C++ 提取网页内容系列之五 整合爬取豆瓣读书
工作太忙 没有时间细化了 就说说 主要内容吧
下载和分析漫画是分开的
下载豆瓣漫画页面是使用之前的文章的代码
见http://www.cnblogs.com/itdef/p/4171179.html
http://www.cnblogs.com/itdef/p/4081963.html
注意 豆瓣网是https
下载后进行页面分析
fstream fs(szfileName);
stringstream ss; // 创建字符串流对象
ss << fs.rdbuf(); // 把文件流中的字符输入到字符串流中
fs.close();
string str = ss.str(); // 获取流中的字符串
页面不大 载入到string中 如果是UTF8 还需要进行GBK到UTF8的转换
然后使用正则 摘出每个漫画索引信息 存入vector<string>
string strRegex = "<li class=\"subject-item\">.*?</li>";
vector<string> vstr;
regex regExpress(strRegex);
smatch ms;
try {
while (regex_search(strText, ms, regExpress))
{
for (string::size_type i = 0; i < ms.size(); ++i)
{
vstr.push_back(ms.str(i));
}
strText = ms.suffix().str();
}
}
catch (exception& e)
{
cerr << e.what() << endl;
return vstr;
}
然后在对每本书的信息进行分析 解析出 书本名 简介 评分等
由于这些信息都是有固定标签 用正则反而麻烦 所以使用的字符串查找
basic_string <char>::size_type keyWordStart = s.find("title=\"");
basic_string <char>::size_type keyWordEnd = s.find("\"", keyWordStart + sizeof("title=\"")-1);
if ((keyWordStart != string::npos) && (keyWordEnd != string::npos) && (keyWordEnd > keyWordStart))
{
string strKeyWord = s.substr(keyWordStart+ sizeof("title=\"") - 1, keyWordEnd - keyWordStart- sizeof("title=\"")+1);
cout << strKeyWord << endl;
}
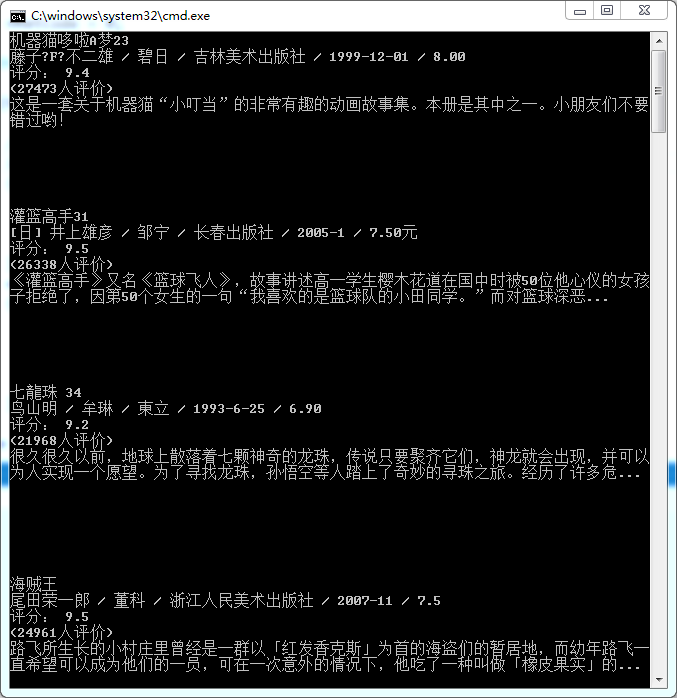
最后结果如图
C++ 提取网页内容系列之五 整合爬取豆瓣读书的更多相关文章
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- Python爬虫爬取豆瓣读书
一,准备工作. 工具:win10+Python3.6 爬取目标:爬取图中红色方框的内容. 原则:能在源码中看到的信息都能爬取出来. 信息表现方式:CSV转Excel. 二,具体步骤. 先给出具体代码吧 ...
- scrapy框架爬取豆瓣读书(1)
1.scrapy框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- python实例:自动爬取豆瓣读书短评,分析短评内容
思路: 1.打开书本“更多”短评,复制链接 2.脚本分析链接,通过获取短评数,计算出页码数 3.通过页码数,循环爬取当页短评 4.短评写入到txt文本 5.读取txt文本,处理文本,输出出现频率最高的 ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
随机推荐
- 用git,clone依赖的库
git clone https://github.com/influxdata/influxdb-java.git cd crfasrnn git submodule update --init -- ...
- Flask--(一对多demo)作者书籍模型
一对多模型的增加和删除 后端实现: from flask import Flask from flask import flash from flask import redirect from fl ...
- Delphi 10-10.2.2启动提示JS错误的解决办法
HKEY_CURRENT_USER\SOFTWARE\Embarcadero\BDS\18.0\Known IDE Packages\ $(BDS)\Bin\CommunityToolbar240.b ...
- python 前后端分离 简单的数据库返回接口
1.使用node http-server 起本地服务器 或者打开nginx 直接用nginx的默认页面也可以 (用下面的html文件替换nginx下html文件夹下的index.html) http ...
- jQuery解决IE6/7/8不能使用 JSON.stringify 函数的问题
原文地址:http://www.ynpxrz.com/n1445665c2023.aspx JSON 对象是在 ECMAScript 第 5 版中实现的,此版于 2009 年 12 月发布:IE6 I ...
- 一台电脑上配置多个tomcat同时运行
好使 1 1.配置运行tomcat 首先要配置java的jdk环境,这个就不在写了 不懂去网上查查,这里主要介绍再jdk环境没配置好的情况下 如何配置运行多个tomcat 2.第一个tomcat: ...
- Metasploit 简单渗透应用
1.Metasploit端口扫描: 在终端输入msfconsole或直接从应用选metasploit 进入msf>nmap -v -sV 192.168.126.128 与nmap结果一样 用 ...
- Alsa aplay S8 U8 S16_LE S16_BE U16_LE U16_BE格式
举个例子 aplay -r 16000 -f S16_LE -D hw:0,0 -c 2 -d 3 ~/Private/Private_Tools/02_ALSA_Learning/left_1k_r ...
- Node Express服务器设置与优化
一.代码部分 * 启用gzip压缩,减少网络数据量 var compression = require('compression')var express = require('express')va ...
- shell脚本(一)
shell脚本(一) 定义:脚本就是一条条命令的堆积.常见脚本有:js asp,jsp,php,python Shell特点:简单易用高效 Shell分类:图形界面(gui shell) 命令行界面 ...