_1:
url = 'https://free-api.heweather.net/s6/weather/forecast?location='+item[1:13]+'&key=232ab5d4b88e46bcb8bd8c06d49ebf91'
strhtml = requests.get(url)
time.sleep(3)
dic = strhtml.json()
if(temp>3):
#向sheet_weather_3表写入当前这条数据
sheet_weather.insert_one(dic)else:
temp+=1
运行代码


可以看到:爬取到的数据都以json的格式保存到mongodb数据库了。
接下来查询Mongodb数据库。代码如下:
import pymongo
client = pymongo.MongoClient('localhost',27017)
book_weather = client['weather']
sheet_weather = book_weather['sheet_weather_3']
#查找HeWeather6.basic.admin_area值为北京的数据。
for item in sheet_weather.find({'HeWeather6.basic.admin_area':'北京'}):
print(item)

接下来查询最大气温大于0度的城市名称。代码如下:
import pymongo
client = pymongo.MongoClient('localhost',27017)
book_weather = client['weather']
sheet_weather = book_weather['sheet_weather_3']
for item in sheet_weather.find():
#因为数据是预测3天的,因此这里需要循环3此
for i in range(3):
#取出最大气温值
tmp_max = item['HeWeather6'][0]['daily_forecast'][i]['tmp_max']
#使用update方法,将表中最低气温数据修改数据值
sheet_weather.update_one({'_id':item['_id']},{'$set':{'HeWeather6.0.daily_forecast.{}.tmp_max'.format(i):int(tmp_max)}})
#找出最高气温不小于0度的城市
for item in sheet_weather.find({'HeWeather6.daily_forecast.tmp_max':{'$gte':0}}):
print(item['HeWeather6'][0]['basic']['admin_area'])
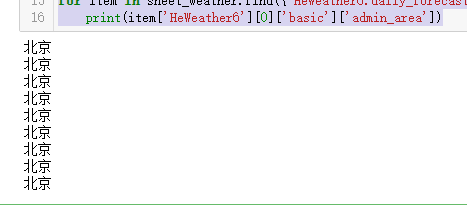
可以看出北京这几天的天气最高气温都是大于零度的。
mongodb中比较符:
小于:$lt
小于等于:$lte
大于:$gt
大于等于:$gte
吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/' strhtml = requests.get(url) print(strhtml.text) URL='h ...
- 吴裕雄--天生自然python学习笔记:pandas模块读取 Data Frame 数据
读取行数据 读取一个列数据的语法为: 例如,读取所有学生自然科目的成绩 : import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56 ...
- 吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB
本博文使用的数据库是MySQL和MongoDB数据库.安装MySQL可以参照我的这篇博文:https://www.cnblogs.com/tszr/p/12112777.html 其中操作Mysql使 ...
随机推荐
- Java方法升级
1. 方法格式 package cn.itcast.day04.demo02; /* 方法其实就是若干语句的功能集合. 方法好比是一个工厂. 蒙牛工厂 原料:奶牛.饲料.水 产出物:奶制品 钢铁工厂 ...
- java处理节假日和工作时间的工具类
import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.ArrayList; impo ...
- IIS 部署 web service
1.在控制台检查 IIS 功能是否已经全部启用 2.重新注册IIS 3.设定程序池的正确版本
- SpringBoot2.x整合Shiro出现cors跨域问题(踩坑记录)
1. Springboot如何跨域? 最简单的方法是: 定义一个配置CorsConfig类即可(是不是简单且无耦合到令人发指) @Configuration public class CorsConf ...
- 20141110的alltosun面试
今天周一,是校招的第一天,心情有点紧张,不过可以和很多同学一起去,是我紧张的心情变得稍微安静些.面试进行的时候,是学长2哥面的我,总体感觉自己的表现很糟糕,在公共场合发表言论或者演讲,一直是我的一个弱 ...
- PyQt5程序基本结构分析
面向过程版 # 0. 导入需要的包和模块 from PyQt5.Qt import * # 包含了我们常用的QT中的一些类 import sys # 一个内置的模块,系统相关操作 # 代码执行的时候, ...
- Java语言特性、加载与执行
[开源.免费.纯面向对象.跨平台] 简单性: 相对而言,例如,Java是不支持多继承的,C++是支持多继承的,多继承比较复杂:C++ 有指针,Java屏蔽了指针的概念.所以相对来说Java是简单的. ...
- c++ 查重+排序函数
输入 第一行n.第二行有n个元素. 输出 查重排序后的元素 样例: 输入: 5 1 1 2 3 4 输出: 1 2 3 4 unique的作用是“去掉”容器中相邻元素的重复元素 注意:用unique只 ...
- 开关机安全控制!(设置进入bois的密码)
1.调整 BOIS 引导设置(1)将第一引导设备设为当前系统所在硬盘 (2)设置管理员密码 (3)进入bois后如图所示需输入bols密码才能登入
- linux-命令行快捷方式使用
CTRL+P 命令向上翻滚 CTRL+N 命令向下翻滚 CTRL+U 命令行中删除光标前面的所有字符 CTRL+D 命令行中删除光标后面的一个字符 CTRL+H 命令行中删除光标前面的一个字符 CT ...