CSDN这么公然爬取(piao qie)cnblogs的文章,给钱了吗?
在CSDN网站经常看到有博客转载cnblogs的文章,开始还以为是网友自行转载,后来才发现,这些所谓的转载应该都是机器爬取(piao qie)过去的。不知道cnblogs对此怎么看。
下面看看几个示例
博主发博客的时间比它注册博客的时间还早,而且转载的时间和原稿发布时间分秒不差。

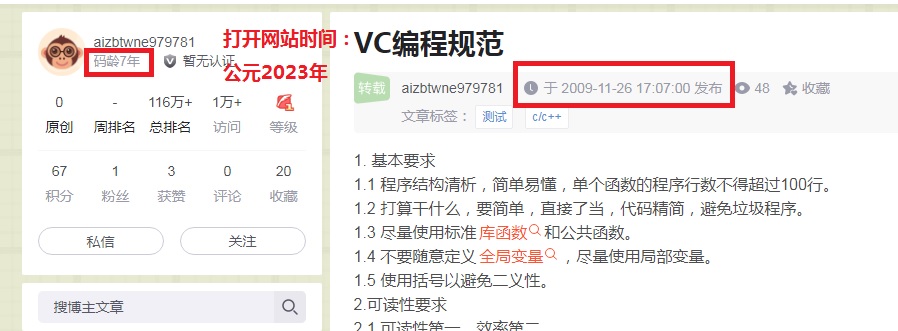
这爬取也太直白了吧,马脚也不藏一下,虽然你标记了转载。
这下我总算明白了,为什么CSDN明明是转的别人文章,标题那里却还是显示着“原创”。原因是,这些是真网友转载的,只是在文章后面注明了来源,并没有申明原创或者转载;但上面那些机器爬取的文章,则显示在标题处申明为转载。
下面再放几个对比文章
CSDN爬取的文章 https://blog.csdn.net/aizbtwne979781/article/details/101130277

cnblogs的文章 https://www.cnblogs.com/afarmer/archive/2011/12/09/2282719.html

这样的结果是,很多问题百度出来都是csdn的结果,其实文章都是来源于cnblogs。博客园你不觉得亏吗?CSDN你不觉得无耻吗?
不过在bing搜索时,一般优先显示cnblogs的内容。
CSDN这么公然爬取(piao qie)cnblogs的文章,给钱了吗?的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Scrapy爬取伯乐在线的所有文章
本篇文章将从搭建虚拟环境开始,爬取伯乐在线上的所有文章的数据. 搭建虚拟环境之前需要配置环境变量,该环境变量的变量值为虚拟环境的存放目录 1. 配置环境变量 2.创建虚拟环境 用mkvirtualen ...
- 爬取博主的所有文章并保存为PDF文件
继续改进上一个项目,上次我们爬取了所有文章,但是保存为TXT文件,查看不方便,而且还无法保存文章中的代码和图片. 所以这次保存为PDF文件,方便查看. 需要的工具: 1.wkhtmltopdf安装包, ...
- python:爬取博主的所有文章的链接、标题和内容
以爬取我自己的博客为例:https://www.cnblogs.com/Mr-choa/ 1.获取所有的文章的链接: 博客文章总共占两页,比如打开第一页:https://www.cnblogs.com ...
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- Python递归爬取头条用户的所有文章、视频
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- 记一次python写爬虫爬取学校官网的文章
有一位老师想要把官网上有关数字化的文章全部下载下来,于是找到我,使用python来达到目的 首先先查看了文章的网址 获取了网页的源代码发现一个问题,源代码里面没有url,这里的话就需要用到抓包了,因为 ...
- scrapy爬取简书整站文章
在这里我们使用CrawlSpider爬虫模板, 通过其过滤规则进行抓取, 并将抓取后的结果存入mysql中,下面直接上代码: jianshu_spider.py # -*- coding: utf-8 ...
- 一文搞定scrapy爬取众多知名技术博客文章保存到本地数据库,包含:cnblog、csdn、51cto、itpub、jobbole、oschina等
本文旨在通过爬取一系列博客网站技术文章的实践,介绍一下scrapy这个python语言中强大的整站爬虫框架的使用.各位童鞋可不要用来干坏事哦,这些技术博客平台也是为了让我们大家更方便的交流.学习.提高 ...
- scrapy爬取cnblogs文章列表
scrapy爬取cnblogs文章 目标任务 安装爬虫 创建爬虫 编写 items.py 编写 spiders/cnblogs.py 编写 pipelines.py 编写 settings.py 运行 ...
随机推荐
- Linux命令行与shell脚本编程(1)--读书笔记
这里记录下个人读书笔记,持续更新中(作者小白,大佬轻喷... chap7 理解Linux文件权限 7.1 Linux安全性 Linux系统的每个用户账户都有唯一的用户ID,即UID,用户权限根据UID ...
- 【Redis】-使用Lua脚本解决多线程下的超卖问题以及为什么?
一.多线程下引起的超卖问题呈现1.1.我先初始化库存数量为1.订单数量为0 1.2.开启3个线程去执行业务 业务为:判断如果说库存数量大于0,则库存减1,订单数量加1 结果为:库存为-2,订单数量为3 ...
- 小米商城主页展示HTML+CSS
大佬们呀,花了好几天的时间总算是看着页面展示可以了,求赐教! 小米商城主页,对大佬来说肯定简单爆了,我抄写了好久呀,总是有一点点的小问题,还搞不明白 主要是一个静态的小米商城页面,HTML前端代码不复 ...
- java解决中文乱码的几种写法
工作中总会遇到中文乱码问题,以导出文件,文件名称是中文的话,下载下来的文件名称会乱码问题,总结了几种解决文件名乱码的写法,仅供参考. 首先定义一个汉语字符串 String zhName = " ...
- ABP - 缓存模块(1)
1. 与 .NET Core 缓存的关系和差异 ABP 框架中的缓存系统核心包是 Volo.Abp.Caching ,而对于分布式缓存的支持,abp 官方提供了基于 Redis 的方案,需要安装 Vo ...
- Linux 下 R 源码安装指南
本文章同步自作者的语雀知识库,请点击这里阅读原文. 如果你使用的 Linux 系统 GCC 版本太低, 又没有 root 权限 (即使有 root 权限又担心升级 GCC 带来的风险) ; 同时你又不 ...
- 图解三代测序(SMRT Sequencing)
目前主流三代测序平台除了Oxford 家的 Nanopore,还有 Pacific Biosciences(简称 PacBio)公司的 Single Molecule Real-Time(SMRT)S ...
- Galaxy Project 是一个由 NIH、NSF、Johns Hopkins University 等机构支持的开源生物医学开源项目。Galaxy 作为其中的一个子项目,提供了以英文为主,......
本文分享自微信公众号 - 生信科技爱好者(bioitee).如有侵权,请联系 support@oschina.cn 删除.本文参与"OSC源创计划",欢迎正在阅读的你也加入,一起分 ...
- Microsoft R 和 Open Source R,哪一个才最适合你?
由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访问文中链接. R 是一个开源统计软件,在分析领域普及的非常快. 在过去几年中,无论业务规模如何,很多公司都采 ...
- 基于 Dash Bio 的生物信息学数据可视化
Dash 是用于搭建响应式 Web 应用的 Python 开源库.Dash Bio 是面向生物信息学,且与 Dash 兼容的组件,它可以将生物信息学领域中常见的数据整合到 Dash 应用程序,以实现响 ...